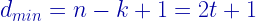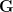Introduction:
A





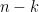



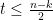


Block Interleavers:
Suppose, assume that the dominant error mechanism in a channel is of burst type. A burst of length b is defined as a string of b unreliable consecutive symbols. If the expected burst length, b is less than or equal to t (the number of correctable symbol errors by RS coding), the code can be used as it is. However, if bursts length

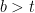
Let us assume that






Here, the data is written row by row and read back column by column.Consider now the effect of a burst error of length



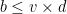



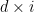





Design Example:
Consider a (255,235) Reed Solomon coding system. This code can correct upto

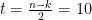

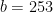




In this case , an interleaver depth of 26 is enough to combat the burst errors introduced by the channel. The block interleaver dimensions would be


Matlab Code:
A sample matlab code that simulates the above mentioned block interleaver design is given below. The input data is a repeatitive stream of following symbols – “THE_QUICK_BROWN_FOX_JUMPS_OVER_THE_LAZY_DOG_“. A (255,235) Reed Solomon decoder (with correction capability of 10 symbols) is used. We assume that the channel is expected to produce a maximum of consecutive 20 symbols of burst error. The burst errors are denoted by ‘*‘.
%Demonstration of design of Block Interleaver for Reed Solomon Code
%Author : Mathuranathan for https://www.gaussianwaves.com
%License - Creative Commons - cc-by-nc-sa 3.0
clc;
clear;
%____________________________________________
%Input Parameters
%____________________________________________
%Interleaver Design for Reed-Solomon Codes
%RS code parameters
n=255; %RS codeword length
k=235; %Number of data symbols
b=20; %Number of symbols that is expected to be corrupted by the channel
%____________________________________________
p=n-k; %Number of parity symbols
t=p/2; %Error correction capability of RS code
fprintf('Given (%d,%d) Reed Solomon code can correct : %d symbols \n',n,k,fix(t));
fprintf('Given - expected burst error length from the channel : %d symbols \n',b);
disp('____________________________________________________________________________');
if(b>t)
fprintf('Interleaving MAY help in this scenario\n');
else
fprintf('Interleaving will NOT help in this scenario\n');
end
disp('____________________________________________________________________________');
D=ceil(b/t)+1; %Intelever Depth
memory = zeros(D,n); %constructing block interleaver memory
data='THE_QUICK_BROWN_FOX_JUMPS_OVER_THE_LAZY_DOG_'; % A constant pattern used as a data
%If n>length(data) then repeat the pattern to construct a data of length 'n'
data=char([repmat(data,[1,fix(n/length(data))]),data(1:mod(n,length(data)))]);
%We sending D blocks of similar data
intlvrInput=repmat(data(1:n),[1 D]);
fprintf('Input Data to the Interleaver -> \n');
disp(char(intlvrInput));
disp('____________________________________________________________________________');
%INTERLEAVER
%Writing into the interleaver row-by-row
for index=1:D
memory(index,1:end)=intlvrInput((index-1)*n+1:index*n);
end
intlvrOutput=zeros(1,D*n);
%Reading from the interleaver column-by-column
for index=1:n
intlvrOutput((index-1)*D+1:index*D)=memory(:,index);
end
%Create b symbols error at 25th Symbol location for test in the interleaved output
%'*' means error in this case
intlvrOutput(1,25:24+b)=zeros(1,b)+42;
fprintf('\nInterleaver Output after being corrupted by %d symbol burst error - marked by ''*''->\n',b);
disp(char(intlvrOutput));
disp('____________________________________________________________________________');
%Deinteleaver
deintlvrOutput=zeros(1,D*n);
%Writing into the deinterleaver column-by-column
for index=1:n
memory(:,index)=intlvrOutput((index-1)*D+1:index*D)';
end
%Reading from the deinterleaver row-by-row
for index=1:D
deintlvrOnput((index-1)*n+1:index*n)=memory(index,1:end);
end
fprintf('Deinterleaver Output->\n');
disp(char(deintlvrOnput));
disp('____________________________________________________________________________');
Simulation Result:
Given : (255,235) Reed Solomon code can correct : 10 symbols
Given : expected burst error length from the channel : 20 symbols
Interleaving MAY help in this scenario
Input Data to the Interleaver ->
THE_QUICK_BROWN_FOX_JUMPS_OVER_THE_LAZY_DOG_THE_QUICK_BROWN_FOX_JUMPS_OVER_T
HE_LAZY_DOG_THE_QUICK_BROWN_FOX_JUMPS_OVER_THE_LAZY_DOG_THE_QUICK_BROWN_FOX_
JUMPS_OVER_THE_LAZY_DOG_THE_QUICK_BROWN_FOX_JUMPS_OVER_THE_LAZY_DOG_THE_QUIC
K_BROWN_FOX_JUMPS_OVER_THE_THE_QUICK_BROWN_FOX_JUMPS_OVER_THE_LAZY_DOG_THE_
QUICK_BROWN_FOX_JUMPS_OVER_THE_LAZY_DOG_THE_QUICK_BROWN_FOX_JUMPS_OVER_THE_
LAZY_DOG_THE_QUICK_BROWN_FOX_JUMPS_OVER_THE_LAZY_DOG_THE_QUICK_BROWN_FOX_JU
MPS_OVER_THE_LAZY_DOG_THE_QUICK_BROWN_FOX_JUMPS_OVER_THE_THE_QUICK_BROWN_FOX
JUMPS_OVER_THE_LAZY_DOG_THE_QUICK_BROWN_FOX_JUMPS_OVER_THE_LAZY_DOG_THE_QUIC
K_BROWN_FOX_JUMPS_OVER_THE_LAZY_DOG_THE_QUICK_BROWN_FOX_JUMPS_OVER_THE_LAZY
DOG_THE_QUICK_BROWN_FOX_JUMPS_OVER_THE_LAZY_DOG_THE_QUICK_BROWN_FOX_JUMPS_O
VER_THE_____________________________________________________________________________
Interleaver Output after being corrupted by 20 symbols burst error – marked by ‘*‘->
TTTHHHEEE___QQQUUUIIICCC********************N___FFFOOOXXX___JJJUUUMMMPPPSSS___OOOVV
VEEERRR___TTTHHHEEE___LLLAAAZZZYYY___DDDOOOGGG___TTTHHHEEE___QQQUUUIIICCCKKK
___BBBRRROOOWWWNNN___FFFOOOXXX___JJJUUUMMMPPPSSS___OOOVVVEEERRR___TTTHHH
EEE___LLLAAAZZZYYY___DDDOOOGGG___TTTHHHEEE___QQQUUUIIICCCKKK___BBBRRROOOWWWN
NN___FFFOOOXXX___JJJUUUMMMPPPSSS___OOOVVVEEERRR___TTTHHHEEE___LLLAAAZZZYYY___
DDDOOOGGG___TTTHHHEEE___QQQUUUIIICCCKKK___BBBRRROOOWWWNNN___FFFOOOXXX___JJJ
UUUMMMPPPSSS___OOOVVVEEERRR___TTTHHHEEE___LLLAAAZZZYYY___DDDOOOGGG___TTTHHHEE
E___QQQUUUIIICCCKKK___BBBRRROOOWWWNNN___FFFOOOXXX___JJJUUUMMMPPPSSS___OOOV
VVEEERRR___TTTHHHEEE___LLLAAAZZZYYY___DDDOOOGGG___TTTHHHEEE___QQQUUUIIICCCKKK___
BBBRRROOOWWWNNN___FFFOOOXXX___JJJUUUMMMPPPSSS___OOOVVVEEERRR___TTTHHHEEE__
_____________________________________________________________________________
Deinterleaver Output->
THE_QUIC*******_FOX_JUMPS_OVER_THE_LAZY_DOG_THE_QUICK_BROWN_FOX_JUMPS_OVER_THE_
LAZY_DOG_THE_QUICK_BROWN_FOX_JUMPS_OVER_THE_LAZY_DOG_THE_QUICK_BROWN_FOX_JUM
PS_OVER_THE_LAZY_DOG_THE_QUICK_BROWN_FOX_JUMPS_OVER_THE_LAZY_DOG_THE_QUICK_BR
OWN_FOX_JUMPS_OVER_THE_THE_QUIC*******_FOX_JUMPS_OVER_THE_LAZY_DOG_THE_QUICK_BRO
WN_FOX_JUMPS_OVER_THE_LAZY_DOG_THE_QUICK_BROWN_FOX_JUMPS_OVER_THE_LAZY_DOG_TH
E_QUICK_BROWN_FOX_JUMPS_OVER_THE_LAZY_DOG_THE_QUICK_BROWN_FOX_JUMPS_OVER_THE_
LAZY_DOG_THE_QUICK_BROWN_FOX_JUMPS_OVER_THE_THE_QUIC******N_FOX_JUMPS_OVER_THE_L
AZY_DOG_THE_QUICK_BROWN_FOX_JUMPS_OVER_THE_LAZY_DOG_THE_QUICK_BROWN_FOX_JUMPS
_OVER_THE_LAZY_DOG_THE_QUICK_BROWN_FOX_JUMPS_OVER_THE_LAZY_DOG_THE_QUICK_BROWN
_FOX_JUMPS_OVER_THE_LAZY_DOG_THE_QUICK_BROWN_FOX_JUMPS_OVER_THE________________
_____________________________________________________________
As we can see from the above simulation that, eventhough the channel introduces 20 symbols of consecutive burst error (which is beyond the correction capability of the RS decoder), the interleaver/deinterleaver operation has effectively distributed the errors and reduced the maximum burst length to 7 symbols (which is easier to correct by (255,235) Reed Solomon code.
See also:
[1] Introduction to Interleavers and deinterleavers
[2] Random Interleavers
Additional Resources:
[1] Notes on theory and construction of Reed Solomon Codes – Bernard Sklar
[2] Concatenation and Advanced Codes – Applications of interleavers- Stanford University