Key focus: Understand the basics of estimation theory with a simple example in communication systems. Know how to assess the performance of an estimator.
A simple estimation problem : DSB-AM receiver
In Double Side Band – Amplitude Modulation (DSB-AM), the desired message is amplitude modulated over a carrier of frequency f0. The following discussion is with reference to the figure 1. In the frequency domain, the spectrum of the message signal, which is a baseband signal, may look like the one shown in (a). After the modulation over a carrier frequency of f0, the spectrum of the modulated signal will look like as shown in (b). The modulated signal has spectral components centered at f0 and -f0.

The modulated signal is a function of three factors :
1) actual message – m(t)
2) carrier frequency – f0
3) phase uncertainty – Φ0
The modulated signal can be expressed as,

To simplify things, let’s consider that the modulated signal is passed via an ideal channel (no impairments added by the channel, so we can do away with channel equalization and other complex stuffs in the receiver). The modulated signal hits the antenna located at front end of our DSBC receiver. Usually the receiver front end is employed with a band-pass filter and amplifier to put the received signal in the desired band of operation & level, as expected by the receiver. The electronics in the front end receiver adds noise to the incoming signal (modeled as white noise – w(t) ). The signal after the BPF and amplifier combination is expressed as x(t), which is a combination of our desired signal s(t) and the front end noise w(t). Thus x(t) can be expressed as
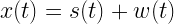
The signal x(t) is band-pass (centered around the carrier frequency f0). To bring x(t) back to the baseband, a mixer is employed that multiplies x(t) with a tone centered at f0 (generated by a local oscillator). Actually a low pass filter is usually employed after the mixer, for extracting the desired signal at the baseband.
As the receiver has no knowledge about the carrier frequency, there must exist a technique/method to extract this information from the incoming signal x(t) itself. Not only the carrier frequency (f0) but also the phase Φ0 of the carrier need to be known at the receiver for proper demodulation. This leads us to the problem of “estimation”.
Estimation of unknown parameters
In “estimation” problem, we are confronted with estimating one or more unknown parameters based on a sequence of observed data. In our problem, the signal x(t) is the observed data and the parameters that are to be estimated are f0 and Φ0 .
Now, we add an estimation algorithm at the receiver, that takes in the signal x(t) and computes estimates of f0 and Φ0.The estimated values are denoted with a cap on their respective letters.The estimation algorithm can be simply stated as follows
Given 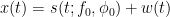 , estimate
, estimate  and
and 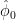 that are optimal in some sense.
that are optimal in some sense.
Since the noise w(t) is assumed to be “white”, the probability density function (PDF) of the noise is readily available at the receiver.
So far, all the notations were expressed in continuous domain. To simplify calculations, let’s state the estimation problem in discrete time domain. In discrete time domain, the samples of observed signal – which is a combination of actual signal and noise is expressed As
![x[n] = s[n;f_0, \phi_0] + w[n]](https://s0.wp.com/latex.php?latex=x%5Bn%5D+%3D+s%5Bn%3Bf_0%2C+%5Cphi_0%5D+%2B+w%5Bn%5D+&bg=ffffff&fg=000&s=2&c=20201002)
The noise samples w[n] is a random variable, that randomizes every time we observe x[n]. Each time when we observe the “observed” samples – x[n] , we think of it as having the same “actual” signal samples – s[n] but with different realizations of the noise samples w[n]. Thus w[n] can be modeled as a Random Variable (RV). Since the underlying noise w[n] is a random variable, the estimates and that result from the estimation are also random variables.
Now the estimation algorithm can be stated as follows:
Given the observed data samples – x[n] = ( x[0], x[1],x[2], … ,x[N-1] ), our goal is to find estimator functions that maps the given data into estimates.
![\hat{f}_{0}=g_{1}(x[0], x[1],x[2],\cdots,x[N-1])=g_{1} \left( \textbf{x} \right)](https://s0.wp.com/latex.php?latex=%5Chat%7Bf%7D_%7B0%7D%3Dg_%7B1%7D%28x%5B0%5D%2C+x%5B1%5D%2Cx%5B2%5D%2C%5Ccdots%2Cx%5BN-1%5D%29%3Dg_%7B1%7D+%5Cleft%28+%5Ctextbf%7Bx%7D+%5Cright%29+&bg=ffffff&fg=000&s=2&c=20201002)
![\hat{\phi}_{0} = g_{2} (x[0], x[1], x[2], \cdots, x[N-1]) = g_{2} \left( \textbf{x} \right)](https://s0.wp.com/latex.php?latex=%5Chat%7B%5Cphi%7D_%7B0%7D+%3D+g_%7B2%7D+%28x%5B0%5D%2C+x%5B1%5D%2C+x%5B2%5D%2C+%5Ccdots%2C+x%5BN-1%5D%29+%3D+g_%7B2%7D+%5Cleft%28+%5Ctextbf%7Bx%7D+%5Cright%29+&bg=ffffff&fg=000&s=2&c=20201002)
Assessing the performance of the estimation algorithm
Since the estimates and are random variables, they can be described by a probability density function (PDF). The PDF of the estimates depend on following factors :
1. Structure of s[n]
2. Probability model of w[n]
3. Form of estimation function g(x)
For example, the PDF of the estimate may take the following shape,

The goal of the estimation algorithm is to give an estimate that is unbiased (mean of the estimate is equal to the actual f0) and has minimum variance. This criteria can be expressed as,
![\begin{aligned} E\left\{\hat{f}_0 \right\} &= f_0 \\ \sigma^{2}_{\hat{f}_0} &= E \left\{ \left( \hat{f}_0 - E [ \hat{f}_0] \right)^2 \right\} \quad \text{should be minimum} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+E%5Cleft%5C%7B%5Chat%7Bf%7D_0+%5Cright%5C%7D+%26%3D+f_0+%5C%5C+%5Csigma%5E%7B2%7D_%7B%5Chat%7Bf%7D_0%7D+%26%3D+E+%5Cleft%5C%7B+%5Cleft%28+%5Chat%7Bf%7D_0+-+E+%5B+%5Chat%7Bf%7D_0%5D+%5Cright%29%5E2+%5Cright%5C%7D+%5Cquad+%5Ctext%7Bshould+be+minimum%7D+%5Cend%7Baligned%7D+&bg=ffffff&fg=000&s=2&c=20201002)
Same type of argument will hold for the other estimate :
By these criteria one can assess the performance of an estimator. The estimator described above (with the criteria) is called “Minimum Variance Unbiased Estimator” (MVUE).
Rate this article: 
 (15 votes, average: 4.07 out of 5)
(15 votes, average: 4.07 out of 5)
Similar topics
Books by the author
 Wireless Communication Systems in Matlab Second Edition(PDF)  (169 votes, average: 3.70 out of 5) (169 votes, average: 3.70 out of 5) |  Digital Modulations using Python (PDF ebook) (125 votes, average: 3.61 out of 5) |  Digital Modulations using Matlab (PDF ebook) (130 votes, average: 3.68 out of 5) |
| Hand-picked Best books on Communication Engineering Best books on Signal Processing |
||