Key focus: Applying Cramér-Rao Lower Bound (CRLB) for vector parameter estimation. Know about covariance matrix, Fisher information matrix & CRLB matrix.
CRLB for Vector Parameter Estimation
CRLB for scalar parameter estimation was discussed in previous posts. The same concept is extended to vector parameter estimation.
Consider a set of deterministic parameters ![\mathbb{\theta}=[ \theta_1, \theta_2, ..., \theta_p]^{T}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7B%5Ctheta%7D%3D%5B+%5Ctheta_1%2C+%5Ctheta_2%2C+...%2C+%5Ctheta_p%5D%5E%7BT%7D+&bg=ffffff&fg=000&s=0&c=20201002) that we wish to estimate.
that we wish to estimate.
The estimate is denoted in vector form as, ![\mathbb{\hat{\theta}} = [ \hat{\theta_1}, \hat{\theta_2}, ..., \hat{\theta_p} ]^{T}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7B%5Chat%7B%5Ctheta%7D%7D+%3D+%5B+%5Chat%7B%5Ctheta_1%7D%2C+%5Chat%7B%5Ctheta_2%7D%2C+...%2C+%5Chat%7B%5Ctheta_p%7D+%5D%5E%7BT%7D&bg=ffffff&fg=000&s=0&c=20201002) .
.
Assume that the estimate is unbiased ![E[\hat{\theta}] = \theta](https://s0.wp.com/latex.php?latex=E%5B%5Chat%7B%5Ctheta%7D%5D+%3D+%5Ctheta+&bg=ffffff&fg=000&s=0&c=20201002) .
.
Covariance Matrix
For the scalar parameter estimation, the variance of the estimate was considered. For vector parameter estimation, the covariance of the vector of estimates are considered.
The covariance matrix for the vector of estimates is given by
![C_{\hat{\theta}} =var ( \hat{\theta} ) = E \left[ ( \hat{\theta} - \theta )( \hat{\theta} - \theta )^T \right]](https://s0.wp.com/latex.php?latex=C_%7B%5Chat%7B%5Ctheta%7D%7D+%3Dvar+%28+%5Chat%7B%5Ctheta%7D+%29+%C2%A0%3D+E+%5Cleft%5B+%C2%A0%28+%5Chat%7B%5Ctheta%7D+-+%5Ctheta+%29%28+%5Chat%7B%5Ctheta%7D+-+%5Ctheta+%29%5ET+%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)
For example, if 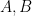 and C are the unknown parameters to be estimated, then the covariance matrix for the parameter vector
and C are the unknown parameters to be estimated, then the covariance matrix for the parameter vector ![\theta = [A,B,C] ^T](https://s0.wp.com/latex.php?latex=%5Ctheta+%3D+%5BA%2CB%2CC%5D+%5ET+&bg=ffffff&fg=000&s=0&c=20201002) is given by
is given by
![C_{\hat{\theta}} = \left[ \begin{matrix} var(\hat{A}) & cov(\hat{A},\hat{B}) & cov(\hat{A},\hat{C}) \\ cov(\hat{B},\hat{A}) & var(\hat{B}) & cov(\hat{B},\hat{C}) \\ cov(\hat{C},\hat{A}) & cov(\hat{C},\hat{B}) & var(\hat{C}) \end{matrix} \right]](https://s0.wp.com/latex.php?latex=C_%7B%5Chat%7B%5Ctheta%7D%7D+%3D+%5Cleft%5B+%C2%A0%5Cbegin%7Bmatrix%7D+var%28%5Chat%7BA%7D%29+%26+cov%28%5Chat%7BA%7D%2C%5Chat%7BB%7D%29+%26+cov%28%5Chat%7BA%7D%2C%5Chat%7BC%7D%29+%5C%5C+%C2%A0cov%28%5Chat%7BB%7D%2C%5Chat%7BA%7D%29+%26+var%28%5Chat%7BB%7D%29+%26+cov%28%5Chat%7BB%7D%2C%5Chat%7BC%7D%29+%5C%5C+%C2%A0cov%28%5Chat%7BC%7D%2C%5Chat%7BA%7D%29+%26+cov%28%5Chat%7BC%7D%2C%5Chat%7BB%7D%29+%26+var%28%5Chat%7BC%7D%29+%5Cend%7Bmatrix%7D+%5Cright%5D%C2%A0+&bg=ffffff&fg=000&s=1&c=20201002)
Fisher Information Matrix
For the scalar parameter estimation, Fisher Information was considered. Same concept is extended for the vector case and is called the Fisher Information Matrix  . The ijth element of the Fisher Information Matrix (evaluated at the true values of the parameter vector) is given by
. The ijth element of the Fisher Information Matrix (evaluated at the true values of the parameter vector) is given by
![[I(\theta)] _{ij} = \displaystyle{-E \left[ \frac{\delta^2}{\delta \theta_i \delta \theta_j} ln \; p(x;\theta) \right]} \; \; i,j =1,2,3,\cdots,p](https://s0.wp.com/latex.php?latex=%C2%A0%5BI%28%5Ctheta%29%5D+_%7Bij%7D+%3D+%5Cdisplaystyle%7B-E+%5Cleft%5B+%C2%A0%5Cfrac%7B%5Cdelta%5E2%7D%7B%5Cdelta+%5Ctheta_i+%5Cdelta+%5Ctheta_j%7D+ln+%5C%3B+p%28x%3B%5Ctheta%29+%5Cright%5D%7D%C2%A0+%5C%3B+%5C%3B+i%2Cj+%3D1%2C2%2C3%2C%5Ccdots%2Cp+&bg=ffffff&fg=000&s=1&c=20201002)
CRLB Matrix
Under the same regularity condition (as that of the scalar parameter estimation case),
![\displaystyle{E \left[ \frac{\delta}{ \delta \theta} ln\; p(x;\theta) \right] = 0} \;\;\; \forall \theta](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7BE+%5Cleft%5B+%5Cfrac%7B%5Cdelta%7D%7B+%5Cdelta+%5Ctheta%7D+ln%5C%3B+p%28x%3B%5Ctheta%29+%5Cright%5D+%3D+0%7D+%5C%3B%5C%3B%5C%3B+%5Cforall+%5Ctheta+&bg=ffffff&fg=000&s=1&c=20201002)
the CRLB Matrix is given by the inverse of the Fisher Information Matrix

Note: For the scale parameter estimation, the CRLB was shown to be the reciprocal of the Fisher Information.
This implies that the covariance of the parameters (diagonal elements) are bound by the CRLB as
![\left[ C_{(\hat{\theta})} \right]_{ii} \geq \left[ I^{-1}(\theta) \right]_{ii}](https://s0.wp.com/latex.php?latex=%C2%A0+%5Cleft%5B+C_%7B%28%5Chat%7B%5Ctheta%7D%29%7D+%5Cright%5D_%7Bii%7D+%5Cgeq+%C2%A0%5Cleft%5B+I%5E%7B-1%7D%28%5Ctheta%29+%5Cright%5D_%7Bii%7D%C2%A0+&bg=ffffff&fg=000&s=1&c=20201002)
More generally, the condition given above is represented as

Note: The word positive-semi-definite is the matrix equivalent of saying that a value is greater than or equal to zero. Similarly, the term positive-definite is roughly equivalent of saying that something is definitely greater than zero or definitely positive.
Emphasize was place on diagonal elements in the Fisher Information Matrix. The effect of off-diagonal elements should also be considered.
For further reading
Similar topics:
Books by the author:
 Wireless Communication Systems in Matlab Second Edition(PDF)    (168 votes, average: 3.71 out of 5) (168 votes, average: 3.71 out of 5) |  Digital Modulations using Python (PDF ebook) (124 votes, average: 3.60 out of 5) |  Digital Modulations using Matlab (PDF ebook) (129 votes, average: 3.71 out of 5) |
| Hand-picked Best books on Communication Engineering Best books on Signal Processing |
||
Hi I need to matlab code for it.please help me