Key focus: Understand step by step, the least squares estimator for parameter estimation. Hands-on example to fit a curve using least squares estimation
Background:
The various estimation concepts/techniques like Maximum Likelihood Estimation (MLE), Minimum Variance Unbiased Estimation (MVUE), Best Linear Unbiased Estimator (BLUE) – all falling under the umbrella of classical estimation – require assumptions/knowledge on second order statistics (covariance) before the estimation technique can be applied. Linear estimators, discussed here, do not require any statistical model to begin with. It only requires a signal model in linear form.
Linear models are ubiquitously used in various fields for studying the relationship between two or more variables. Linear models include regression analysis models, ANalysis Of VAriance (ANOVA) models, variance component models etc. Here, one variable is considered as a dependent (response) variable which can be expressed as a linear combination of one or more independent (explanatory) variables.
Studying the dependence between variables is fundamental to linear models. For applying the concepts to real application, following procedure is required
- Problem identification
- Model selection
- Statistical performance analysis
- Criticism of the model based on statistical analysis
- Conclusions and recommendations
Following text seeks to elaborate on linear models when applied to parameter estimation using Ordinary Least Squares (OLS).
Linear Regression Model
A regression model relates a dependent (response) variable y to a set of k independent explanatory variables {x1, x2 ,…, xk} using a function. When the relationship is not exact, an error term e is introduced.


If the function f is not a linear function, the above model is referred as Non-Linear Regression Model. If f is linear, equation (1) is expressed as linear combination of independent variables xk weighted by unknown vector parameters θ = {θ1, θ2,…, θk } that we wish to estimate.

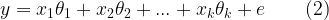
Equation (2) is referred as Linear Regression model. When N such observations are made


where,
yi – response variable
xi – independent variables – known expressed as observed matrix X with rank k
θi – set of parameters to be estimated
e – disturbances/measurement errors – modeled as noise vector with PDF N(0, σ2 I)
It is convenient to express all the variables in matrix form when N observations are made.


Denoting equation (3) using (4),


Except for X which is a matrix, all other variables are column/row vectors.
Ordinary Least Squares Estimation (OLS)
In OLS – all errors are considered equal as opposed to Weighted Least Squares where some errors are considered significant than others.
If



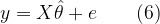
Thus the error vector e can be computed from the observed data matrix y and the estimated
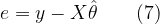
Here, the errors are assumed to be following multivariate normal distribution with zero mean and standard deviation σ2.
To determine the least squares estimator, we write the sum of squares of the residuals (as a function of

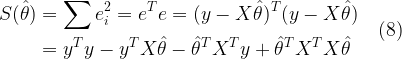
The least squares estimator is obtained by minimizing




Thus, the least squared estimate of θ is given by

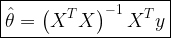
where the operator T denotes Hermitian Transpose (conjugate transpose).
Summary of computations
- Step 1: Choice of variables. Choose the variable to be explained (y) and the explanatory variables { x1, x2 ,…, xk } where x1 is often considered a constant (optional) that always takes the value 1 – this is to incorporate a DC component in the model.
- Step 2: Collect data. Collect n observations of y and for a set of known values of { x1, x2 ,…, xk }. Example: { x1, x2 ,…, xk } is the pilot data in OFDM using which we would like to estimate the channel impulse response θ and y is the received vector of samples. Store the observed data y in an – n⨉1 vector and the data on the explanatory variables in the n⨉k matrix X.
- Step 3: Compute the estimates. Compute the least squares estimates by the formula
The superscript T indicates Hermitian Transpose (conjugate transpose) operation.
Key Points
- We do not need a probabilistic assumption but only a deterministic signal model.
- It has a broader range of applications.
- Least squares is unbiased.
- Estimating the disturbance variance (k variables to estimate and n observations are available).
- To keep the variance low, the number of observations must be greater than the number of variables to estimate.
- The observation matrix X should have maximum rank – this leads to independent rows and columns which always happens with real data. This will make sure (XTX) is invertible.
- Least Squares Estimator can be used in block processing mode with overlapping segments – similar to Welch’s method of PSD estimation.
- Useful in time-frequency analysis.
- Adaptive filters are utilized for non-stationary applications.


LSE applied to curve fitting
Matlab snippet for implementing Least Estimate to fit a curve is given below.
x = -5:.1:5; % set of x- values - known explanatory variables
y = 5.3 + 1.2* x; % Straight line without noise
e=randn(size(y));
y = y + e; % adding random noise to get observed variable -
%Linear model - Y=Xa+e where a - parameters to be estimated
X = [ ones(length(x),1) x']; %first column treated aas all ones since x_1=1
y = y'; %column vector for proper dimension during multiplication
a = inv(X'*X)*X'*y % Least Squares Estimator - equivalent code X\y
h=plot ( x , y , 'o'); %original data
hold on;
plot( x , a(1)+ a(2)*x , 'r-' ); %Fitted line
legend('observed samples',['y=' num2str(a(1)) '+' num2str(a(2)) 'x'])
title('Least Squares Estimate for Curve Fitting');
xlabel('X values');
ylabel('Y values');Simulation Results

Rate this article: Note: There is a rating embedded within this post, please visit this post to rate it.
Related topics:
Books by the author
 Wireless Communication Systems in Matlab Second Edition(PDF) Note: There is a rating embedded within this post, please visit this post to rate it. |  Digital Modulations using Python (PDF ebook) Note: There is a rating embedded within this post, please visit this post to rate it. |  Digital Modulations using Matlab (PDF ebook) Note: There is a rating embedded within this post, please visit this post to rate it. |
| Hand-picked Best books on Communication Engineering Best books on Signal Processing |
||










![\sigma^{2}_{\hat{f}_0}= E \left\{ ( \hat{f}_0 - E [ \hat{f}_0 ] )^2 \right\}](https://s0.wp.com/latex.php?latex=%5Csigma%5E%7B2%7D_%7B%5Chat%7Bf%7D_0%7D%3D+E+%5Cleft%5C%7B+%28+%5Chat%7Bf%7D_0+-+E+%5B+%5Chat%7Bf%7D_0+%5D+%29%5E2+%5Cright%5C%7D+&bg=ffffff&fg=000&s=1&c=20201002)



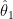


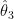






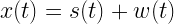

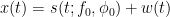

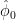

![x[n] = s[n;f_0, \phi_0] + w[n]](https://s0.wp.com/latex.php?latex=x%5Bn%5D+%3D+s%5Bn%3Bf_0%2C+%5Cphi_0%5D+%2B+w%5Bn%5D+&bg=ffffff&fg=000&s=2&c=20201002)

![\hat{f}_{0}=g_{1}(x[0], x[1],x[2],\cdots,x[N-1])=g_{1} \left( \textbf{x} \right)](https://s0.wp.com/latex.php?latex=%5Chat%7Bf%7D_%7B0%7D%3Dg_%7B1%7D%28x%5B0%5D%2C+x%5B1%5D%2Cx%5B2%5D%2C%5Ccdots%2Cx%5BN-1%5D%29%3Dg_%7B1%7D+%5Cleft%28+%5Ctextbf%7Bx%7D+%5Cright%29+&bg=ffffff&fg=000&s=2&c=20201002)

![\hat{\phi}_{0} = g_{2} (x[0], x[1], x[2], \cdots, x[N-1]) = g_{2} \left( \textbf{x} \right)](https://s0.wp.com/latex.php?latex=%5Chat%7B%5Cphi%7D_%7B0%7D+%3D+g_%7B2%7D+%28x%5B0%5D%2C+x%5B1%5D%2C+x%5B2%5D%2C+%5Ccdots%2C+x%5BN-1%5D%29+%3D+g_%7B2%7D+%5Cleft%28+%5Ctextbf%7Bx%7D+%5Cright%29+&bg=ffffff&fg=000&s=2&c=20201002)


![\begin{aligned} E\left\{\hat{f}_0 \right\} &= f_0 \\ \sigma^{2}_{\hat{f}_0} &= E \left\{ \left( \hat{f}_0 - E [ \hat{f}_0] \right)^2 \right\} \quad \text{should be minimum} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+E%5Cleft%5C%7B%5Chat%7Bf%7D_0+%5Cright%5C%7D+%26%3D+f_0+%5C%5C+%5Csigma%5E%7B2%7D_%7B%5Chat%7Bf%7D_0%7D+%26%3D+E+%5Cleft%5C%7B+%5Cleft%28+%5Chat%7Bf%7D_0+-+E+%5B+%5Chat%7Bf%7D_0%5D+%5Cright%29%5E2+%5Cright%5C%7D+%5Cquad+%5Ctext%7Bshould+be+minimum%7D+%5Cend%7Baligned%7D+&bg=ffffff&fg=000&s=2&c=20201002)