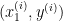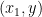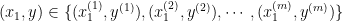Key focus: machine learning, introduction, basics, beginners, algorithms, applications, concepts
Introduction
Machine learning has emerged as a groundbreaking technology that is transforming industries and reshaping our interaction with technology. From personalized recommendations to autonomous vehicles, machine learning algorithms play a pivotal role in these advancements. If you’re new to the field, this comprehensive beginner’s guide will provide you with a solid introduction to machine learning, covering its fundamental concepts, practical applications, and key techniques.


Understanding Machine Learning:
Machine learning is a subset of artificial intelligence (AI) focused on developing algorithms and models that can learn from data and make predictions or decisions without explicit programming. Instead of relying on fixed instructions, these algorithms extract patterns and insights from available data, enabling them to generalize and make accurate predictions on unseen examples.
The core machine learning algorithms are categorized into three types:
- Supervised learning
- Unsupervised learning
- Reinforcement learning
Supervised Learning:
Supervised learning is a crucial branch of machine learning. In this approach, algorithms are trained on labeled datasets, where each example consists of input features and corresponding target labels. By learning from these labeled examples, algorithms can map inputs to correct outputs, identifying underlying patterns. Linear regression, decision trees, and support vector machines are common supervised learning algorithms.
Unsupervised Learning:
Unsupervised learning tackles unlabeled data. Its goal is to discover hidden patterns, structures, or relationships without prior knowledge of labels. Clustering and dimensionality reduction are prominent techniques within unsupervised learning. Clustering algorithms group similar data points, while dimensionality reduction methods aim to reduce feature dimensions while retaining relevant information.
Reinforcement Learning:
Reinforcement learning takes inspiration from how humans learn through trial and error. In this learning paradigm, an agent interacts with an environment and learns to maximize a reward signal by taking appropriate actions. Through repeated interactions, the agent explores the environment, receives feedback, and adjusts its actions to optimize its performance. Reinforcement learning has been successfully applied in areas such as robotics, gaming, and autonomous systems.
Key Steps in Machine Learning:
- Data Collection: Machine learning relies on quality data. Gathering relevant and representative data is a crucial initial step. It can come from various sources, including structured databases, APIs, or unstructured text and images.
- Data Preprocessing: Raw data often contains noise, missing values, or inconsistencies. Data preprocessing involves cleaning, transforming, and normalizing the data to ensure it is suitable for analysis and model training.
- Feature Engineering: Feature engineering involves selecting, extracting, or creating meaningful features from the available data. Good features can significantly impact the performance of a machine learning model.
- Model Training: This step involves feeding the prepared data into a machine learning algorithm to create a model. The algorithm learns from the data and adjusts its internal parameters to make accurate predictions or decisions.
- Model Evaluation: Evaluating the performance of a trained model is essential to assess its accuracy and generalization capabilities. Various metrics, such as accuracy, precision, recall, and F1 score, are used to measure the model’s performance.
- Model Deployment and Monitoring: Once the model is deemed satisfactory, it can be deployed in real-world applications. Continuous monitoring is crucial to ensure the model’s performance remains optimal and to address any issues that may arise.
Business use cases:
Businesses are increasingly leveraging machine learning to gain a competitive edge, improve operational efficiency, and enhance decision-making processes. Here are some common ways in which businesses are using machine learning:
- Customer Insights and Personalization: Machine learning enables businesses to analyze customer data, such as purchase history, browsing behavior, and demographic information, to gain valuable insights. This information can be used to personalize marketing campaigns, recommend relevant products or services, and improve customer experiences.
- Fraud Detection and Risk Management: Machine learning algorithms can identify patterns and anomalies in large volumes of transactional data, helping businesses detect fraudulent activities and mitigate risks. These algorithms learn from historical data to spot fraudulent patterns and predict potential risks, enabling proactive measures to safeguard businesses and their customers.
- Demand Forecasting and Inventory Management: By analyzing historical sales data, market trends, and external factors, machine learning algorithms can predict future demand for products or services. This helps businesses optimize inventory levels, minimize stock-outs, reduce costs, and improve overall supply chain management.
- Predictive Maintenance: Machine learning models can analyze sensor data from machinery and equipment to detect patterns indicating potential failures or maintenance needs. By identifying issues before they occur, businesses can schedule maintenance proactively, minimize downtime, and optimize equipment performance.
- Natural Language Processing (NLP) for Customer Support: NLP techniques powered by machine learning are employed in chatbots and virtual assistants to automate customer support processes. These systems can understand and respond to customer queries, provide relevant information, and assist with common issues, improving response times and enhancing customer satisfaction.
- Sentiment Analysis and Social Media Monitoring: Machine learning algorithms can analyze social media data and other online sources to gauge public sentiment and monitor brand reputation. This information helps businesses understand customer opinions, identify emerging trends, and respond effectively to customer feedback.
- Supply Chain Optimization: Machine learning algorithms optimize supply chain operations by analyzing data related to logistics, transportation, and inventory management. These models can identify bottlenecks, streamline routes, optimize scheduling, and reduce costs, ultimately improving the overall efficiency of the supply chain.
- Credit Scoring and Risk Assessment: Financial institutions employ machine learning algorithms to assess creditworthiness, predict default probabilities, and automate the loan approval process. By analyzing a range of variables, such as credit history, income, and demographics, these algorithms provide more accurate risk assessments and streamline lending processes.
- Image and Speech Recognition: Machine learning models have advanced image and speech recognition capabilities. Businesses can leverage these technologies for various applications, such as facial recognition for security purposes, automatic image tagging, voice-controlled virtual assistants, and automated document analysis.
- Data Analytics and Business Intelligence: Machine learning algorithms assist in analyzing large volumes of data to extract insights, identify patterns, and make data-driven decisions. By leveraging machine learning techniques, businesses can uncover hidden trends, gain a deeper understanding of their operations, and drive informed strategies.
These are just a few examples of how businesses are utilizing machine learning to improve their operations and decision-making processes. As machine learning continues to evolve, its applications across various industries and business functions are expected to expand, unlocking even greater opportunities for organizations.
Products/Services using machine learning
Machine learning has been integrated into a wide range of products and services across various industries. Here is a list of products that utilize machine learning:
- Virtual Assistants: Virtual assistants like Amazon Alexa, Google Assistant, and Apple Siri use machine learning to understand and respond to user queries, perform tasks, and provide personalized recommendations.
- Recommendation Systems: Platforms such as Netflix, Amazon, and Spotify leverage machine learning to analyze user preferences and behavior, providing personalized recommendations for movies, products, and music.
- Fraud Detection Systems: Financial institutions and online payment processors employ machine learning algorithms to detect and prevent fraudulent activities by analyzing patterns and anomalies in transactions and user behavior.
- Autonomous Vehicles: Self-driving cars and autonomous vehicles rely on machine learning algorithms to perceive and interpret the environment, make real-time decisions, and navigate safely on the roads.
- Image and Speech Recognition: Products like Google Photos, Facebook’s automatic photo tagging, and voice assistants utilize machine learning algorithms for image and speech recognition tasks, enabling features such as automatic tagging and voice-controlled interactions.
- Language Translation: Machine learning plays a significant role in language translation tools like Google Translate and Microsoft Translator, enabling accurate and automated translation between different languages.
- Social Media News Feed Ranking: Social media platforms like Facebook, Twitter, and Instagram employ machine learning algorithms to rank and personalize users’ news feeds, showing relevant content based on their interests and preferences.
- Customer Service Chatbots: Many companies use machine learning-powered chatbots to provide automated customer support, answer common queries, and assist with basic tasks without the need for human intervention.
- Email Filtering: Email service providers such as Gmail utilize machine learning algorithms to automatically filter and categorize incoming emails, separating spam from legitimate messages and prioritizing important emails.
- Medical Diagnosis Systems: Machine learning is applied in medical diagnosis systems to analyze patient data, medical images, and electronic health records, aiding in accurate disease diagnosis and treatment planning.
- Smart Home Devices: Smart home devices like smart thermostats, security systems, and voice-controlled assistants incorporate machine learning to learn user preferences, automate tasks, and optimize energy consumption.
- E-commerce Product Search and Recommendations: E-commerce platforms like Amazon and eBay employ machine learning to enhance product search capabilities, provide personalized recommendations, and optimize product listings.
- Predictive Maintenance Systems: Industrial equipment and machinery are monitored using machine learning algorithms to predict maintenance needs, detect anomalies, and minimize downtime through proactive maintenance.
- Financial Trading Systems: Machine learning algorithms are utilized in financial trading systems to analyze market data, identify patterns, and make automated trading decisions.
- Online Advertising: Platforms such as Google Ads and Facebook Ads leverage machine learning to optimize ad targeting, personalize advertisements, and improve campaign performance.
These are just a few examples of the many products and services that incorporate machine learning to provide enhanced functionalities, intelligent automation, and personalized experiences across various industries.