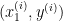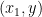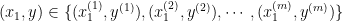Keywords: machine learning, topics, probability, statistics, linear algebra, data preprocessing, supervised learning, unsupervised learning, deep learning, reinforcement learning, model evaluation, cross-validation, hyperparameter tuning.
Why the buzz ?
Machine learning has been generating a lot of buzz in recent years due to its ability to automate tasks that were previously thought to be impossible or required human-level intelligence. Here are some reasons why there is so much buzz in machine learning:
- Improved Data Processing: Machine learning algorithms can process vast amounts of data quickly and accurately. With the advent of big data, there is now more data available than ever before, and machine learning algorithms can analyze this data to extract meaningful insights.
- Automation: Machine learning can automate tasks that were previously done by humans, such as image recognition, natural language processing, and even decision making. This has the potential to increase efficiency and reduce costs in many industries.
- Personalization: Machine learning can be used to personalize experiences for users. For example, recommendation systems can use machine learning algorithms to suggest products or services that are relevant to a user’s interests.
- Predictive Analytics: Machine learning can be used to make predictions about future events based on historical data. This is particularly useful in industries like finance, healthcare, and marketing.
- Advancements in Technology: Advancements in technology have made it easier to collect and store data, which has made it possible to train more complex machine learning models. Additionally, the availability of cloud computing has made it easier for companies to implement machine learning solutions.
Overall, the buzz in machine learning is due to its ability to automate tasks, process vast amounts of data, and make predictions about future events. As machine learning continues to evolve, it has the potential to transform many industries and change the way we live and work.
The most important topics to learn in machine learning
There are several important topics to learn in machine learning that are crucial for building effective machine learning models. Here are some of the most important topics to learn:
- Probability and Statistics: Probability and statistics are the foundation of machine learning. It is important to have a solid understanding of concepts like probability distributions, statistical inference, hypothesis testing, and Bayesian methods.
- Linear Algebra: Linear algebra is used extensively in machine learning algorithms, especially in deep learning. Topics like matrices, vectors, eigenvectors, and eigenvalues are important to understand.
- Data Preprocessing: Data preprocessing is the process of cleaning and transforming raw data into a format that can be used by machine learning algorithms. It includes tasks like feature scaling, feature selection, data normalization, and data augmentation.
- Supervised Learning: Supervised learning is a type of machine learning where the model learns from labeled data to make predictions or classifications on new, unseen data. This includes topics like regression, classification, decision trees, and support vector machines.
- Unsupervised Learning: Unsupervised learning is a type of machine learning where the model learns from unlabeled data to discover patterns and relationships in the data. This includes topics like clustering, dimensionality reduction, and anomaly detection.
- Deep Learning: Deep learning is a subset of machine learning that involves training artificial neural networks with multiple layers. It is used for tasks like image recognition, natural language processing, and speech recognition.
- Reinforcement Learning: Reinforcement learning is a type of machine learning where an agent learns to take actions in an environment to maximize a reward signal. It is used for tasks like game playing, robotics, and autonomous driving.
- Model Evaluation and Selection: Model evaluation and selection is the process of selecting the best machine learning model for a given task. It includes topics like cross-validation, bias-variance tradeoff, and hyperparameter tuning.
Overall, these are some of the most important topics to learn in machine learning. However, it is important to note that the field of machine learning is constantly evolving, and there may be new topics and techniques to learn in the future.