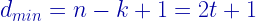Its been too long since I posted. For a kick start , i am continuing the theory on RS coding. Here is a simple Matlab code (which can be found in Matlab Help, posted here with a little bit detailed explanation) for better understanding of RS code
%Matlab Code for RS coding and decoding
n=7; k=3; % Codeword and message word lengths m=3; % Number of bits per symbol msg = gf([5 2 3; 0 1 7;3 6 1],m) % Two k-symbol message words % message vector is defined over a Galois field where the number must %range from 0 to 2^m-1
codedMessage = rsenc(msg,n,k) % Two n-symbol codewords
dmin=n-k+1 % display dmin t=(dmin-1)/2 % diplay error correcting capability of the code
% Generate noise – Add 2 contiguous symbol errors with first word; % 2 discontiguous symbol errors with second word and 3 distributed symbol % errors to last word noise=gf([0 0 0 2 3 0 0 ;6 0 1 0 0 0 0 ;5 0 6 0 0 4 0],m)
received = noise+codedMessage
%dec contains the decoded message and cnumerr contains the number of %symbols errors corrected for each row. Also if cnumerr(i) = -1 it indicates %that the ith row contains unrecoverable error [dec,cnumerr] = rsdec(received,n,k) % print the original message for comparison msg
% Given below is the output of the program. Only decoded message, cnumerr and original % message are given here (with comments inline)
% The default primitive polynomial over which the GF is defined is D^3+D+1 ( which is 1011 -> 11 in decimal).
dec = GF(2^3) array. Primitive polynomial = D^3+D+1 (11 decimal)
Array elements =
5 2 3 0 1 7 6 6 7
cnumerr =
2 2 -1 ->>> Error in last row -> this error is due to the fact that we have added 3 distributed errors with the last row where as the RS code can correct only 2 errors. Compare the decoded message with original message given below for confirmation
% Original message printed for comparison msg = GF(2^3) array. Primitive polynomial = D^3+D+1 (11 decimal)
Array elements =
5 2 3 0 1 7 3 6 1
Reference : [1] Mathematics behind RS codes – Bernard Sklar – Click Here
The Hamming codes described in the previous articles are suitable for random bit errors in a sequence of transmitted bits. If the communication medium is prone to burst errors (channel errors affecting contiguous blocks of bits) (missing symbols are called erasures ), then Hamming code may not be suitable.
For example in CD, DVD and in Hard drives, the data is written in contiguous blocks and are retrieved in contiguous blocks. The heart of a hard disk is the read/write channel (an integral part of the disk drive controller SOC chip). The read/write channel is used to improve the signal to noise ratio of the data that is written into and read from the disk. Its design is aimed at providing reliable data retrieval from the disk. Algorithms like PRML (Partial Response signaling with Maximum Likelihood detection) are used to increase the areal densities of the disk (packing more bits in a given area on the disk platter). Error control coding is used to improve the performance of the detection algorithm and to protect the user data from erasures. In this case, a class of Error correcting codes called Reed Solomon Codes (RS Codes) are used. RS Codes have been utilized in hard disks for the past 15 to 20 years. RS codes are useful for channels having memory (like CD,DVD).
The other applications of RS Codes include:
1) Digital Subscriber line (DSL) and its variants like ADSL, VDSL…
2) Deep space and satellite communications
3) Barcodes
4) Digital Television
5) Microwave communication, Mobile communications and many more…
Reed Solomon Codes are linear block codes, a subset of the BCH codes called non-binary BCH. (n,k) RS code contains k data symbols and n-k parity symbols. RS Codes are also cyclic codes since the cyclic shift of any codeword will result in another valid RS codeword.
Note the usage of the word “symbols” instead of “bits” when referring to RS Codes. The word symbol is used to refer a group of bits. For example if I say that I am using a (7,3) RS Code with 5 bit symbols, it implies that each symbol is a collection of 5-bits and the RS Codeword is made up of 7 such symbols, of which 3 symbols represent data and remaining 4 symbols represent parity symbols.
A m-bit RS (n,k) Code can be defined using
where t is the symbol error correcting capability of the RS code. This code corrects t symbol errors. We can also see that the minimum distance for RS code is given by
This gives the maximum possible dmin. A code with maximum dmin is more reliable as it will be able to correct more errors.
Example:
Consider a (255,247) RS code , where each symbol is made up of m=8 bits. This code contains 255 symbols (each 8 bits of length) in a codeword of which 247 symbols are data symbols and the remaining 8 symbols are parity symbols. This code can correct any 4 symbol burst errors.
If the errors are not occurring in a burst fashion, it will affect the codeword symbols randomly and it may corrupt more than 4 symbols. At this situation the RS code fails. So it is essential that the RS codes should be used only for burst error correction. Other techniques like interleaving/deinterleaving are used in tandem with RS codes to combat both burst and random errors.
Performance Effects of RS Codes :
1) block length Increases (n) -> BER decreases
2) Redundancy Increases (k) -> code rate decreases -> BER decreases -> complexity increases
( code rate = n/k)
3) Optimum code rate for an RS code is calculated from the decoder performance (for a particular channel) at various code rates. The code rate which require the lowest Eb/N0 for a given BER is chosen as the optimum code rate for RS Code design.
Matlab Code:
Here is a simple Matlab code (which can be found in Matlab Help, posted here with a little bit detailed explanation) for better understanding of RS code
%Matlab Code for RS coding and decoding
n=7; k=3; % Codeword and message word lengths
m=3; % Number of bits per symbol
msg = gf([5 2 3; 0 1 7;3 6 1],m) % Two k-symbol message words
% message vector is defined over a Galois field where the number must
%range from 0 to 2^m-1
codedMessage = rsenc(msg,n,k) % Two n-symbol codewords
dmin=n-k+1 % display dmin
t=(dmin-1)/2 % diplay error correcting capability of the code
% Generate noise - Add 2 contiguous symbol errors with first word;
% 2 discontiguous symbol errors with second word and 3 distributed symbol
% errors to last word
noise=gf([0 0 0 2 3 0 0 ;6 0 1 0 0 0 0 ;5 0 6 0 0 4 0],m)
received = noise+codedMessage
%dec contains the decoded message and cnumerr contains the number of
%symbols errors corrected for each row. Also if cnumerr(i) = -1 it indicates
%that the ith row contains unrecoverable error
[dec,cnumerr] = rsdec(received,n,k)
% print the original message for comparison
display(msg)
% Given below is the output of the program. Only decoded message, cnumerr and original
% message are given here (with comments inline)
% The default primitive polynomial over which the GF is defined is D^3+D+1 ( which is 1011 -> 11 in decimal). dec = GF(2^3) array. Primitive polynomial = D^3+D+1 (11 decimal)
Array elements =
5 2 3
0 1 7
6 6 7
cnumerr =
2
2
-1 ->>> Error in last row -> this error is due to the fact that we have added 3 distributed errors with the last row where as the RS code can correct only 2 errors. Compare the decoded message with original message given below for confirmation
% Original message printed for comparison
msg = GF(2^3) array. Primitive polynomial = D^3+D+1 (11 decimal)
Array elements =
5 2 3
0 1 7
3 6 1
Reference :
[1] Mathematics behind RS codes – Bernard Sklar – Click Here
Keywords: Hamming code, error-correction code, digital communication, data storage, reliable transmission, computer memory systems, satellite communication systems, single-bit error, two-bit errors.
What is a Hamming Code
Hamming codes are a class of error-correcting codes that are commonly employed in digital communication and data storage systems to detect and correct errors that may occur during transmission or storage. They were created by Richard Hamming in the 1950s and bear his name.
The central concept of Hamming codes is to introduce additional (redundant) bits to a message in order to enable the identification and correction of errors. By appending parity bits to the original message, Hamming codes can identify and correct single-bit errors.
One notable characteristic of these codes is their ability to correct any single-bit error and detect any two-bit error, which has contributed to their widespread usage in computer memory systems, satellite communication systems, and other domains where reliable data transmission is crucial.
Technical details of Hamming code
Linear binary Hamming code falls under the category of linear block codes that can correct single bit errors. For every integer p ≥ 3 (the number of parity bits), there is a (2p-1, 2p-p-1) Hamming code. Here, 2p-1 is the number of symbols in the encoded codeword and 2p-p-1 is the number of information symbols the encoder can accept at a time. All such Hamming codes have a minimum Hamming distance dmin=3 and thus they can correct any single bit error and detect any two bit errors in the received vector. The characteristics of a generic (n,k) Hamming code is given below.
\[\begin{aligned} \text{Codeword length:} \quad && n &= 2^p-1 \\ \text{Number of information symbols:} \quad && k &= 2^p-p-1 \\ \text{Number of parity symbols:} \quad && n-k &= p \\ \text{Minimum distance:} \quad && d_{min} &= 3 \\ \text{Error correcting capability:} \quad && t &=1 \end{aligned}\]
With the simplest configuration: p=3, we get the most basic (7, 4) binary Hamming code. The (7,4) binary Hamming block encoder accepts blocks of 4-bit of information, adds 3 parity bits to each such block and produces 7-bits wide Hamming coded blocks.
Systematic & Non-systematic encoding
Block codes like Hamming codes are also classified into two categories that differ in terms of structure of the encoder output:
● Systematic encoding ● Non-systematic encoding
In systematic encoding, just by seeing the output of an encoder, we can separate the data and the redundant bits (also called parity bits). In the non-systematic encoding, the redundant bits and data bits are interspersed.
Figure 1: Systematic encoding and non-systematic encoding
Constructing (7,4) Hamming code
Hamming codes can be implemented in systematic or non-systematic form. A systematic linear block code can be converted to non-systematic form by elementary matrix transformations. A non-systematic Hamming code is described next.
Let a codeword belonging to (7, 4) Hamming code be represented by [D7,D6,D5,P4,D3,P2,P1], where D represents information bits and P represents parity bits at respective bit positions. The subscripts indicate the left to right position taken by the data and the parity bits. We note that the parity bits are located at position that are powers of two (bit positions 1,2,4).
Now, represent the bit positions in binary.
Seeing from left to right, the first parity bit (P1) covers the bits at positions whose binary representation has 1 at the least significant bit. We find that P1 covers the following bit positions
Similarly, the second parity bit (P2) covers the bits at positions whose binary representation has 1 at the second least significant bit. Hence, P2covers the following bit positions.
Finally, the third parity bit (P4) covers the bits at positions whose binary representation has 1 at the most significant bit. Hence, P4 covers the following bit positions
If we follow even parity scheme for parity bits, the number of 1’s covered by the parity bits must add up to an even number. Which implies that the XOR of bits covered by the parity (including the parity bits) must result in 0. Therefore, the following equations hold.
Following table illustrates the concept of constructing the Hamming code as described by R.W Hamming in his groundbreaking paper [1].
Table 1: Construction of (7,4) binary Hamming code
We note that the parity bits and data columns are interspersed. This is an example of non-systematic Hamming code structure. We can continue our work on the table above as it is. Or, we can also re-arrange the entries of that table using elemental transformations, such that a systematic Hamming code is rendered.
Figure 2: Re-arranging Hamming code using transformation (non-systematic to systematic code)
After the re-arrangement of columns, we see that the parity columns are nicely clubbed together at the end. We can also drop the subscripts given to the parity/data locations and re-index them according to our convenience. This gives the following structure to the (7,4) Hamming code.
Figure 3: Example for Systematic Hamming code
We will use the above systematic structure in the following discussion.
Encoding process
Given the structure in Figure 3, the parity bits are calculated from the following linearly independent equations using modulo-2 additions.
Figure 4: Computing the parity bits for (7,4) Hamming code
At the transmitter side, a Hamming encoder implements a generator matrix – . It is easier to construct the generator matrix from the linear equations listed in equation above. The linear equations show that the information bit D1 influences the calculation of parities at P1 and P3 . Similarly, the information bit D2 influences P1 and P2, D3 influences P1, P2 & P3 and D4 influences P2 & P3.
Represented as matrix operations, the encoder accepts 4 bit message block \(\mathbf{m}\), multiplies it with the generator matrix \(\mathbf{G}\) and generates 7 bit codewords \(\mathbf{c}\). Note that all the operations (addition, multiplication etc.,) are in modulo-2 domain.
\[\mathbf{c}= \mathbf{m} \mathbf{G} \]
Given a generator matrix, the Matlab code snippet for generating a codebook containing all possible codewords (\(\mathbf{c} \in \mathbf{C}\)) is given below. The resulting codebook \(\mathbf{C}\) can be used as a Look-Up-Table (LUT) when implementing the encoder. This implementation will avoid repeated multiplication of the input blocks and the generator matrix. The list of all possible codewords for the generator matrix (\(\mathbf{G}\)) given above are listed in table 2.
Table 2: All possible codewords for (7,4) Hamming code
Program: Generating all possible codewords from Generator matrix
%program to generate all possible codewords for (7,4) Hamming code
G=[ 1 0 0 0 1 0 1;
0 1 0 0 1 1 0;
0 0 1 0 1 1 1;
0 0 0 1 0 1 1];%generator matrix - (7,4) Hamming code
m=de2bi(0:1:15,'left-msb');%list of all numbers from 0 to 2ˆk
codebook=mod(m*G,2) %list of all possible codewords
Decoding process – Syndrome decoding
The three check equations for the given generator matrix (\(\mathbf{G}\)) for the sample (7,4) Hamming code, can be expressed collectively as a parity check matrix – \(\mathbf{H}\). Parity check matrix finds its usefulness in the receiver side for error-detection and error-correction.
According to parity-check theorem, for every generator matrix G, there exists a parity-check matrix H, that spans the null-space of G. Therefore, if c is a valid codeword, then it will be orthogonal to each row of H.
\[\mathbf{c} \mathbf{H}^T = 0 \]
Therefore, if \(\mathbf{H}\) is the parity-check matrix for a codebook \(\mathbf{C}\), then a vector \(\mathbf{c}\) in the received code space is a valid codeword if and only if it satisfies \(\mathbf{c} \mathbf{H}^T=0\).
Consider a vector of received word \(\mathbf{r}=\mathbf{c}+\mathbf{e}\), where \(\mathbf{c}\) is a valid codeword transmitted and \(\mathbf{e}\) is the error introduced by the channel. The matrix product \(\mathbf{r}\mathbf{H}^T\) is defined as the syndrome for the received vector \(\mathbf{r}\), which can be thought of as a linear transformation whose null space is \(\mathbf{C}\) [2].
Thus, the syndrome is independent of the transmitted codeword \(\mathbf{c}\) and is solely a function of the error pattern \(\mathbf{e}\). It can be determined that if two error vectors \(\mathbf{e}\) and \(\mathbf{e}’\) have the same syndrome, then the error vectors must differ by a nonzero codeword.
It follows from the equation above, that decoding can be performed by computing the syndrome of the received word, finding the corresponding error pattern and subtracting (equivalent to addition in \(GF(2)\) domain) the error pattern from the received word. This obviates the need to store all the vectors as in a standard array decoding and greatly reduces the memory requirements for implementing the decoder.
Following is the syndrome table for the (7,4) Hamming code example, illustrated here.
Some properties of generator and parity-check matrices
The generator matrix \(\mathbf{G}\) and the parity-check matrix \(\mathbf{H}\) satisfy the following property
\[\mathbf{G} \mathbf{H}^T = 0\]
Note that the generator matrix is in standard form where the elements are partitioned as
\[\mathbf{G} = \begin{bmatrix} I_k \mid P \end{bmatrix} \]
whereIk is a k⨉k identity matrix and P is of dimension k ⨉ (n-k). When G is a standard form matrix, the corresponding parity-check matrix H can be easily determined as
\[\mathbf{H} =[−P^T∣I_{n−k}]\]
In Galois Field – GF(2), the negation of a number is simply its absolute value. Hence the H matrix for binary codes can be simply written as
Shannon theorem dictates the maximum data rate at which the information can be transmitted over a noisy band-limited channel. The maximum data rate is designated as channel capacity. The concept of channel capacity is discussed first, followed by an in-depth treatment of Shannon’s capacity for various channels.
Introduction
The main goal of a communication system design is to satisfy one or more of the following objectives.
● The transmitted signal should occupy smallest bandwidth in the allocated spectrum – measured in terms of bandwidth efficiency also called as spectral efficiency – \(\eta_B\). ● The designed system should be able to reliably send information at the lowest practical power level. This is measured in terms of power efficiency – \(\eta_P\). ● Ability to transfer data at higher rates – \(R\) bits=second. ● The designed system should be robust to multipath effects and fading. ● The system should guard against interference from other sources operating in the same frequency – low carrier-to-cochannel signal interference ratio (CCI). ● Low adjacent channel interference from near by channels – measured in terms of adjacent channel Power ratio (ACPR). ● Easier to implement and lower operational costs.
Chapter 2 in my book ‘Wireless Communication systems in Matlab’, is intended to describe the effect of first three objectives when designing a communication system for a given channel. A great deal of information about these three factors can be obtained from Shannon’s noisy channel coding theorem.
Shannon’s noisy channel coding theorem
For any communication over a wireless link, one must ask the following fundamental question: What is the optimal performance achievable for a given channel ?. The performance over a communication link is measured in terms of capacity, which is defined as the maximum rate at which the information can be transmitted over the channel with arbitrarily small amount of error.
It was widely believed that the only way for reliable communication over a noisy channel is to reduce the error probability as small as possible, which in turn is achieved by reducing the data rate. This belief was changed in 1948 with the advent of Information theory by Claude E. Shannon. Shannon showed that it is in fact possible to communicate at a positive rate and at the same time maintain a low error probability as desired. However, the rate is limited by a maximum rate called the channel capacity. If one attempts to send data at rates above the channel capacity, it will be impossible to recover it from errors. This is called Shannon’s noisy channel coding theorem and it can be summarized as follows:
● A given communication system has a maximum rate of information – C, known as the channel capacity. ● If the transmission information rate R is less than C, then the data transmission in the presence of noise can be made to happen with arbitrarily small error probabilities by using intelligent coding techniques. ● To get lower error probabilities, the encoder has to work on longer blocks of signal data. This entails longer delays and higher computational requirements.
The theorem indicates that with sufficiently advanced coding techniques, transmission that nears the maximum channel capacity – is possible with arbitrarily small errors. One can intuitively reason that, for a given communication system, as the information rate increases, the number of errors per second will also increase.
Shannon’s noisy channel coding theorem is a generic framework that can be applied to specific scenarios of communication. For example, communication through a band-limited channel in presence of noise is a basic scenario one wishes to study. Therefore, study of information capacity over an AWGN (additive white gaussian noise) channel provides vital insights, to the study of capacity of other types of wireless links, like fading channels.
Unconstrained capacity for band-limited AWGN channel
Real world channels are essentially continuous in both time as well as in signal space. Real physical channels have two fundamental limitations : they have limited bandwidth and the power/energy of the input signal to such channels is also limited. Therefore, the application of information theory on such continuous channels should take these physical limitations into account. This will enable us to exploit such continuous channels for transmission of discrete information.
In this section, the focus is on a band-limited real AWGN channel, where the channel input and output are real and continuous in time. The capacity of a continuous AWGN channel that is bandwidth limited to \(B\) Hz and average received power constrained to \(P\) Watts, is given by
Here, \(N_0/2\) is the power spectral density of the additive white Gaussian noise and \(P\) is the average power given by
\[P = E_b R \quad \quad (2) \]
where \(E_b\) is the average signal energy per information bit and \(R\) is the data transmission rate in bits-per-second. The ratio \(P/(N_0B)\) is the signal to noise ratio (SNR) per degree of freedom. Hence, the equation can be re-written as
Here, \(C\) is the maximum capacity of the channel in bits/second. It is also called Shannon’s capacity limit for the given channel. It is the fundamental maximum transmission capacity that can be achieved using the basic resources available in the channel, without going into details of coding scheme or modulation. It is the best performance limit that we hope to achieve for that channel. The above expression for the channel capacity makes intuitive sense:
● Bandwidth limits how fast the information symbols can be sent over the given channel. ● The SNR ratio limits how much information we can squeeze in each transmitted symbols. Increasing SNR makes the transmitted symbols more robust against noise. SNR represents the signal quality at the receiver front end and it depends on input signal power and the noise characteristics of the channel. ● To increase the information rate, the signal-to-noise ratio and the allocated bandwidth have to be traded against each other. ● For a channel without noise, the signal to noise ratio becomes infinite and so an infinite information rate is possible at a very small bandwidth. ● We may trade off bandwidth for SNR. However, as the bandwidth B tends to infinity, the channel capacity does not become infinite – since with an increase in bandwidth, the noise power also increases.
The Shannon’s equation relies on two important concepts: ● That, in principle, a trade-off between SNR and bandwidth is possible ● That, the information capacity depends on both SNR and bandwidth
It is worth to mention two important works by eminent scientists prior to Shannon’s paper [1]. Edward Amstrong’s earlier work on Frequency Modulation (FM) is an excellent proof for showing that SNR and bandwidth can be traded off against each other. He demonstrated in 1936, that it was possible to increase the SNR of a communication system by using FM at the expense of allocating more bandwidth [2]
In 1903, W.M Miner in his patent (U. S. Patent 745,734 [3]), introduced the concept of increasing the capacity of transmission lines by using sampling and time division multiplexing techniques. In 1937, A.H Reeves in his French patent (French Patent 852,183, U.S Patent 2,272,070 [4]) extended the system by incorporating a quantizer, there by paving the way for the well-known technique of Pulse Coded Modulation (PCM). He realized that he would require more bandwidth than the traditional transmission methods and used additional repeaters at suitable intervals to combat the transmission noise. With the goal of minimizing the quantization noise, he used a quantizer with a large number of quantization levels. Reeves patent relies on two important facts:
● One can represent an analog signal (like speech) with arbitrary accuracy, by using sufficient frequency sampling, and quantizing each sample in to one of the sufficiently large pre-determined amplitude levels ● If the SNR is sufficiently large, then the quantized samples can be transmitted with arbitrarily small errors
It is implicit from Reeve’s patent – that an infinite amount of information can be transmitted on a noise free channel of arbitrarily small bandwidth. This links the information rate with SNR and bandwidth.
Please refer [1] and [5] for the actual proof by Shannon. A much simpler version of proof (I would rather call it an illustration) can be found at [6].
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.