Uniform random variables are used to model scenarios where the expected outcomes are equi-probable. For example, in a communication system design, the set of all possible source symbols are considered equally probable and therefore modeled as a uniform random variable.
The uniform distribution is the underlying distribution for an uniform random variable. A continuous uniform random variable, denoted as



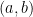
This article is part of the book |
$$ f_X(x) = \begin{cases}\frac{1}{b-a} & \text{when } a < x < b\\0 & \text{otherwise} \end{cases} $$
In Matlab, rand function generates continuous uniform random numbers in the interval

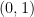



a + (b-a)*rand(n,m); %Here nxm is the size of the output matrixTo test whether the numbers generated by the continuous uniform distribution are uniform in the interval
a=2;b=10; %open interval (2,10)
X=a+(b-a)*rand(1,1000000);%simulate uniform RV
[p,edges]=histcounts(X,'Normalization','pdf');%estimated PDF
outcomes = 0.5*(edges(1:end-1) + edges(2:end));%possible outcomes
g=1/(b-a)*ones(1,length(outcomes)); %Theoretical PDF
bar(outcomes,p);hold on;plot(outcomes,g,'r-');
title('Probability Density Function');legend('simulated','theory');
xlabel('Possible outcomes');ylabel('Probability of outcomes');

On the other hand, a discrete random variable generates



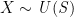


$$ f_X(x)= \begin{cases}\frac{1}{n} & \text{where } x \in {s_1,s_2,…,s_n } \\ 0 & otherwise \end{cases} $$
There exist several methods to generate discrete uniform random numbers and two of them are discussed here. The straightforward method is to use randi function in Matlab that can generate discrete uniform numbers in the integer set



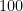


X=ceil(n*rand(1,100));The uniformity test for discrete uniform random numbers can be performed and it is very similar to the code shown for the continuous uniform random variable case. The only difference here is the normalization term. The histogram values should not be normalized by the total area under the histogram curve as in the case of continuous random variables. Rather, the histogram should be normalized by the total number of occurrences in all the bins. We cannot normalized based on the area under the curve, since the bin values are not dense enough (bins are far from each other) for proper calculation of total area. The code snippet is given next. The resulting plot (Figure 2) shows a good match between the simulated and theoretical PMFs.
X=randi(6,100000,1); %Simulate throws of dice,S={1,2,3,4,5,6}
[pmf,edges]=histcounts(X,'Normalization','pdf');%estimated PMF
outcomes = 0.5*(edges(1:end-1) + edges(2:end));%S={1,2,3,4,5,6}
g=1/6*ones(1,6); %Theoretical PMF
bar(outcomes,pmf);hold on;stem(outcomes,g,'r-');
title('Probability Mass Function');legend('simulated','theory');
xlabel('Possible outcomes');ylabel('Probability of outcomes');

Topics in this chapter
| Random Variables - Simulating Probabilistic Systems ● Introduction ● Plotting the estimated PDF ● Univariate random variables □ Uniform random variable □ Bernoulli random variable □ Binomial random variable □ Exponential random variable □ Poisson process □ Gaussian random variable □ Chi-squared random variable □ Non-central Chi-Squared random variable □ Chi distributed random variable □ Rayleigh random variable □ Ricean random variable □ Nakagami-m distributed random variable ● Central limit theorem - a demonstration ● Generating correlated random variables □ Generating two sequences of correlated random variables □ Generating multiple sequences of correlated random variables using Cholesky decomposition ● Generating correlated Gaussian sequences □ Spectral factorization method □ Auto-Regressive (AR) model |
Books by the author
 Wireless Communication Systems in Matlab Second Edition(PDF) Note: There is a rating embedded within this post, please visit this post to rate it. |  Digital Modulations using Python (PDF ebook) Note: There is a rating embedded within this post, please visit this post to rate it. |  Digital Modulations using Matlab (PDF ebook) Note: There is a rating embedded within this post, please visit this post to rate it. |
| Hand-picked Best books on Communication Engineering Best books on Signal Processing |
||



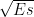

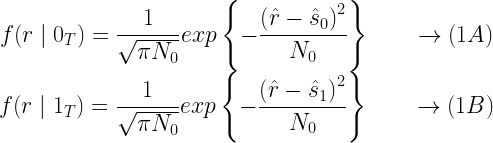














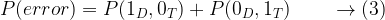











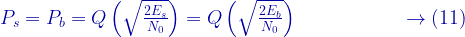

























![E\left[X \right] = \int_{-\infty }^{\infty}xf_X(x)dx](https://s0.wp.com/latex.php?latex=E%5Cleft%5BX+%5Cright%5D+%3D+%5Cint_%7B-%5Cinfty+%7D%5E%7B%5Cinfty%7Dxf_X%28x%29dx+&bg=ffffff&fg=000&s=1&c=20201002)

![E\left[X \right] = \mu{_X} = \sum_{-\infty }^{\infty}x_{i}p_{i}](https://s0.wp.com/latex.php?latex=E%5Cleft%5BX+%5Cright%5D+%3D+%5Cmu%7B_X%7D+%3D+%5Csum_%7B-%5Cinfty+%7D%5E%7B%5Cinfty%7Dx_%7Bi%7Dp_%7Bi%7D+&bg=ffffff&fg=000&s=1&c=20201002)

![var \left[X\right] = \int_{-\infty }^{\infty} \left(x - E\left[X \right] \right)^2 f_X(x) dx](https://s0.wp.com/latex.php?latex=var+%5Cleft%5BX%5Cright%5D+%3D+%5Cint_%7B-%5Cinfty+%7D%5E%7B%5Cinfty%7D+%5Cleft%28x+-+E%5Cleft%5BX+%5Cright%5D+%5Cright%29%5E2+f_X%28x%29+dx+&bg=ffffff&fg=000&s=1&c=20201002)

![var \left[X\right] = {\sigma^2}_X = \sum_{-\infty }^{\infty} \left( x_i - \mu_X\right)^2 p_{i}](https://s0.wp.com/latex.php?latex=var+%5Cleft%5BX%5Cright%5D+%3D+%7B%5Csigma%5E2%7D_X+%3D+%5Csum_%7B-%5Cinfty+%7D%5E%7B%5Cinfty%7D+%5Cleft%28+x_i+-+%5Cmu_X%5Cright%29%5E2+p_%7Bi%7D+&bg=ffffff&fg=000&s=1&c=20201002)




![E\left[cX\right] = c E\left[X\right]](https://s0.wp.com/latex.php?latex=E%5Cleft%5BcX%5Cright%5D+%3D+c+E%5Cleft%5BX%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)

![E\left[X+c\right] = E\left[X\right]+c](https://s0.wp.com/latex.php?latex=E%5Cleft%5BX%2Bc%5Cright%5D+%3D+E%5Cleft%5BX%5Cright%5D%2Bc+&bg=ffffff&fg=000&s=1&c=20201002)

![E\left[c\right] = c](https://s0.wp.com/latex.php?latex=E%5Cleft%5Bc%5Cright%5D+%3D+c+&bg=ffffff&fg=000&s=1&c=20201002)

![var\left[cX\right] = c^2 var\left[X\right]](https://s0.wp.com/latex.php?latex=var%5Cleft%5BcX%5Cright%5D+%3D+c%5E2+var%5Cleft%5BX%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)

![var\left[X+c\right] = var\left[X\right]](https://s0.wp.com/latex.php?latex=var%5Cleft%5BX%2Bc%5Cright%5D+%3D+var%5Cleft%5BX%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)

![var\left[c\right] = 0](https://s0.wp.com/latex.php?latex=var%5Cleft%5Bc%5Cright%5D+%3D+0+&bg=ffffff&fg=000&s=1&c=20201002)











