What are hard and soft decision decoding
Hard decision decoding and soft decision decoding are two different methods used for decoding error-correcting codes.
With hard decision decoding, the received signal is compared to a set threshold value to determine whether the transmitted bit is a 0 or a 1. This is commonly used in digital communication systems that experience noise or interference, resulting in a low signal-to-noise ratio.
Soft decision decoding, on the other hand, treats the received signal as a probability distribution and calculates the likelihood of each possible transmitted bit based on the characteristics of the received signal. This approach is often used in modern digital communication and data storage systems where the signal-to-noise ratio is relatively high and there is a need for higher accuracy and reliability.
While soft decision decoding can achieve better error correction, it is more complex and computationally expensive than hard decision decoding.
More details
Let’s expatiate on the concepts of hard decision and soft decision decoding. Consider a simple even parity encoder given below.
|
Input Bit 1
|
Input Bit 2
|
Parity bit added by encoder
|
Codeword Generated
|
|
0
|
0
|
0
|
000
|
|
0
|
1
|
1
|
011
|
|
1
|
0
|
1
|
101
|
|
1
|
1
|
0
|
110
|
The set of all possible codewords generated by the encoder are 000,011,101 and 110.
Lets say we are want to transmit the message “01” through a communication channel.
Hard decision decoding
Case 1 : Assume that our communication model consists of a parity encoder, communication channel (attenuates the data randomly) and a hard decision decoder
The message bits “01” are applied to the parity encoder and we get “011” as the output codeword.
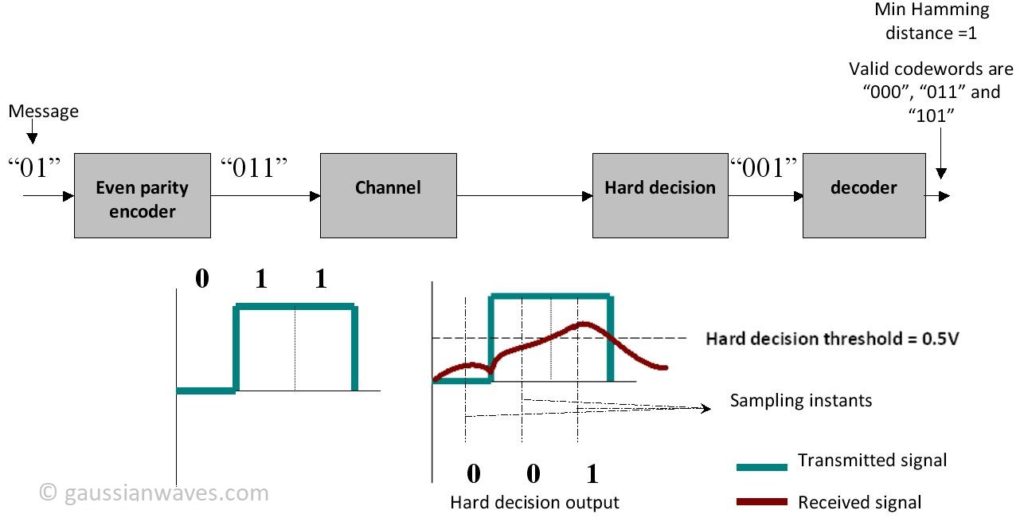
The output codeword “011” is transmitted through the channel. “0” is transmitted as “0 Volt and “1” as “1 Volt”. The channel attenuates the signal that is being transmitted and the receiver sees a distorted waveform ( “Red color waveform”). The hard decision decoder makes a decision based on the threshold voltage. In our case the threshold voltage is chosen as 0.5 Volt ( midway between “0” and “1” Volt ) . At each sampling instant in the receiver (as shown in the figure above) the hard decision detector determines the state of the bit to be “0” if the voltage level falls below the threshold and “1” if the voltage level is above the threshold. Therefore, the output of the hard decision block is “001”. Perhaps this “001” output is not a valid codeword ( compare this with the all possible codewords given in the table above) , which implies that the message bits cannot be recovered properly. The decoder compares the output of the hard decision block with the all possible codewords and computes the minimum Hamming distance for each case (as illustrated in the table below).
|
All possible Codewords
|
Hard decision output
|
Hamming distance
|
|
000
|
001
|
1
|
|
011
|
001
|
1
|
|
101
|
001
|
1
|
|
110
|
001
|
3
|
The decoder’s job is to choose a valid codeword which has the minimum Hamming distance. In our case, the minimum Hamming distance is “1” and there are 3 valid codewords with this distance. The decoder may choose any of the three possibility and the probability of getting the correct codeword (“001” – this is what we transmitted) is always 1/3. So when the hard decision decoding is employed the probability of recovering our data ( in this particular case) is 1/3. Lets see what “Soft decision decoding” offers …
Soft Decision Decoding
The difference between hard and soft decision decoder is as follows
- In Hard decision decoding, the received codeword is compared with the all possible codewords and the codeword which gives the minimum Hamming distance is selected
- In Soft decision decoding, the received codeword is compared with the all possible codewords and the codeword which gives the minimum Euclidean distance is selected. Thus the soft decision decoding improves the decision making process by supplying additional reliability information ( calculated Euclidean distance or calculated log-likelihood ratio)
For the same encoder and channel combination lets see the effect of replacing the hard decision block with a soft decision block.

Voltage levels of the received signal at each sampling instant are shown in the figure. The soft decision block calculates the Euclidean distance between the received signal and the all possible codewords.
| Valid codewords | Voltage levels at each sampling instant of received waveform | Euclidean distance calculation | Euclidean distance |
|
0 0 0
( 0V 0V 0V )
|
0.2V 0.4V 0.7V
|
(0-0.2)2+ (0-0.4)2+ (0-0.7)2
|
0.69
|
|
0 1 1
( 0V 1V 1V )
|
0.2V 0.4V 0.7V
|
(0-0.2)2+ (1-0.4)2+ (1-0.7)2
|
0.49
|
|
1 0 1
( 1V 0V 1V )
|
0.2V 0.4V 0.7V
|
(1-0.2)2+ (0-0.4)2+ (1-0.7)2
|
0.89
|
|
1 1 0
( 1V 1V 0V )
|
0.2V 0.4V 0.7V
|
(1-0.2)2+ (1-0.4)2+ (0-0.7)2
|
1.49
|
The minimum Euclidean distance is “0.49” corresponding to “0 1 1” codeword (which is what we transmitted). The decoder selects this codeword as the output. Even though the parity encoder cannot correct errors, the soft decision scheme helped in recovering the data in this case. This fact delineates the improvement that will be seen when this soft decision scheme is used in combination with forward error correcting (FEC) schemes like convolution codes , LDPC etc
From this illustration we can understand that the soft decision decoders uses all of the information ( voltage levels in this case) in the process of decision making whereas the hard decision decoders does not fully utilize the information available in the received signal (evident from calculating Hamming distance just by comparing the signal level with the threshold whereby neglecting the actual voltage levels).
Note: This is just to illustrate the concept of Soft decision and Hard decision decoding. Prudent souls will be quick enough to find that the parity code example will fail for other voltage levels (e.g. : 0.2V , 0.4 V and 0.6V) . This is because the parity encoders are not capable of correcting errors but are capable of detecting single bit errors.
Soft decision decoding scheme is often realized using Viterbi decoders. Such decoders utilize Soft Output Viterbi Algorithm (SOVA) which takes into account the apriori probabilities of the input symbols producing a soft output indicating the reliability of the decision.
Rate this article: [ratings]
For further reading
Books by the author
[table “23” not found /]
Thanks for this nice illustration of soft and hard decision decoding.
its very clear illustration.
its very clear illustration.
Very helpful in Understanding soft decision making… Thanks.
Will our viterbi decoder makes the soft decision ?
Viterbi decode can be designed to use Soft decisions. The algorithm is called Soft Output Viterbi
Algorithm (SOVA)
A Classical paper here for your reference :
J. Hagenauer and P. Hoeher, “A Viterbi algorithm with soft-decision outputs and its applications,” in Proc. IEEE Global Telecommunications Conference 1989, Dallas, Texas,Nov. 1989, pp. 1680
http://www-ict.tf.uni-kiel.de/download/Hagenauer_GLOBECOM_1989.pdf
Thnks for sharing useful info….
Thnks for sharing useful info….
Hello, Mathuranathan.
Can I use this term 10^(-Eb_N0_dB(ii)/20)*n, (n = 1/sqrt(2)*[randn(1,N)] for specify AWGN if I use soft decoding algorithm and have 8 levels of quantizer (2.8 V:-0.4 V:-2.8 V)?
Thanks.
yes you can use that expression. It does not matter which type of decoding you use (haard or soft). Noise is noise.
While I getting BER curve, I noticed that BER=0 for Eb/N0 = 0 dB. I think I get this wrong result because amplitude of noise very small for transmitted signals 0 ->2.8 V and 1 -> -2.8. What can I do to get right result?
This is just a hint of what you can try. But not the complete solution, since you know your code best.
1) check for a simple Hard decision decoding.
2) Simulate for a very high SNR condition (~40 dB) where noise is virtually non-existent. Check the decoded data and source data in the transmitter. They should match exactly. If they are not matching, you have to debug your decoding algorithm or other parts of the code.
3) If results in step 2 are matching, revert to soft decision decoding and keep the SNR very high. Again, the decoded data and source data should match. If not, debug for the problem in the soft decision decoding algorithm.
4) Everything goes well and still you are getting erroneous results: Tweak the noise term.
When I use 10^(-Eb_N0_dB(ii)/20)*n, (n = 1/sqrt(2)*[randn(1,N)]) for specify AWGN, I suppose that energy of bit Eb = 1, don’t i? But I associate 0 (or 1) with 2.8 V (or -2.8 V), maybe error can be in this?
Yes, the above formulations works only when the Eb is normalized to unity. When Eb is not equal to 1, you have to scale the noise appropriately.
So, when I associate 0 (or 1) with 2.8 V (or -2.8 V) Eb is not equal to 1? Or it doesn’t matter?
I am not sure about whats going on in your code.
Just as an example, For BPSK, the mapping 0->-1V and 1-> +1V or vice versa, will give proper results when using the above equation.
If you are using 2.8 voltage range, the noise term has to be scaled properly.
I have come up with a new method for doing this. This will be documented in detail in third edition of the ebook (work in progress).
The best way is to measure the energy content of the signal and generate the required noise. This will work for any voltage ranges.
1) E_meas = 1/N * sum( abs(s)^2 ) ; % measured energy
2) N_required = E_meas / (Es/N0)_given; %(Es/N0)_given is the given energy per symbol to noise ration (not Eb/N0 given)
3) sigma = sqrt(N_required/2);
4) noise = sigma*randn(1,N); %mu=0 and use sigma term above to calculate noise.
5) y = s+ n ; %add the signal and generated noise
This method eliminates the need for confusion scaling terms that are difficult to understand.
hello
I am looking for Matlab code for convolutional coded BPSK over AWGN, with soft decision vetrbi decoding.
I bought your book but i couldn’t find this code in it.
could you please help me with it.
Regards
The simulation code for the mentioned special topic is not available in the ebook. However, you can combine the code give in “Chapter 6.2 BER vs. Eb/N0 for BPSK modulation over AWGN” with the code given for convolutional coding and trellis decoding given at mathworks documentation -http://www.mathworks.com/help/comm/ug/error-detection-and-correction.html#fp7405
Thanks for your interest !!!
you can try this code:
function [ brr ] = brr(n,k)%nis number of transmeted message and k is the constraint %length of convolutional code
% Traceback Length
tblen = 5*k;
snr=0:5;
for ii=1:length(snr)
msg = round(rand(1,n));
code = convenc(msg,trel);
code=-2*code+1;
SNRdBs = snr(ii)+ 10*log(0.5)/log(10);
N0=10^(-SNRdBs/10);
ucode=code+sqrt(N0/2)*(randn(1,length(code)));
ucode=real(ucode);
dcdsoft = vitdec(ucode,trel,tblen,’cont’,’unquant’);
diff=msg(1,1:end-tblen)-dcdsoft(1,tblen+1:end);
%diff=msg-dcdsoft;
s(ii)=sum(abs(diff))/length(msg)
end
semilogy(snr,s,’r’)
end
i’m looking for Matlab code for convolutional coded BPSK over exponential correlated rayleigh channel, with soft decision vetirbi decoding.
could you please help me.
best regards