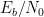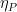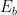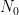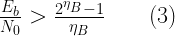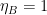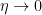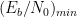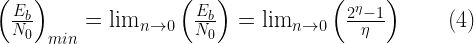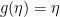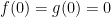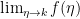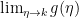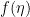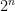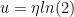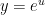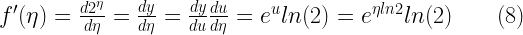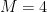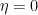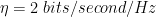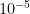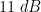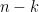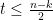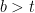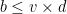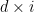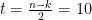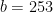Key focus : Convolutional codes: Error-correcting codes effective in noisy channels and burst error correction. Know about sliding window & shift registers and how they are used in a convolutional encoder.
Linear block codes
Linear block codes, like Hamming codes, are mainly employed in hard decision decoding, utilizing the inherent algebraic structure of the code based on finite field properties.
Hard decision decoding of these codes creates a model resembling a binary symmetric channel. This model includes the essential components: the binary modulator, waveform channel, and optimal binary detector.
The decoder’s task for these codes is to find the codeword with the shortest Hamming distance from the binary symmetric channel’s output. When designing effective linear block codes, the primary aim is to discover the code with the highest minimum distance, considering the specific values of \(n\) and \(k\), where \(n\) is the number of output bits and \(k\) is the number of input bits.
As we saw, linear block codes are easily described in terms of algebraic equations. Convolutional codes are another class of error-correcting codes that are described using graphs and trellises.
Convolutional codes
Convolutional codes are a type of error-correcting code used in digital communication and data storage systems to detect and correct errors that may occur during transmission or storage. They are particularly well-suited for channels that introduce burst errors, such as noisy communication channels or storage media with localized errors.
Unlike the linear blocks, where the message bits and parity bits are transmitted, in the convolutional coding scheme, we do not send the message bits but only send the parity bits. Which message bits participate in generation of the parity bits is determined by a sliding window.
Convolutional codes are defined by a set of shift registers and associated feedback connections. The fundamental principle involves encoding input data via a sliding bit window (Figure 1), utilizing bitwise operations to generate the encoded result. The encoded bits are the parity bits. The encoded bits are a linear combination of the current input bits and previous input bits in the shift registers.
Let’s see some definitions with respect to convolutional codes:
Rate: Convolutional codes are often described by their rate, which is the ratio of the number of input bits to the number of output bits (encoded bits). A common notation for convolutional codes is given as \(n,k,m\) where \(n\) is the number of output bits (equivalently the number of generator polynomials), \(k\) is the number of input bits (equivalently the number of bits shifted by the shifter register at a time), and \(m\) is the number of shift registers. The code rate is given by \(R_c = k/n\).
Constraint Length: The constraint length of a convolutional code is the number of shift registers in the encoder. It determines the memory of the code and affects its error-correction capabilities. Larger the constraint length, greater is the redundancy and it may provide better error correction capabilities.
Generator Polynomials: The feedback connections and the bitwise operations performed on the shift registers are defined by generator polynomials. These polynomials determine the encoding process and the redundancy (parity bits) introduced into the data. Code rate is simply calculated as \(R_c = k/n\), where \(n\) is the number of generator polynomials in the encoder structure and \(k\) is the number of input bits at a time. More generator polynomials may improve the error correction capability of the code, it effectively decreases the code rate (more overhead).
Encoding: Convolutional encoding involves shifting the input bits through the shift registers and applying bitwise operations based on the generator polynomials. The encoder bits are just parity bits. In the convolutional encoding scheme, we only transmit the parity bits and not the message itself. If we use multiple generator polynomials, we interleave the output bits of each generate and serialize them when transmitting.
Decoding: At the receiver end, a decoding algorithm (such as the Viterbi algorithm) is used to analyze the received bits and recover the original data. The decoding process tries to find the most likely sequence of input bits given the received encoded bits and the code’s properties. We will come to this process in a later post.
Figure 1 shows a \(n=2, k=1,m=3\) convolutional encoder. The symbol D represents the delay as the input bits are processed through the shift registers. The generator polynomial is specified as \(g_0 = [1,1,1]\) and \(g_1=[1,0,1]\). The generator polynomials connect the appropriate cells in the shift register and performs XOR (modulo-2) operation on the bits stored in the shift register cells. This particular convolutional code generates 2 output bits for every input bit processed. The two output bit streams are designated as \(c_0\) and \(c_1\).
Since there are two generator polynomials, the code rate is \(R_c = 1/2\)
Given an input message \(x[n]\) the equation for generating the parity bit streams is given by


Figure 2 shows the sliding window representation of the shift register arrangement shown in Figure 1. Figure 2 shows a 3-bit (\(m\)) sliding window shift register that advances 1-bit (\(k\)) at a time. The number of output bits (\(n\)) depend on how these bits are processes using the generator polynomials.


Sample encoding operation
Figure 2 visualizes the encoding process for a \(n=2, k=1, m=3\) convolutional code. The generator polynomial is specified as \(g_0 =[1,1,1]\) and \(g_1 = [1, 0, 1]\). The generator polynomials connect the appropriate cells in the shift register and performs XOR (modulo-2) operation on the bits in the shift register cells.
These two generator polynomials generate the corresponding output bits \(c_0\) and \(c_1\). The input message to encode is \([1,0,1,1,0,0]\). The output generated by this particular convolutional encoder is \([11,10,00,01,01,11]\).


Encoder state machine
As illustrated in Figure 2, the constraint length \(m\) determines the number of memory cells in the shift register structure. The input bit and the \(m-1\) bits of current state determine the encoder state on the next clock cycle.
Because the encoder’s output relies on both its input and current state, state diagram is a more concise illustration than the trellis. Essentially, the state diagram represents a graphical depiction of the encoder’s potential states and the potential transition between these states.
From the state diagram, we can immediately recognize the fact : convolutional encoder is indeed a Markov chain.
To know more about Markov chain refer here. Implementing a Markov chain in python is discussed here.


Figure 4 depicts the state diagram for the convolutional encoder described in Figure 1. For a convolutional encoder with constraint length m, there will be \(2^{m-1}\) possible states. For this specific case, there are \(2^{3-1} = 4\) possible states.
The current state is represented as \(x[n-1]\) and \(x[n-2]\) (corresponding to the values of the memory cells \(D_1\) and \(D_2\). The output of the encoder is determined by the current input bit \(x[n]\) and the current state. Since there are two generator polynomials \(g_0\) and \(g_1\), they generate two outputs \(c_0[n]\) and \(c_1[n]\) respectively. For an input bit \(x[n]\), the encoder transits from one state to the next state, it emits \(c_0[n]\) and \(c_1[n]\) as output. This is depicted as \(x[n]/c_0[n]c_1[n]\).
Figure 5, shows the encoding process when the input message is \([1, 0, 1, 1, 0, 0]\). The encoder transits through various states and generates the output \([11, 10, 00, 01, 01, 11]\).