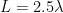Key focus: How to implement the basic addition operation on two discrete time signal sequences. Python code for signal addition is provided.
Signal addition
Given two discrete-time sequences \(x_1[n]\) and \(x_2[n]\), the addition of these two sequences is represented as \(x_1[n]+ x_2[n]\). The start of the sample at \(n=0\) can be different for these two sequences.
the position of the sample at \(n=0\) is different in these sequences. Also, the length of these sequences are different.
The addition operation should take these differences into account. The following python code adjusts for these differences before computing the addition operation. It creates two sequences y1[n]y1[n] and y2[n]y2[n] of equal length that spans the minimum and maximum indices of x1[n]x1[n] and x2[n]x2[n]. The sequences y1[n]y1[n] and y2[n]y2[n] are first filled with zeros and then the sequences x1[n]x1[n] & x2[n]x2[n] are copied over to y1[n]y1[n] & y2[n]y2[n] at corresponding positions. The final result is computed as the sum of y1[n]y1[n] and y2[n]y2[n].
import numpy as np
def signal_add(x1, n1, x2, n2):
'''
Computes y(n) = x1(n) + x2(n)
---------------------------------
[y, n] = signal_add(x1, n1, x2, n2)
Parameters
----------
n1 = indices of first sequence x1
n2 = indices of second sequence x2
x1 = first sequence defined for indices n1
x2 = second sequence defined for indices n2
Returns
-------
y = output sequence defined over indices n that
covers whole range of n1 and n2
'''
n_start = min(min(n1), min(n2))
n_end = max(max(n1), max(n2))
n = np.arange(n_start, n_end + 1) # duration of y(n)
y1 = np.zeros_like(n, dtype='complex_')
y2 = np.zeros_like(n, dtype='complex_')
mask1 = (n >= n1[0]) & (n <= n1[-1])
mask2 = (n >= n2[0]) & (n <= n2[-1])
y1[np.where(mask1)[0]] = x1[np.where(n1 == n[mask1])]
y2[np.where(mask2)[0]] = x2[np.where(n2 == n[mask2])]
y = y1 + y2
return y, n
The following code snippet uses the function above to compute the addition of two sequences \(x_1[n]\) and \(x_2[n]\), defined as
\[\begin{align} x_1[n] &= cos \left( 0.03 \pi n \right), & 0 \leq n \leq 50 \\ x_2[n] &= e^{0.06 n}, & -30 \leq 0 \leq n \end{align}\]
In digital signal processing, we utilize various elementary sequences for the purpose of analysis. In this series, we will see such sequences. One such elementary sequence is the real-valued exponential sequence. (see the articles on unit sample sequence, unit step sequence, real-valued exponential sequence)
A complex-valued exponential sequence in signals and systems is a discrete-time sequence that exhibits complex exponential behavior. It is characterized by complex numbers raised to the power of the index. The general form of a complex-valued exponential sequence is given by:
\[x[n] = e^{ \alpha n }e^{ j \omega n } = e^{\left( \alpha + j \omega \right) n } = cos \left[ \left( \alpha + j \omega \right) n \right] + j sin \left[ \left( \alpha + j \omega \right) n \right], \; \forall n \]
where:
x[n] is the value of the sequence at index n.
\(\alpha\) acts as an attenuation factor if \(\alpha \lt 0\) or as an amplification factor for \(\alpha \gt 0\)
\(j\) is the indeterminate satisfying \(j^2 = -1\) (imaginary unit).
\(\omega\) is the angular frequency in radians per sample.
The complex nature is indicated by the presence of the indeterminate \(j\) in the exponent.
The python function to generate a complex exponential function is given below
import numpy as np
import matplotlib.pyplot as plt
def complex_exponential_sequence(n, alpha, omega):
return np.exp((alpha + 1j * omega) * n)
n = np.linspace(0, 40, 1000)
alpha = 0.025; omega = 0.75
x = complex_exponential_sequence(n, alpha, omega)
Plot of real and imaginary parts of the sequence generated for various values of \(\alpha\) and \(\omega\) is given next
Figure 1: Complex exponential sequence for various values of \(\alpha\) and \(\omega\)
From Figure 1, we see that the variable \(\alpha\) governs the decay or growth of the sequence in time and the \(\omega\) controls the oscillation frequency on a circle in the complex plane.
The 3D views of the complex sequence for various values of \(\alpha\) and \(\omega\) are illustrated next.
When (\(\alpha=0\)), the sequence remains the on circle in the complex plane.
Figure 2: A neutral sequence (\(\alpha =0\) and \(\omega = 1\))
When \(\alpha \gt 0 \), the sequence grows exponentially and it spirals out.
Figure 3: A growing sequence (\(\alpha >0\) and \(\omega = 0.75 \))
When \(\alpha \lt 0 \), the sequence decays exponentially.
Figure 4: A decaying sequence (\(\alpha <0\) and \(\omega = 2.5 \))
Applications
Complex exponential sequences have various applications in modeling and signal processing. Some of the key applications include:
Signal Analysis and Representation: Complex exponential sequences form the basis for Fourier analysis, which decomposes a signal into a sum of sinusoidal components. The complex exponential sequence (\(e^{j\omega n}\)) serves as the building block for representing and analyzing signals in the frequency domain.
System Modeling and Analysis: These sequences play a fundamental role in modeling and analyzing linear time-invariant (LTI) systems. By applying complex exponential inputs to a system and observing the resulting outputs, one can determine the system’s frequency response and characterize its behavior in terms of amplitude and phase shifts at different frequencies.
Digital Filtering: Complex exponential sequences are utilized in digital filtering algorithms, such as the Fourier transform-based frequency domain filtering and the Z-transform-based discrete-time filtering. These sequences help design filters for various applications, such as noise removal, equalization, and signal enhancement.
Modulation Techniques: These sequences are fundamental in various modulation schemes used in communication systems. For instance, in amplitude modulation (AM), frequency modulation (FM), and phase modulation (PM), the modulating signals are typically expressed as complex exponential sequences that are mixed with carrier signals to encode information.
Control Systems: Complex exponential sequences are relevant in control system analysis and design. In control theory, the Laplace transform, which involves complex exponentials, is used to analyze system dynamics, stability, and transient response. The concept of the complex plane, where complex exponentials reside, is crucial in control system design and stability analysis.
Digital Signal Processing (DSP): These sequences find extensive use in various DSP applications, including digital audio processing, image processing, speech recognition, and data compression. Techniques like the discrete Fourier transform (DFT) and fast Fourier transform (FFT) exploit complex exponentials to efficiently analyze signals in the frequency domain.
In digital signal processing, we utilize various elementary sequences for the purpose of analysis. In this series, we will see such sequences. One such elementary sequence is the real-valued exponential sequence. (see the articles on unit sample sequence, unit step sequence, complex exponential sequence)
An exponential sequence in signals and systems is a discrete-time sequence that exhibits exponential growth or decay. It is characterized by a constant base raised to the power of the index. The general form of the sequence is given by:
\[x[n] = A \cdot r^n, \quad \forall n; \quad r \in \mathbb{R}\]
where:
\(x[n]\) is the value of the sequence at index \(n\).
\(A\) is the initial amplitude or value at \(n = 0\).
\(r\) is the constant base, which determines the growth or decay behavior.
\(n\) represents the index of the sequence.
If the value of r is greater than 1, the sequence grows exponentially as n increases, resulting in exponential growth. Conversely, if r is between 0 and 1, the sequence decays exponentially, approaching zero as n increases.
Exponential sequences find various applications in fields such as finance, physics, and telecommunications. In signal processing and system analysis, these sequences are fundamental components used to model and analyze various system behaviors, such as stability, convergence, and frequency response.
Python code that implements a real-valued exponential sequence for various values of \(r\).
import matplotlib.pyplot as plt
import numpy as np
def exponential_sequence(n, A, r):
return A * np.power(r, n)
# Define the range of n
n = np.arange(0, 25)
# Define the values of r
r_values = [0.5, 0.8, 1.2]
# Plotting the exponential sequences for various values of r
fig, axs = plt.subplots(len(r_values), 1, figsize=(8, 6))
for i, r in enumerate(r_values):
# Generate the exponential sequence for the current value of r
x = exponential_sequence(n, 1, r)
# Plot the exponential sequence in the current subplot
axs[i].stem(n, x, 'k', use_line_collection=True)
axs[i].set_xlabel('n')
axs[i].set_ylabel(f'x[n], r={r}')
axs[i].set_title(f'Exponential Sequence, r={r}')
axs[i].grid(True)
# Adjust spacing between subplots
plt.tight_layout()
# Display the plot
plt.show()
Figure 1: Real-valued exponential sequence \(x[n] = A \cdot r^n\) for \(r = 0.5, 0.8, 1.5\)
Applications
Real-valued exponential sequences have various applications in different fields, including:
Signal Processing: Exponential sequences are used to model and analyze signals in fields like audio processing, image processing, and telecommunications. They are fundamental in Fourier analysis, frequency response analysis, and filter design.
System Analysis: Exponential sequences are essential in understanding and characterizing the behavior of linear time-invariant (LTI) systems. They help analyze system stability, impulse response, and frequency response.
Finance: Exponential sequences find applications in finance and economics for modeling compound interest, population growth, investment returns, and other exponential growth/decay phenomena.
Physics: In physics, exponential sequences are used to describe natural phenomena such as radioactive decay, charging/discharging of capacitors, and decay of electrical or mechanical systems.
Control Systems: Exponential sequences play a crucial role in control systems engineering. They are used to model system dynamics, analyze stability, and design controllers for desired response characteristics.
Probability and Statistics: Exponential sequences are utilized in probability and statistics to model various distributions, including the exponential distribution, which represents events occurring randomly and independently over time.
Machine Learning: Exponential sequences are used in machine learning algorithms for tasks such as feature scaling, regularization, and gradient descent optimization.
These are just a few examples of the broad range of applications where real-valued exponential sequences are utilized. Their ability to represent exponential growth or decay makes them a valuable tool for modeling and understanding dynamic systems and phenomena in various disciplines.
In digital signal processing, we utilize various elementary sequences for the purpose of analysis. In this series, we will see such sequences. One such elementary sequence is the unit step sequence (see the articles on unit sample sequence, unit step sequence, real-valued exponential sequence, complex exponential sequence).
Unit Step Sequence
A unit step sequence is a discrete-time signal that represents a step function. In discrete-time signal processing, a sequence is a set of values indexed by integers. A unit step sequence, denoted as u[n], is defined as follows:
In this definition, the value of \(u[n]\) is 0 for negative values of \(n\) (\(n \lt 0\)), and it is 1 for non-negative values of \(n (n \geq 0)\). The up-arrow indicates the sample at \(n=0\)
Graphically, the sequence looks like a step function, where the value remains zero for negative indices and abruptly jumps to 1 at n=0, continuing at that value for positive indices.
In the equation above, the sequence value of 1 start at index 0. In signal processing, the starting place (where the value 1 starts) can be shifted. The generalized formula for generated a shifted sequence will be
\[ u[n – n_0] = \begin{cases} 1 , & \quad n \geq n_0 \\ 0, & \quad n \lt n_0\end{cases}\]
The following python code implements a unit step sequence over the interval \(n_1 \leq n \leq n_2\)
import matplotlib.pyplot as plt
import numpy as np
def unit_step_sequence(n0, n1, n2):
"""
Generate unit step sequence u(n - n0); n1<=n<=n
n0 = number of samples to offset/shift
n1 = starting number to generate the sequence index
n2 = ending number to generate the sequence index
"""
n = np.arange(n1,n2+1)
u = np.zeros_like(n)
u[n >= n0] = 1
return u
# Generate the shifted unit step sequence for a given range and shift value
n0 = 2 # Shift value
n1 = -3
n2 = 9
u = unit_step_sequence(n0, n1, n2)
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
# Plotting the shifted unit step sequence
plt.stem(np.arange(n1,n2+1), u,'r', markerfmt='o', basefmt='k', use_line_collection=True)
plt.xlabel('n')
plt.ylabel(r'$u[n-n_0]$')
plt.title(r'Discrete-time Unit Step Sequence $u[n-2]$')
plt.grid(True)
plt.show()
Figure 1: Discrete unit step sequence \(u[n-n_0]\); shifted by \(n_0=2\), generated over the interval \(-3 <= n <= 9\)
Applications
The unit step sequence is often used as a fundamental building block in signal processing and system analysis. It serves as a basic reference for studying and analyzing other signals and systems. By manipulating the sequence, one can derive other useful sequences and functions, such as shifted step sequences, ramp sequences, and more complex signals.
This sequence is particularly important in the field of discrete-time systems, where it is used to analyze system behavior and characterize properties like stability, causality, and linearity. It is also employed in various applications, such as digital filters, signal modeling, and signal reconstruction.
In digital signal processing, we utilize various elementary sequences for the purpose of analysis. In this series, we will see such sequences. One such elementary sequence is the unit sample sequence (see the articles on unit sample sequence, unit step sequence, real-valued exponential sequence, complex exponential sequence)
A unit sample sequence, also known as an impulse sequence or delta sequence, is a discrete sequence that consists of a single sample with the value of 1 at a specific index, and all other samples are zero. It is commonly represented as a discrete-time impulse function or delta function.
Mathematically, a unit sample sequence can be defined as:
\(x[n]\) represents the value of the sequence at index \(n\).
\(δ[n]\) is the discrete-time impulse function or delta function.
\(n_0\) is the index at which the impulse occurs. At this index, \(x[n]\) has the value of 1, and for all other indices, \(x[n]\) is zero.
This sequence represents a localized impulse or sudden change at that particular index. The unit sample sequence is commonly used in signal processing and system analysis to study the response of systems to impulses or abrupt changes. It serves as a fundamental tool for representing and analyzing signals and systems.
In python, the scipy.signal.unit_impulse function can be used to generate an impulse sequence in SciPy. For 1-D signals, the first argument to the function is the number of samples requested for generating the unit_impulse and the second argument is the offset (i.e, \(n_0\))
import matplotlib.pyplot as plt
import numpy as np
from scipy import signal
n = 11 #number of samples
n0 = 5 # Offset (Shift index)
imp = signal.unit_impulse(n, n0) #unit impulse
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
plt.stem(np.arange(0,n),imp,'r', markerfmt='ro', basefmt='k')
plt.xlabel('Sample #')
plt.ylabel(r'$\delta[n-n_0]$')
plt.title('Discrete-time Unit Impulse')
plt.show()
Figure 1: Discrete-time unit impulse
Applications of unit sample sequences
Unit sample sequences, also known as impulse sequences, have several applications in digital signal processing. Here are a few common applications:
System Analysis: Unit sample sequences are used to analyze and characterize the behavior of systems, such as filters and signal processors, in response to impulses or sudden changes.
Convolution: Unit sample sequences are essential in the mathematical operation of convolution, which is used for filtering, signal analysis, and processing tasks.
Signal Reconstruction: Unit sample sequences are employed in reconstructing continuous signals from their sampled versions using techniques like impulse sampling and interpolation.
System Identification: Unit sample sequences can be utilized to estimate the impulse response of a system, allowing for system identification and modeling.
These are just a few examples of the diverse applications of unit sample sequences in digital signal processing. They serve as fundamental tools for analyzing signals, characterizing systems, and performing various signal processing operations.
Orthogonality is a mathematical principle that signifies the absence of correlation or relationship between two vectors (signals). It implies that the vectors or signals involved are mutually independent or unrelated.
Two vectors (signals) A and B are said to be orthogonal (perpendicular in vector algebra) when their inner product (also known as dot product) is zero.
To find the dot product of two vectors, you need to multiply their corresponding components and then sum the results. Here’s the general formula (in matrix notation) for checking the orthogonality of two complex valued vectors \(\vec{a}\) and \(\vec{b}\):
Here’s an example code snippet in Python that demonstrates to check if two vectors given as lists are orthogonal.
import numpy as np
import matplotlib.pyplot as plt
def dot_product(vector1, vector2):
if len(vector1) != len(vector2):
raise ValueError("Vectors must have the same length.")
return sum(x * y for x, y in zip(vector1, vector2))
def are_orthogonal(vector1, vector2):
result = dot_product(vector1, vector2)
return result == 0
# Example vectors
vectorA = [-2, 3]
vectorB = [3, 2]
# Check if vectors are orthogonal
if are_orthogonal(vectorA, vectorB):
print("The vectors are orthogonal.")
else:
print("The vectors are not orthogonal.")
# Plotting the vectors
origin = [0], [0] # Origin point for the vectors
plt.quiver(*origin, vectorA[0], vectorA[1], angles='xy', scale_units='xy', scale=1, color='r', label='Vector A')
plt.quiver(*origin, vectorB[0], vectorB[1], angles='xy', scale_units='xy', scale=1, color='b', label='Vector B')
plt.xlim(-5, 5)
plt.ylim(-5, 5)
plt.xlabel('x')
plt.ylabel('y')
plt.title('Plot of Vectors')
plt.grid(True)
plt.legend()
plt.show()
Orthogonality of Continuous functions
Orthogonality, in the context of functions, can be seen as a broader concept akin to the orthogonality observed in vectors. Geometrically, orthogonal vectors are perpendicular to each other since their dot product equals zero.
When computing the dot product of two vectors, their components are multiplied and summed. However, when considering the “dot” product of functions, a similar approach is taken. Functions are treated as if they were vectors with an infinite number of components, and the dot product is obtained by multiplying the functions together and integrating over a specific interval.
Let f(t) and g(t) are two continuous functions (imagined as two vectors) on the closed interval [a,b] (i.e a ≤ t ≤ b). For the functions to be orthogonal in the given interval, their dot product should be zero
\[ \left<f,g\right> = \int_a^b f(t) g(t) dt = 0 \Rightarrow \text{f(t) and g(t) are orthogonal}\]
Here is a small python script to check if two given functions are orthogonal
Python Script
import sympy
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('seaborn-talk')
print(plt.style.available)
# Test the orthogonality of functions
x = sympy.Symbol('x')
f = sympy.sin(x) # First function
g = sympy.cos(2*x) # Second function
a = 0 # interval lower limit
b = 2*sympy.pi # interval upper limit
interval = (0, 2*sympy.pi) # Integration interval
inner_product = sympy.integrate(f*g, (x, interval[0], interval[1]))
if sympy.N(inner_product) == 0:
print("The functions",str(f),"and",str(g),"are orthogonal over the interval [",str(a), ",",str(b),"].")
else:
print("The functions",str(f),"and",str(g),"are not orthogonal over the interval [",str(a), ",",str(b),"].")
# Plotting the functions
x_vals = np.linspace(float(interval[0]), float(interval[1]), 100)
f_vals = np.sin(x_vals)
g_vals = np.cos(2*x_vals)
plt.plot(x_vals, f_vals, label=str(f))
plt.plot(x_vals, g_vals, label=str(g))
plt.plot(x_vals, f_vals*g_vals, label=str(f)+str(g))
plt.xlabel('x')
plt.ylabel('Function values')
plt.legend()
plt.title('Plot of functions')
plt.grid(True)
plt.show()
Output
The functions sin(x) and cos(2*x) are orthogonal over the interval [ 0 , 2*pi ]
Orthogonality of discrete functions
To check the orthogonality of discrete functions, you can use the concept of the inner product (same as above). In discrete settings, the inner product can be thought of as the sum of the element-wise products of the function values at corresponding points.
Here’s an example code snippet in Python that demonstrates how to check the orthogonality of two discrete functions:
import numpy as np
def inner_product(f, g):
if len(f) != len(g):
raise ValueError("Functions must have the same length.")
return np.sum(f * g)
def are_orthogonal(f, g):
result = inner_product(f, g)
return result == 0
# Example functions (discrete)
f = np.array([1, 0, -1, 0])
g = np.array([0, 1, 0, -1])
# Check if functions are orthogonal
if are_orthogonal(f, g):
print("The functions are orthogonal.")
else:
print("The functions are not orthogonal.")
Keywords: Markov Chain, Python, probability, data analysis, data science
Markov Chain
Markov chain is a probabilistic models that describe a sequence of observations whose occurrence are statistically dependent only on the previous ones. This article is about implementing Markov chain in Python
We will model a car’s behavior using the same transition matrix and starting probabilities described in the earlier post for modeling the corresponding Markov chain model (refer Figure 1). The matrix defines the probabilities of transitioning between different states, including accelerating, maintaining a constant speed, idling, and braking.
Figure 1: Modeling a car’s behavior using Markov chain model
The starting probabilities indicate that the car starts in the break state with probability 1, which means it is already stopped and not moving.
Python implementation
Here’s the sample code in Python that implements the above model:
import random
# Define a transition matrix for the Markov chain
transition_matrix = {
'accelerate': {'accelerate': 0.3, 'constant speed': 0.2, 'idling': 0 , 'break': 0.5 },
'constant speed': {'accelerate': 0.1, 'constant speed': 0.4, 'idling': 0 , 'break': 0.5 },
'idling': {'accelerate': 0.8, 'constant speed': 0, 'idling': 0.2 , 'break': 0 },
'break': {'accelerate': 0.4, 'constant speed': 0.05, 'idling': 0.5 , 'break': 0.05 },
}
# Define starting probabilities for each state
starting_probabilities = {'accelerate': 0, 'constant speed': 0, 'idling': 0, 'break': 1}
# Choose the starting state randomly based on the starting probabilities
current_state = random.choices(
population=list(starting_probabilities.keys()),
weights=list(starting_probabilities.values())
)[0]
# Generate a sequence of states using the transition matrix
num_iterations = 10
for i in range(num_iterations):
print(current_state)
next_state = random.choices(
population=list(transition_matrix[current_state].keys()),
weights=list(transition_matrix[current_state].values())
)[0]
current_state = next_state
In this example, we use the random.choices() function to choose the starting state randomly based on the starting probabilities. We then generate a sequence of 10 states using the transition matrix, and print out the sequence of states as they are generated. A sample output of the program is given below.
Keywords: Spectrogram, signal processing, time-frequency analysis, speech recognition, music analysis, frequency domain, time domain, python
Introduction
A spectrogram is a visual representation of the frequency content of a signal over time. Spectrograms are widely used in signal processing applications to analyze and visualize time-varying signals, such as speech and audio signals. In this article, we will explore the concept of spectrograms, how they are generated, and their applications in signal processing.
What is a Spectrogram?
A spectrogram is a two-dimensional representation of the frequency content of a signal over time. The x-axis of a spectrogram represents time, while the y-axis represents frequency. The color or intensity of each point in the spectrogram represents the magnitude of the frequency content at that time and frequency.
How are Spectrograms Generated?
Spectrograms are typically generated using a mathematical operation called the short-time Fourier transform (STFT).
The STFT is a variation of the Fourier transform that computes the frequency content of a signal in short, overlapping time windows. The resulting frequency content is then plotted over time to generate the spectrogram.
where \(STFT(x(t),f \tau)\) is the STFT of the signal \(x(t)\) with respect to frequency f and time shift \(\tau\), \(\omega\) is the frequency variable, \(w(t-\tau)\) is the window function, and \(e^{-j\omega t}\) is the complex exponential that represents the frequency component at \(\omega\).
The STFT is computed by dividing the signal \(x(t)\) into overlapping windows of length \(\tau\) and applying the Fourier transform to each window. The window function \(w(t-\tau)\) is used to taper the edges of the window and minimize spectral leakage. The resulting complex-valued STFT is a function of both frequency and time, and can be visualized as a spectrogram.
In practice, the STFT is computed using a sliding window that moves over the signal in small increments. The size and overlap of the window determine the frequency and temporal resolution of the spectrogram. A larger window size provides better frequency resolution but poorer temporal resolution, while a smaller window size provides better temporal resolution but poorer frequency resolution.
The equation for computing spectrogram can be expressed as:
\[S(f, t) = |STFT(x(t), f, \tau)|^2\]
where \(S(f, t)\) is the spectrogram, STFT is the short-time Fourier transform, \(x(t)\) is the input signal, f is the frequency, and \(\tau\) is the time shift or window shift.
The STFT is calculated by dividing the signal into overlapping windows of length \(\tau\) and computing the Fourier transform of each window. The magnitude squared of the resulting complex-valued STFT is then used to compute the spectrogram. The spectrogram provides a time-frequency representation of the signal, where the magnitude of the STFT at each time and frequency point represents the strength of the signal at that particular time and frequency.
Spectrogram using python
To generate a spectrogram in Python, we can use the librosa library which provides an easy-to-use interface for computing and visualizing spectrograms. Here’s an example program that generates a spectrogram for an audio signal:
Figure 1: Spectrogram of an example audio file using librosa python library
In this program, we first load an audio file using the librosa.load() function, which returns the audio signal (y) and its sampling rate (sr). We then compute the spectrogram using the librosa.feature.melspectrogram() function, which computes a mel-scaled spectrogram of the audio signal.
To convert the power spectrogram to decibels, we use the librosa.power_to_db() function, which scales the spectrogram to decibels relative to a maximum reference power. We then plot the spectrogram using the librosa.display.specshow() function, which displays the spectrogram as a heatmap with time on the x-axis and frequency on the y-axis.
Finally, we add a colorbar and title to the plot using the fig.colorbar() and ax.set_title() functions, respectively, and display the plot using the fig.show() function.
Note that this program assumes that the audio file is in OGG format and is located in the current working directory. If the file is in a different format or location, you will need to modify the librosa.load() function accordingly. The sample audio file can be obtained from the librosa github repository.
Applications of Spectrograms in Signal Processing
Spectrograms are widely used in signal processing applications, particularly in speech and audio processing. Some common applications of spectrograms include:
Music Analysis: Spectrograms are used to analyze the frequency content of music signals, which can provide information about the genre, tempo, and instrument composition of the music.
Noise Reduction: Spectrograms can be used to identify and remove noise from a signal by filtering out the frequency components that correspond to the noise.
Voice Activity Detection: Spectrograms can be used to detect the presence of speech in a noisy environment by analyzing the frequency content of the signal.
Conclusion
Spectrograms are a powerful tool in signal processing for analyzing and visualizing time-varying signals. They provide a detailed view of the frequency content of a signal over time, enabling accurate analysis and interpretation of complex signals such as speech and audio signals. With their numerous applications in speech and audio processing, spectrograms are an essential tool for researchers and practitioners in these fields.
Key focus: Briefly look at linear antennas and various dipole antennas and plot the normalized power gain pattern in polar plot and three dimensional plot.
Linear antennas
Linear antennas are electrically thin antennas whose conductor diameter is very small compared to the wavelength of the radiation λ.
Viewed in a spherical coordinate system (Figure 1), for linear antenna, the antenna is oriented along the z-axis such that the radiation vector has only components along directions of the radial distance Fr and the polar angle Fθ. The radiation vector is determined by the current density J which is characterized by the current distribution I(z)[1].
Figure 1: Electrical and magnetic fields from a current source
Figure 2: Linear antenna element
Hertzian dipole (infinitesimally small dipole)
Hertzian dipole is the simplest configuration of a linear antenna used for study purposes. It is an infinitesimally small (typically [2]) antenna element that has the following current density distribution
\[I(z) = I \; L\; \delta(z)\]
The radiation vector Fz (θ) is given by [1]
\[F_z(\theta) = \int_{-L/2}^{L/2} I(z^{'}) e^{jk_z z^{'}} dz{'} = \int_{-L/2}^{L/2} I L \delta(z{'}) e^{jkz{'}cos \theta} dz{'} = IL\]
The normalized power gain of the Hertzian dipole is [2]
\[g(\theta) = C_0 sin^{2} \theta \]
where, C0 is a constant chosen to make maximum of g(θ) equal to unity and θ is the polar angle in the spherical coordinate system.
Center-fed dipole (standing wave antenna)
For the center-fed small dipole antenna, the current distribution is assumed to be a standing wave. Defining k = 2π/λ as the wave number and h = L/2 as the half-length of the antenna, the current distribution and the normalized power gain g(θ) are given by
\[I(z) = I \; sin \left[ k \left(L/2 – |z| \right) \right]\]
\[g(\theta) =C_n \left|\frac{cos (k h \; cos \theta) – cos( k h) }{sin \theta} \right| ^2\]
where, Cn is a constant chosen to make maximum of g(θ) equal to unity and θ is the polar angle in the spherical coordinate system.
Figure 3: Center-fed small dipole
For half-wave dipole, set L = λ/2 or kl = π. Therefore, the current distribution for half-wave dipole shrinks to
Let’s plot the normalized power gain pattern of Hertzian & Half-wave dipole antennas in polar plot and three dimensional plot.
Check out my Google colab for the python code to plot the normalized power gain in polar plot as well as three dimensional plot. The results are given below.
Figure 4: Hertzian dipole – power gain pattern (polar plot)
Figure 5: Hertzian dipole – power gain pattern (3D plot)
Figure 6: Half-wave dipole – power gain pattern (polar plot)
Figure 7: Half-wave dipole power gain 3d plot (cartesian coordinates)
Figure 8: Normalized power gain pattern for dipole of length
Figure 9: Normalized power gain pattern for dipole of length (3D projection)
Rate this article: Note: There is a rating embedded within this post, please visit this post to rate it.
Line code is the signaling scheme used to represent data on a communication line. There are several possible mapping schemes available for this purpose. Lets understand and demonstrate line code and PSD (power spectral density) in Matlab & Python.
Line codes – requirements
When transmitting binary data over long distances encoding the binary data using line codes should satisfying following requirements.
All possible binary sequences can be transmitted.
The line code encoded signal must occupy small transmission bandwidth, so that more information can be transmitted per unit bandwidth.
Error probability of the encoded signal should be as small as possible
Since long distance communication channels cannot transport low frequency content (example : DC component of the signal , such line codes should eliminate DC when encoding). The power spectral density of the encoded signal should also be suitable for the medium of transport.
The receiver should be able to extract timing information from the transmitted signal.
Guarantee transition of bits for timing recovery with long runs of 1s and 0s in the binary data.
Support error detection and correction capability to the communication system.
Unipolar Non-Return-to-Zero (NRZ) level and Return-to-Zero (RZ) level codes
Unipolar NRZ(L) is the simplest of all the line codes, where a positive voltage represent binary bit 1 and zero volts represents bit 0. It is also called on-off keying.
In unipolar return-to-zero (RZ) level line code, the signal value returns to zero between each pulse.
Unipolar Non Return to Zero (NRZ) and Return to Zero (RZ) line code – 5V peak voltage
For both unipolar NRZ and RZ line coded signal, the average value of the signal is not zero and hence they have a significant DC component (note the impulse at zero frequency in the power spectral density (PSD) plot).
The DC impulses in the PSD do not carry any information and it also causes the transmission wires to heat up. This is a wastage of communication resource.
Unipolar coded signals do not include timing information, therefore long runs of 0s and 1s can cause loss of synchronization at the receiver.
Power spectral density of unipolar NRZ line code
Power spectral density of unipolar RZ line code
Bipolar Non-Return-to-Zero (NRZ) level code
In bipolar NRZ(L) coding, binary bit 1 is mapped to positive voltage and bit 0 is mapped to negative voltage. Since there are two opposite voltages (positive and negative) it is a bipolar signaling scheme.
Bipolar Non Return to Zero (NRZ) and Return to Zero (RZ) line code – 5V peak voltage
Evident from the power spectral densities, the bipolar NRZ signal is devoid of a significant impulse at the zero frequency (DC component is very close to zero). Furthermore, it has more power than the unipolar line code (note: PSD curve for bipolar NRZ is slightly higher compared to that of unipolar NRZ). Therefore, bipolar NRZ signals provide better signal-to-noise ratio (SNR) at the receiver.
Bipolar NRZ signal lacks embedded clock information, which posses synchronization problems at the receiver when the binary information has long runs of 0s and 1s.
Comparing power spectral densities of bipolar NRZ and unipolar NRZ line codes
Alternate Mark Inversion (AMI)
AMI is a bipolar signaling method, that encodes binary 0 as 0 Volt and binary 1 as +ve and -ve voltage (alternating between successive 1s).
Alternate Mark Inversion (AMI) line code – 5V peak voltage
AMI eliminates DC component. Evident from the PSD plots below, AMI has reduced bandwidth (narrower bumps) and faster roll-offs compared to unipolar and bipolar NRZ line codes.
It has inbuilt error detection mechanism: a bit error results in violation of bipolar signaling. It has guaranteed timing transitions even for long runs of 1s and 0s.
Power spectral density of Alternate Mark Inversion (AMI) compared with unipolar and bipolar NRZ line codes
Manchester encoding
In Manchester encoding, the signal for each binary bit contains one transition. For example, bit 0 is represented by a transition from negative to positive voltage and bit 1 is represented by transitioning from one positive to negative voltage. Therefore, it is considered to be self clocking and it is devoid of DC component.
Digitally Manchester encoding can be implemented by XORing the binary data and the clock, followed by mapping the output to appropriate voltage levels.
Manchester encoding
From the PSD plot, we can conclude that Manchester encoded signal occupies twice the bandwidth of Bipolar NRZ(L) encoded signal.
Power spectral density of Manchester encoding compared with that of Bipolar NRZ(L)
Matlab script
In this script, lines codes are simulated and their power spectral density (PSD) are plotted using pwelch command.
%Simulate line codes and plot power spectral densities (PSD)
%Author: Mathuranathan Viswanathan
clearvars; clc;
L = 32; %number of digital samples per data bit
Fs = 8*L; %Sampling frequency
voltageLevel = 5; %peak voltage level in Volts
data = rand(10000,1)>0.5; %random 1s and 0s for data
clk = mod(0:2*numel(data)-1,2).'; %clock samples
ami = 1*data; previousOne = 0; %AMI encoding
for ii=1:numel(data)
if (ami(ii)==1) && (previousOne==0)
ami(ii)= voltageLevel;
previousOne=1;
end
if (ami(ii)==1) && (previousOne==1)
ami(ii)= -voltageLevel;
previousOne = 0;
end
end
%converting the bits to sequences and mapping to voltage levels
clk_sequence=reshape(repmat(clk,1,L).',1,length(clk)*L);
data_sequence=reshape(repmat(data,1,2*L).',1,length(data)*2*L);
unipolar_nrz_l = voltageLevel*data_sequence;
nrz_encoded = voltageLevel*(2*data_sequence - 1);
unipolar_rz = voltageLevel*and(data_sequence,not(clk_sequence));
ami_sequence = reshape(repmat(ami,1,2*L).',1,length(ami)*2*L);
manchester_encoded = voltageLevel*(2*xor(data_sequence,clk_sequence)-1);
figure; %Plot signals in time domain
subplot(7,1,1); plot(clk_sequence(1:800)); title('Clock');
subplot(7,1,2); plot(data_sequence(1:800)); title('Data')
subplot(7,1,3); plot(unipolar_nrz_l(1:800)); title('Unipolar non-return-to-zero level')
subplot(7,1,4); plot(nrz_encoded(1:800)); title('Bipolar Non-return-to-zero level')
subplot(7,1,5); plot(unipolar_rz(1:800)); title('Unipolar return-to-zero')
subplot(7,1,6); plot(ami_sequence(1:800)); title('Alternate Mark Inversion (AMI)')
subplot(7,1,7); plot(manchester_encoded(1:800)); title('Manchester Encoded - IEEE 802.3')
figure; %Plot power spectral density
ns = max(size(unipolar_nrz_l));
na = 16;%averaging factor to plot averaged welch spectrum
w = hanning(floor(ns/na));%Hanning window
%Plot Welch power spectrum using Hanning window
[Pxx1,F1] = pwelch(unipolar_nrz_l,w,[],[],1,'onesided');
[Pxx2,F2] = pwelch(nrz_encoded,w,[],[],1,'onesided');
[Pxx3,F3] = pwelch(unipolar_rz,w,[],[],1,'onesided');
[Pxx4,F4] = pwelch(ami_sequence,w,[],[],1,'onesided'); %
[Pxx5,F5] = pwelch(manchester_encoded,w,[],[],1,'onesided');
semilogy(F1,Pxx1,'DisplayName','Unipolar-NRZ-L');hold on;
semilogy(F2,Pxx2,'DisplayName','Bipolar NRZ(L)');
semilogy(F3,Pxx3,'DisplayName','Unipolar-RZ');
semilogy(F4,Pxx4,'DisplayName','AMI');
semilogy(F5,Pxx5,'DisplayName','Manchester');
legend();
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.