[ratings]
Matrix inversion is seen ubiquitously in signal processing applications. For example, matrix inversion is an important step in channel estimation and equalization. For instance, in GSM normal burst, 26 bits of training sequence are put in place with 114 bits of information bits. When the burst travels over the air interface (channel), it is subject to distortions due to channel effect like Inter Symbol Interference (ISI). It becomes necessary to estimate the channel impulse response (H) and equalize the effects of the channel, before attempting to decode/demodulate the information bits. The training bits are used to estimate the channel impulse response.
If the transmitted signal “x” travels over a multipath fading channel (H) with AWGN noise “w”, the received signal is modeled as
$latex y = Hx + w &s=2$
A Minimum Mean Square Error (MMSE) linear equalizer employed to cancel out the effects of ISI, attempts to minimize the error between equalizer output – “$latex \hat{x} $” and the transmitted signal “$latex x $”. If the AWGN noise power is $latex \sigma^2 $, then the equalizer is represented by the following equation[1].
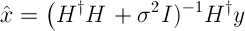
Note that the expression involves the computation of matrix inversion – 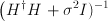 .
.
Matrix inversion is a tricky subject. Not all matrices are invertible. Furthermore, ordinary matrix inversion technique of finding the adjoint of a matrix and using it to invert the matrix will consume lots of memory and computation time. Physical layer algorithm (PHY) designers typically use Cholesky decomposition to invert the matrix. This helps to reduce the computational complexity of matrix inversion.
Reference:
See Also:
[table “7” not found /][table “6” not found /]