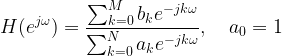The agenda for the subsequent series of articles is to introduce the idea of autocorrelation, AutoCorrelation Function (ACF), Partial AutoCorrelation Function (PACF) , using ACF and PACF in system identification.
Introduction
Given time series data (stock market data, sunspot numbers over a period of years, signal samples received over a communication channel etc.,), successive values in the time series often correlate with each other. This series correlation is termed persistence or inertia and it leads to increased power in the lower frequencies of the frequency spectrum. Persistence can drastically reduces the degrees of freedom in time series modeling (AR, MA , ARMA models). In the test for statistical significance, presence of persistence complicates the test as it reduces the number of independent observations.
Autocorrelation function
Correlation of a time series with its own past and future values- is called autocorrelation. It is also referred as “lagged or series correlation”. Positive autocorrelation is an indication of a specific form of persistence, the tendency of a system to remain in the same state from one observation to the next (example: continuous runs of 0’s or 1’s). If a time series exhibits correlation, the future values of the samples probabilistic-ally depend on the current & past samples. Thus the existence of autocorrelation can be exploited in prediction as well as modeling time series. Autocorrelation can be accessed using the following tools
● Time series plot
● Lagged scatterplot
● AutoCorrelation Function (ACF)
Generating a sample time series
For the purpose of illustration, let’s begin by generating two time series data using Auto-Regressive AR(1) process. AR(1) process relates the current sample x[n] of the output of an LTI system, its immediate past sample x[n-1] and the white noise term w[n].
A generic AR(1) system is given by

![a_0x[n]= c + a_1 x[n-1] + w[n] \quad\quad ,w[n] \sim N(0,\sigma^2)](https://s0.wp.com/latex.php?latex=a_0x%5Bn%5D%3D+c%C2%A0%2B+a_1+x%5Bn-1%5D+%2B+w%5Bn%5D+%C2%A0%5Cquad%5Cquad+%2Cw%5Bn%5D+%5Csim+N%280%2C%5Csigma%5E2%29+&bg=ffffff&fg=000&s=2&c=20201002)
Here



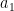



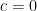

![a_0x[n]- a_1 x[n-1] = w[n] \quad\quad ,w[n] \sim N(0,\sigma^2)](https://s0.wp.com/latex.php?latex=a_0x%5Bn%5D-+a_1+x%5Bn-1%5D+%C2%A0%3D+w%5Bn%5D+%C2%A0%5Cquad%5Cquad+%2Cw%5Bn%5D+%5Csim+N%280%2C%5Csigma%5E2%29+&bg=ffffff&fg=000&s=2&c=20201002)
Let’s generate two time series data from the above model.
Model 1: a0=0, a1=1

![x[n]- x[n-1] = w[n] \quad\quad ,w[n] \sim N(0,\sigma^2)](https://s0.wp.com/latex.php?latex=x%5Bn%5D-+x%5Bn-1%5D+%3D+w%5Bn%5D+%C2%A0%5Cquad%5Cquad+%2Cw%5Bn%5D+%5Csim+N%280%2C%5Csigma%5E2%29+&bg=ffffff&fg=000&s=2&c=20201002)
The “Filter” function in Matlab will be utilized to generate the output process x[n]. The filter function, in its basic form – X=filter(B,A,W), takes three inputs. The vectors B and A denote the numerator and denominator co-efficients (model parameters here) of the transfer function of the LTI system in standard difference equation form, W is the white noise vector to the LTI filter and the output of filter is X.
The transfer function of model 1 is therefore,

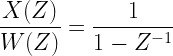
Where B=1 and A=[1 -1] and the input W is a white noise – which can be generate using randn function. Therefore, the above model can be implemented with the command x=filter(1,[1 -1,randn(1000,1)) generate 1000 samples of x[n]
A=[1 -1]; %model co-effs
% generating using numerator/denominator form with noise
x1 = filter(1,A,randn(1000,1));
plot(x1,’b’);Model 2: a0=1, a1=0.5

![x[n]- 0.5 x[n-1] = w[n] \quad\quad w[n] \sim N(0,\sigma^2)](https://s0.wp.com/latex.php?latex=x%5Bn%5D-+0.5+x%5Bn-1%5D+%3D+w%5Bn%5D+%C2%A0%5Cquad%5Cquad+w%5Bn%5D+%5Csim+N%280%2C%5Csigma%5E2%29+&bg=ffffff&fg=000&s=2&c=20201002)
Transfer function of this model is


Where B=1 and A=[1 -0.5] and the input W is a white noise – which can be generated using randn function. Therefore, the above model can be implemented with the command x=filter(1,[1 -0.5], randn(1000,1)) to generate 1000 samples of x[n]
A=[1 -0.5]; %model co-effs
% generating using numerator/denominator form with noise
x2 = filter(1,A,randn(1000,1));
plot(x2,’r’);

In the plot above, the output from model 1 exhibits persistence or positive correlation – positive deviations from mean tend to be followed by positive deviations for some duration and the negative deviations from mean tend to be followed by negative deviations for sometime. When the positive deviations are followed by negative deviations or vice-versa, it is a characteristic of negative correlation. Positive correlations are strong indications of long runs of several consecutive observations above or below mean. Negative correlations indicate low incidence of such runs. The output of the model 2 always jumps around the mean value and there is no consistent departure from the mean – no persistence (no positive correlation). The interpretation of time series plots for clues on persistence is a subjective matter and is left for trained eyes. However, it can be considered as a preliminary analysis.
Persistence – an indication of non-stationarity:
For time series analysis, it is imperative to work with stationary process. Many of the formulated theorems in statistical signal processing assume a series to be stationary (atleast in weak sense). Processes whose Probability Density Functions do not change with time are termed stationary (sub classifications include strict sense stationarity (SSS), weak sense stationarity (WSS) etc.,). For analysis, the joint probability distribution must remain unchanged should there be any shift in the time series. Time series with persistence – changing mean with time – are non-stationary – therefore many theorems in signal processing will not apply as such.
Plotting the histogram of the two series (see next figure) , we can immediately identify that the data generated by model 1 is non-stationary – histogram varies between selected portion of the signal. Whereas, the histogram of the output from model 2 is pretty much same – therefore, this is a stationary signal and is suitable for further analysis.


Lagged Scatter Plots
Autocorrelation trend can also be ascertained by lagged scatter plots. In lagged scatter plots, the samples of time series are plotted against one another with one lag at a time. A Strong positive autocorrelation will show of as a linear positive slope for the particular lag value. If the scatter plot is random, it indicates no-correlation for the particular lag.
figure;
x12 = x1(1:end-1);
x12 = x1(1:end-1);
x21 = x1(2:end);
x13 = x1(1:end-2);
x31 = x1(3:end);
x14 = x1(1:end-3);
x41 = x1(4:end);
x15 = x1(1:end-4);
x51 = x1(5:end);
subplot(2,2,1)
plot(x12,x21,'b*');
xlabel('X_1'); ylabel('X_2');
subplot(2,2,2)
plot(x13,x31,'b*');
xlabel('X_1'); ylabel('X_3');
subplot(2,2,3)
plot(x14,x41,'b*');
xlabel('X_1'); ylabel('X_4');
subplot(2,2,4)
plot(x15,x51,'b*');
xlabel('X_1'); ylabel('X_5');
figure;
x12 = x2(1:end-1);
x12 = x2(1:end-1);
x21 = x2(2:end);
x13 = x2(1:end-2);
x31 = x2(3:end);
x14 = x2(1:end-3);
x41 = x2(4:end);
x15 = x2(1:end-4);
x51 = x2(5:end);
subplot(2,2,1)
plot(x12,x21,'b*');
xlabel('X_1'); ylabel('X_2');
subplot(2,2,2)
plot(x13,x31,'b*');
xlabel('X_1'); ylabel('X_3');
subplot(2,2,3)
plot(x14,x41,'b*');
xlabel('X_1'); ylabel('X_4');
subplot(2,2,4)
plot(x15,x51,'b*');
xlabel('X_1'); ylabel('X_5');The scatter plot of the model 1 for the first four lags indicate strong positive correlation at all the four lag values. The scatter plot of model 2 indicates a slightly positive correlation for lag=1 and no correlation for remaining lags. This trend can be clearing seen if we plot the Auto Correlation Function (ACF).




Auto Correlation Function (ACF) or Correlogram
ACF plot summarizes the correlation of a time series at various lags. It plots the correlation co-efficient of the series lagged by 1 delay at a time in the sample plot. Plotting the ACF for the output from both the models with the code below.
[x1c,lags] = xcorr(x1,100,'coeff');
%Plotting only positive lag values - autocorrelation is symmetric
stem(lags(101:end),x1c(101:end));
[x2c,lags] = xcorr(x2,100,'coeff');
stem(lags(101:end),x2c(101:end))The ACF plot of model 1 indicates strong persistence across all the lags. The ACF plot of model 2 indicates significant correlation only at lag 1 (and lag 0 will obviously correlate fully) which concurs with the lagged scatter plots.


Correlogram has very few significant spikes at very small lags and cuts off drastically/dies down quickly for stationary series. Thus model 2 produces stationary series, where as model 1 does not. Also, model 2 is suitable for further time series analysis.
Continue reading on constructing an autocorrelation matrix…
Rate this article: Note: There is a rating embedded within this post, please visit this post to rate it.
Articles in this series
Books by the author
 Wireless Communication Systems in Matlab Second Edition(PDF) Note: There is a rating embedded within this post, please visit this post to rate it. |  Digital Modulations using Python (PDF ebook) Note: There is a rating embedded within this post, please visit this post to rate it. |  Digital Modulations using Matlab (PDF ebook) Note: There is a rating embedded within this post, please visit this post to rate it. |
| Hand-picked Best books on Communication Engineering Best books on Signal Processing |
||




![x[n] + a_1 x[n-1] + a_2 x[n-2] + \cdots + a_N x[n-N] = w[n]](https://s0.wp.com/latex.php?latex=x%5Bn%5D+%2B+a_1+x%5Bn-1%5D+%2B+a_2+x%5Bn-2%5D+%2B+%5Ccdots+%2B+a_N+x%5Bn-N%5D+%3D+w%5Bn%5D+&bg=ffffff&fg=000&s=1&c=20201002)

![\hat{r}_{xx}[k]](https://s0.wp.com/latex.php?latex=%5Chat%7Br%7D_%7Bxx%7D%5Bk%5D&bg=ffffff&fg=000&s=0&c=20201002)

![x[n] + a_1 x[n-1] + a_2 x[n-2] + \cdots + a_N x[n-N] = w[n] \quad\quad (1)](https://s0.wp.com/latex.php?latex=x%5Bn%5D+%2B+a_1+x%5Bn-1%5D+%2B+a_2+x%5Bn-2%5D+%2B+%5Ccdots+%2B+a_N+x%5Bn-N%5D+%3D+w%5Bn%5D+%5Cquad%5Cquad+%281%29+&bg=ffffff&fg=000&s=1&c=20201002)

![\displaystyle{\sum_{k=0}^{N} a_k x[n-k]=w[n], \;\;\; a_0=1} \quad\quad (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B%5Csum_%7Bk%3D0%7D%5E%7BN%7D+a_k+x%5Bn-k%5D%3Dw%5Bn%5D%2C+%5C%3B%5C%3B%5C%3B+a_0%3D1%7D+%5Cquad%5Cquad+%282%29+&bg=ffffff&fg=000&s=1&c=20201002)

![\displaystyle{ \sum_{k=0}^{N} a_k E\left\{ x[n-k]x[n-l] \right\}=E \left\{ w[n]x[n-l] \right\}, \;\;\; a_0=1} \quad\quad (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Csum_%7Bk%3D0%7D%5E%7BN%7D+a_k+E%5Cleft%5C%7B+x%5Bn-k%5Dx%5Bn-l%5D+%5Cright%5C%7D%3DE+%5Cleft%5C%7B+w%5Bn%5Dx%5Bn-l%5D+%5Cright%5C%7D%2C+%5C%3B%5C%3B%5C%3B+a_0%3D1%7D+%5Cquad%5Cquad++%283%29&bg=ffffff&fg=000&s=1&c=20201002)


![\displaystyle{\sum_{k=0}^{N} a_k \underbrace{E\left\{ x[n-k] x[n-l]\right\}}_{r_{xx}(l-k)} = \underbrace{E\left\{ w[n] x[n-l]\right\}}_{r_{wx}(l)}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B%5Csum_%7Bk%3D0%7D%5E%7BN%7D+a_k+%5Cunderbrace%7BE%5Cleft%5C%7B+x%5Bn-k%5D+x%5Bn-l%5D%5Cright%5C%7D%7D_%7Br_%7Bxx%7D%28l-k%29%7D+%3D+%5Cunderbrace%7BE%5Cleft%5C%7B+w%5Bn%5D+x%5Bn-l%5D%5Cright%5C%7D%7D_%7Br_%7Bwx%7D%28l%29%7D%7D+&bg=ffffff&fg=000&s=1&c=20201002)

![\displaystyle{\sum_{k=0}^{N} a_k r_{xx}[l-k]=r_{wx}[l]}, \;\;\; a_0=1 \quad\quad (4)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B%5Csum_%7Bk%3D0%7D%5E%7BN%7D+a_k+r_%7Bxx%7D%5Bl-k%5D%3Dr_%7Bwx%7D%5Bl%5D%7D%2C+%5C%3B%5C%3B%5C%3B+a_0%3D1+%5Cquad%5Cquad+%284%29+&bg=ffffff&fg=000&s=1&c=20201002)

![\displaystyle{x[n-l]=-\sum_{k=1}^{N} a_k x[n-k-l]+w[n-l]} \quad\quad (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7Bx%5Bn-l%5D%3D-%5Csum_%7Bk%3D1%7D%5E%7BN%7D+a_k+x%5Bn-k-l%5D%2Bw%5Bn-l%5D%7D+%5Cquad%5Cquad+%285%29+&bg=ffffff&fg=000&s=1&c=20201002)

![\displaystyle{ \begin{aligned} r_{wx}(l) &=E \left\{ w[n]x[n-l] \right\} \\ &= E \left\{ w[n] \left ( -\sum_{k=1}^{N} a_kx[n-k-l]+w[n-l] \right ) \right\}\\ &= E\left \{ -\sum_{k=1}^{N} a_kx[n-k-l]w[n]+w[n-l]w[n] \right \} \\ &= E\left \{ 0 + w[n-l]w[n] \right \}\\ &= E\left \{ w[n-l]w[n] \right \}\\ &=\begin{cases}0 \;\; ,l>0 \\ \sigma^2 \;,l=0\end{cases} \end{aligned}} \quad\quad (6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+r_%7Bwx%7D%28l%29+%26%3DE+%5Cleft%5C%7B+w%5Bn%5Dx%5Bn-l%5D+%5Cright%5C%7D+%5C%5C+%26%3D+E+%5Cleft%5C%7B+w%5Bn%5D+%5Cleft+%28+-%5Csum_%7Bk%3D1%7D%5E%7BN%7D+a_kx%5Bn-k-l%5D%2Bw%5Bn-l%5D+%5Cright+%29+%5Cright%5C%7D%5C%5C+%26%3D+E%5Cleft+%5C%7B+-%5Csum_%7Bk%3D1%7D%5E%7BN%7D+a_kx%5Bn-k-l%5Dw%5Bn%5D%2Bw%5Bn-l%5Dw%5Bn%5D+%5Cright+%5C%7D+%5C%5C+%26%3D+E%5Cleft+%5C%7B+0+%2B+w%5Bn-l%5Dw%5Bn%5D+%5Cright+%5C%7D%5C%5C+%26%3D+E%5Cleft+%5C%7B+w%5Bn-l%5Dw%5Bn%5D+%5Cright+%5C%7D%5C%5C+%26%3D%5Cbegin%7Bcases%7D0+%5C%3B%5C%3B+%2Cl%3E0+%5C%5C+%5Csigma%5E2+%5C%3B%2Cl%3D0%5Cend%7Bcases%7D+%5Cend%7Baligned%7D%7D+%5Cquad%5Cquad+%286%29+&bg=ffffff&fg=000&s=1&c=20201002)

![\displaystyle{\sum_{k=0}^{N} a_kr_{xx}[l-k]=\begin{cases}0 \;\; ,l>0 \\ \sigma^2 \;,l=0\end{cases} },\;\;\; a_0=1 \quad\quad (7)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B%5Csum_%7Bk%3D0%7D%5E%7BN%7D+a_kr_%7Bxx%7D%5Bl-k%5D%3D%5Cbegin%7Bcases%7D0+%5C%3B%5C%3B+%2Cl%3E0+%5C%5C+%5Csigma%5E2+%5C%3B%2Cl%3D0%5Cend%7Bcases%7D+%7D%2C%5C%3B%5C%3B%5C%3B+a_0%3D1+%5Cquad%5Cquad+%287%29+&bg=ffffff&fg=000&s=1&c=20201002)

![\displaystyle{ \sum_{k=1}^{N} a_k r_{xx}[l-k]=-r_{xx}[l]} \quad\quad (8)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Csum_%7Bk%3D1%7D%5E%7BN%7D+a_k+r_%7Bxx%7D%5Bl-k%5D%3D-r_%7Bxx%7D%5Bl%5D%7D+%5Cquad%5Cquad+%288%29+&bg=ffffff&fg=000&s=1&c=20201002)






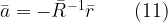

![x[n] = -0.9 x[n-1] -0.6 x[n-2] -0.5 x[n-3]](https://s0.wp.com/latex.php?latex=x%5Bn%5D+%3D+-0.9+x%5Bn-1%5D+-0.6+x%5Bn-2%5D+-0.5+x%5Bn-3%5D+&bg=ffffff&fg=000&s=1&c=20201002)






![\displaystyle{ w[n]= x[n]-\left(-\sum^{N}_{k=1}a_k x[n-k] \right)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+w%5Bn%5D%3D+x%5Bn%5D-%5Cleft%28-%5Csum%5E%7BN%7D_%7Bk%3D1%7Da_k+x%5Bn-k%5D+%5Cright%29%7D+&bg=ffffff&fg=000&s=1&c=20201002)


![\begin{aligned} x[n] + a_1 x[n-1] + \cdots + a_N x[n-N] = & b_0 w[n] + b_1 w[n-1] + \\ & \cdots + b_M w[n-M] \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+x%5Bn%5D+%2B+a_1+x%5Bn-1%5D+%2B+%5Ccdots+%2B+a_N+x%5Bn-N%5D+%3D+%26+b_0+w%5Bn%5D+%2B+b_1+w%5Bn-1%5D+%2B+%5C%5C+%26+%5Ccdots+%2B+b_M+w%5Bn-M%5D+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=1&c=20201002)

![\displaystyle{ w[n]= x[n]-\left(-\sum^{N}_{k=1}a_k x[n-k] + \sum^{M}_{k=1}b_k w[n-k] \right)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+w%5Bn%5D%3D+x%5Bn%5D-%5Cleft%28-%5Csum%5E%7BN%7D_%7Bk%3D1%7Da_k+x%5Bn-k%5D+%2B+%5Csum%5E%7BM%7D_%7Bk%3D1%7Db_k+w%5Bn-k%5D+%5Cright%29%7D+&bg=ffffff&fg=000&s=1&c=20201002)










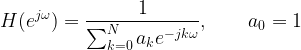



![x[n] = b_0 w[n] + b_1 w[n-1] + b_2 w[n-2] + \cdots + b_M w[n-M]](https://s0.wp.com/latex.php?latex=x%5Bn%5D+%3D+b_0+w%5Bn%5D+%2B+b_1+w%5Bn-1%5D+%2B+b_2+w%5Bn-2%5D+%2B+%5Ccdots+%2B+b_M+w%5Bn-M%5D++&bg=ffffff&fg=000&s=1&c=20201002)





![x[n] + a_1 x[n-1] + \cdots + a_N x[n-N] = b_0 w[n] + b_1 w[n-1] + \cdots + b_M w[n-M]](https://s0.wp.com/latex.php?latex=x%5Bn%5D+%2B+a_1+x%5Bn-1%5D+%2B+%5Ccdots+%2B+a_N+x%5Bn-N%5D+%3D+b_0+w%5Bn%5D+%2B+b_1+w%5Bn-1%5D+%2B+%5Ccdots+%2B+b_M+w%5Bn-M%5D+&bg=ffffff&fg=000&s=1&c=20201002)