Note: There is a rating embedded within this post, please visit this post to rate it.
“Mean Square Error”, abbreviated as MSE, is an ubiquitous term found in texts on estimation theory. Have you ever wondered what this term actually means and why is this getting used in estimation theory very often ?
Any communication system has a transmitter, a channel or medium to communicate and a receiver. Given the channel impulse response and the channel noise, the goal of a receiver is to decipher what was sent from the transmitter. A simple channel is usually characterized by a channel response – \( h \) and an additive noise term – \( n \). In time domain, this can be written as
$$ y = h \circledast x + n $$
Here,


$$ Y = HX + N $$
Remember!!! Capitalized letters indicate frequency domain representation and small caps indicate time domain representation. The frequency domain equation looks simple and the only spoiler is the noise term. The receiver receives the information over the channel corrupted by noise and tries to decipher what was sent from the transmitter – \(X\). If the noise is cancelled out in the receiver, \(N =0\), the observed spectrum at the receiver will look like,
$$ Y = HX $$
Now, to know \( X \), the receiver has to know \(H\). Then it can simple divide the observed spectrum \(Y\) with the channel frequency response \(H\) to get \(X\). Unfortunately, things are not that easy. Cancellation of noise from the received samples/spectrum is the hardest part. Complete nullification of noise at the receiver is hardest to achieve and the entire communication system design engineering revolves around reducing this noise to minimum acceptable level to achieve acceptable performance.
Given the noise term, how do we know \(H\) from the observed/received spectrum \(Y\). This is a classical estimation problem.
Usually a known sequence ( pilot sequence in OFDM and training sequence in GSM etc.., ) is transmitted and sent across the channel and from that the channel response \(H\) or the impulse response \(h\) is estimated. This estimated channel response is used to decipher the transmitted spectrum/sequence when receiving the actual data. This type of estimation is useful if and only if the channel response remains constant across the frequency band of interest (Channel is flat across the band of interest – “flat fading”).
Okay !!! To estimate \(H\) in the presence of noise, we need some metric to quantify the accuracy of the estimation.
Line equations:
Consider a generic line equation \(y = mx+c\), where \(m\) is the slope of the line and \(c\) is the intercept. Both \(m\) and \(c\) are constants. Since \(x\) is a first order term (highest degree of \(x\)’s degree is one), this is called a linear equation. If the equation looks like \(y = mx^2+kx+c\), the highest degree of \(x\) is 2 and it becomes a quadratic equation. Similarly, the term \(x^3\) in the polynomial equation gives rise to the name cubic equation, \(x^4\) – quartic equation so on and so forth.
Naming a univariate Polynomial equation
| Univariate Polynomial Equation | Highest degree of 'x' | Name |
|---|---|---|
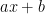 | 1 | Linear |
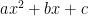 | 2 | Quadratic |
 | 3 | Cubic |
 | 4 | Quartic |
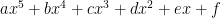 | 5 | Quintic |





Coming back to the linear-line equation, \(y = mx +c\), to simplify things, let’s assign \(m=2\) and \(c=0\) and generate values for \(y\) by varying \(x\) from x=0 to 9 in steps of 1.


In the above equation, the input \(x\) gets transformed into output \(y\) by the transformation \(y = mx\). This can be considered analogous to a communication system in frequency domain, where the input \(X\) is transmitted, it gets transformed by a channel \(H\) and gives the output \(Y\).
$$ Y = HX $$
Frequency domain is considered because it has the same structure as the linear equation, whereas, in time domain the output of the channel is the convolution of the channel impulse response \(h\) and the input \(x\).
We can now consider that the channel impulse response in frequency domain \(H\) is equal to the constant \(m\) (flat fading assumption).
To make the channel look closer to a real one, we will add Additive White Noise Gaussian (AWGN) noise to the channel.
$$Y = HX + N $$


To represent this scenario in our line fitting problem, the noise is represented as being generated from a set of uniformly generated random numbers – ‘\(n\)’. We call this – “observed data”.
$$ y_1 = mx + n $$
Note: The term \(n\) in the above is not a constant but a random variable, whereas,the term \( c \) is a constant (This can be considered as a DC bias in the observed data , if present). I have generated the following table for illustration. For convenience and to illustrate the importance of the term MSE, the noise terms in the following table are not drawn from an uniform set of random numbers, instead, they are manually created in a way to make the total error term zero.


The first column is the input \( x \), the second column is the ideal (actual) output \( y \) that follows the equation \( y = mx + c \), with \( c \) set to \( 0 \). The third column is the noise term. The fourth column is the observed samples at the receiver after the ideal samples are corrupted by the noise term. The fourth column represents the equation \( y_1 = mx + n \).
Now, our job is to estimated the constant \( m \) in the presence of noise. Can you think of a possible metric which could aid in this estimation problem ? Given that a known data \( x \) is transmitted, the obvious choice is to measure the average error between the observed sequence of data and the actual data and to use a brute force search for \( m \). Plug-in various values in the place of \(m\) and choose the one that gives the minimum error.
Selecting the “error” as a metric seems to be a great and simple approach. But there exists a basic flaw in this approach. Now, consider the fifth column in the table which measures the error between the observed and actual data. The noise terms in the third column are chosen such that the average-error-measured becomes zero. Even though the average error is zero, it is obvious that the observed data is far from the ideal one. This is a big drawback in the error metric. This is because the positive and the negative errors cancel out. This can happen in the real scenario too, where the errors across all samples of observed data can cancel out each other.
To circumvent this problem, lets square the error terms (sixth column) and average them out. This metric is called – Mean Squared Error. Now, no matter what the sign of error is, the squaring operation always amplifies the errors in the positive direction. The issue of errors cancelling each other is solved by this approach. An estimation approach that attempts to Minimize the Mean Square Error is called a Minimum Mean Square Error (MMSE) estimator.1
I hope that this text might have helped in understanding the logic behind using Mean Square Error as a metric for estimation problems. Comments/suggestions for improvements are welcome. The next post will focus on Ordinary Least Squares (OLS) algorithm (using the mean square error metric) applied to a linear-line fitting problem.
      |













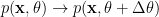

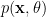

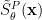
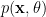
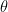



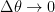















![x[n] = A cos \left(2 \pi f_c n+ \phi_c \right) + w[n] ,\quad n=0,1,\cdots,N-1](https://s0.wp.com/latex.php?latex=x%5Bn%5D+%3D+A+cos+%5Cleft%282+%5Cpi+f_c+n%2B+%5Cphi_c+%5Cright%29+%2B+w%5Bn%5D+%2C%5Cquad+n%3D0%2C1%2C%5Ccdots%2CN-1&bg=ffffff&fg=000&s=1&c=20201002)

![\begin{aligned} p(\mathbf{x} ; \phi) &= \prod_{n-0}^{N-1} \frac{1}{\sqrt{2 \pi \sigma^2}} exp \left[ -\frac{\left( \mathbf{x} - \mu_x \right)^2}{2 \sigma^2} \right] \\ &= \prod_{n-0}^{N-1} \frac{1}{\sqrt{2 \pi \sigma^2}} exp \left[ -\frac{\left( x[n] - \mu_x \right)^2}{2 \sigma^2} \right] \\ &= \frac{1}{\left( 2 \pi \sigma^2 \right)^{\frac{N}{2}}} exp \left[ - \frac{1}{2 \sigma^2} \sum_{n=0}^{N-1} \left( x[n] - \mu_x \right)^2 \right] \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+p%28%5Cmathbf%7Bx%7D+%3B+%5Cphi%29+%26%3D+%5Cprod_%7Bn-0%7D%5E%7BN-1%7D+%5Cfrac%7B1%7D%7B%5Csqrt%7B2+%5Cpi+%5Csigma%5E2%7D%7D+exp+%5Cleft%5B+-%5Cfrac%7B%5Cleft%28+%5Cmathbf%7Bx%7D+-+%5Cmu_x+%5Cright%29%5E2%7D%7B2+%5Csigma%5E2%7D+%5Cright%5D+%5C%5C+%26%3D+%5Cprod_%7Bn-0%7D%5E%7BN-1%7D+%5Cfrac%7B1%7D%7B%5Csqrt%7B2+%5Cpi+%5Csigma%5E2%7D%7D+exp+%5Cleft%5B+-%5Cfrac%7B%5Cleft%28+x%5Bn%5D+-+%5Cmu_x+%5Cright%29%5E2%7D%7B2+%5Csigma%5E2%7D+%5Cright%5D+%5C%5C+%26%3D++%5Cfrac%7B1%7D%7B%5Cleft%28+2+%5Cpi+%5Csigma%5E2+%5Cright%29%5E%7B%5Cfrac%7BN%7D%7B2%7D%7D%7D+exp+%5Cleft%5B+-+%5Cfrac%7B1%7D%7B2+%5Csigma%5E2%7D+%5Csum_%7Bn%3D0%7D%5E%7BN-1%7D+%5Cleft%28+x%5Bn%5D+-+%5Cmu_x+%5Cright%29%5E2+%5Cright%5D+%5Cend%7Baligned%7D+&bg=ffffff&fg=000&s=1&c=20201002)

![\begin{aligned} \mu_x &= \frac{1}{N} \sum_{n=0}^{N-1} x[n] = \frac{1}{N} \sum_{n=0}^{N-1} \left[ A\;cos \left\{ 2 \pi f_c n + \phi_c \right\} + w[n] \right] \\ &= \frac{1}{N} \sum_{n=0}^{N-1} \left[ A\;cos \left\{ 2 \pi f_c n + \phi_c \right\} \right] + \frac{1}{N} \sum_{n=0}^{N-1} w[n] \\ &= \frac{1}{N} \sum_{n=0}^{N-1} \left[ A\;cos \left\{ 2 \pi f_c n + \phi_c \right\} \right] + 0 \\ &= \frac{1}{N} \sum_{n=0}^{N-1} \left[ A\;cos \left\{ 2 \pi f_c n + \phi_c \right\} \right] \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmu_x+%26%3D++%5Cfrac%7B1%7D%7BN%7D+%5Csum_%7Bn%3D0%7D%5E%7BN-1%7D+x%5Bn%5D+%3D+%5Cfrac%7B1%7D%7BN%7D+%5Csum_%7Bn%3D0%7D%5E%7BN-1%7D+%5Cleft%5B+A%5C%3Bcos+%5Cleft%5C%7B+2+%5Cpi+f_c+n+%2B+%5Cphi_c+%5Cright%5C%7D+%2B+w%5Bn%5D+%5Cright%5D+%5C%5C+%26%3D+%5Cfrac%7B1%7D%7BN%7D+%5Csum_%7Bn%3D0%7D%5E%7BN-1%7D+%5Cleft%5B+A%5C%3Bcos+%5Cleft%5C%7B+2+%5Cpi+f_c+n+%2B+%5Cphi_c+%5Cright%5C%7D+%5Cright%5D+%2B+%5Cfrac%7B1%7D%7BN%7D+%5Csum_%7Bn%3D0%7D%5E%7BN-1%7D+w%5Bn%5D+%5C%5C+%26%3D+%5Cfrac%7B1%7D%7BN%7D+%5Csum_%7Bn%3D0%7D%5E%7BN-1%7D+%5Cleft%5B+A%5C%3Bcos+%5Cleft%5C%7B+2+%5Cpi+f_c+n+%2B+%5Cphi_c+%5Cright%5C%7D+%5Cright%5D+%2B+0+%5C%5C+%26%3D+%5Cfrac%7B1%7D%7BN%7D+%5Csum_%7Bn%3D0%7D%5E%7BN-1%7D+%5Cleft%5B+A%5C%3Bcos+%5Cleft%5C%7B+2+%5Cpi+f_c+n+%2B+%5Cphi_c+%5Cright%5C%7D+%5Cright%5D+%5Cend%7Baligned%7D+&bg=ffffff&fg=000&s=1&c=20201002)

![\displaystyle{ p(\mathbf{x}; \phi) = \frac{1}{\left( 2 \pi \sigma^2 \right)^{\frac{N}{2}}} exp \left[ -\frac{1}{2 \sigma^2} \sum_{n=0}^{N-1} \left[ x[n] - A cos\left( 2 \pi f_c n + \phi_c \right)\right]^2 \right]}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+p%28%5Cmathbf%7Bx%7D%3B+%5Cphi%29+%3D+%5Cfrac%7B1%7D%7B%5Cleft%28+2+%5Cpi+%5Csigma%5E2+%5Cright%29%5E%7B%5Cfrac%7BN%7D%7B2%7D%7D%7D+exp+%5Cleft%5B+-%5Cfrac%7B1%7D%7B2+%5Csigma%5E2%7D+%5Csum_%7Bn%3D0%7D%5E%7BN-1%7D+%5Cleft%5B+x%5Bn%5D+-+A+cos%5Cleft%28+2+%5Cpi+f_c+n+%2B+%5Cphi_c+%5Cright%29%5Cright%5D%5E2++%5Cright%5D%7D+&bg=ffffff&fg=000&s=1&c=20201002)

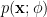

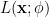

![\displaystyle{ ln\; L(\mathbf{x;\phi }) = - \frac{N}{2} ln \left( 2 \pi \sigma^2\right) + \left[ - \frac{1}{2 \sigma^2} \sum_{n=0}^{N-1} \left( x[n] - A cos \left\{ 2 \pi f_c n + \phi_c \right\} \right)^2 \right] }](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+ln%5C%3B+L%28%5Cmathbf%7Bx%3B%5Cphi+%7D%29+%3D+-+%5Cfrac%7BN%7D%7B2%7D+ln+%5Cleft%28+2+%5Cpi+%5Csigma%5E2%5Cright%29+%2B+%5Cleft%5B++-+%5Cfrac%7B1%7D%7B2+%5Csigma%5E2%7D+%5Csum_%7Bn%3D0%7D%5E%7BN-1%7D+%5Cleft%28+x%5Bn%5D+-+A+cos+%5Cleft%5C%7B+2+%5Cpi+f_c+n+%2B+%5Cphi_c+%5Cright%5C%7D+%5Cright%29%5E2+%5Cright%5D+%7D++&bg=ffffff&fg=000&s=1&c=20201002)

![\displaystyle{ \begin{aligned}\frac{\partial \; ln \; L( \mathbf{x;\phi})}{\partial \phi} &= -\frac{1}{\sigma^2} \sum_{n-0}^{N-1} \left[ x[n] - A cos \left( 2 \pi f_c n + \phi \right) \right] A sin \left( 2 \pi f_c n + \phi \right) \\ &=-\frac{A}{\sigma^2} \sum_{n-0}^{N-1} \left[ x[n] sin (2 \pi f_c n + \phi) - \frac{A}{2} sin( 4 \pi f_c n + 2 \phi) \right] \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D%5Cfrac%7B%5Cpartial+%5C%3B+ln+%5C%3B+L%28+%5Cmathbf%7Bx%3B%5Cphi%7D%29%7D%7B%5Cpartial+%5Cphi%7D+%26%3D+-%5Cfrac%7B1%7D%7B%5Csigma%5E2%7D+%5Csum_%7Bn-0%7D%5E%7BN-1%7D+%5Cleft%5B+x%5Bn%5D+-+A+cos+%5Cleft%28+2+%5Cpi+f_c+n+%2B+%5Cphi+%5Cright%29+%5Cright%5D+A+sin+%5Cleft%28+2+%5Cpi+f_c+n+%2B+%5Cphi+%5Cright%29+%5C%5C+%26%3D-%5Cfrac%7BA%7D%7B%5Csigma%5E2%7D+%5Csum_%7Bn-0%7D%5E%7BN-1%7D+%5Cleft%5B+x%5Bn%5D+sin+%282+%5Cpi+f_c+n+%2B+%5Cphi%29+-+%5Cfrac%7BA%7D%7B2%7D+sin%28+4+%5Cpi+f_c+n+%2B+2+%5Cphi%29+%5Cright%5D+%5Cend%7Baligned%7D%7D+&bg=ffffff&fg=000&s=1&c=20201002)

![\displaystyle{ \frac{\partial^2 \; ln \; L( \mathbf{x;\phi})}{\partial^2 \phi} = -\frac{A}{\sigma^2} \sum_{n-0}^{N-1} \left[ x[n] cos (2 \pi f_c n + \phi) - A cos( 4 \pi f_c n + 2 \phi) \right] }](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cfrac%7B%5Cpartial%5E2+%5C%3B+ln+%5C%3B+L%28+%5Cmathbf%7Bx%3B%5Cphi%7D%29%7D%7B%5Cpartial%5E2+%5Cphi%7D+%3D+-%5Cfrac%7BA%7D%7B%5Csigma%5E2%7D+%5Csum_%7Bn-0%7D%5E%7BN-1%7D+%5Cleft%5B+x%5Bn%5D+cos+%282+%5Cpi+f_c+n+%2B+%5Cphi%29+-+A+cos%28+4+%5Cpi+f_c+n+%2B+2+%5Cphi%29+%5Cright%5D+%7D+&bg=ffffff&fg=000&s=1&c=20201002)

![\displaystyle{\begin{aligned} -E \left[\frac{\partial^2 \; ln \; L(\mathbf{x;\phi})}{\partial^2 \phi} \right] &= \frac{A}{\sigma^2} \sum_{n=0}^{N-1} \left[ E(x[n])cos\left( 2 \pi f_c n + \phi \right) - A \; cos\left( 4 \pi f_c n + 2 \phi \right) \right] \\ &= \frac{A}{\sigma^2} \sum_{n=0}^{N-1} \left[ A \; cos^2 \left( 2 \pi f_c n + \phi \right) - A \; cos \left( 4 \pi f_c n + 2 \phi \right)\right] \\ &= \frac{A^2}{\sigma^2} \sum_{n=0}^{N-1} \left[ \frac{1}{2} + \frac{1}{2} cos \left( 4 \pi f_c n + 2 \phi \right) - cos\left( 4 \pi f_c n + 2 \phi \right) \right] \\ &=\frac{A^2}{2 \sigma^2} \sum_{n=0}^{N-1} \left[ 1 - cos \left( 4 \pi f_c n + 2 \phi\right)\right] \\ & \approx \frac{A^2}{2 \sigma^2} \left[ N - 0 \right] = \frac{N A^2}{2 \sigma^2}\end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B%5Cbegin%7Baligned%7D+-E+%5Cleft%5B%5Cfrac%7B%5Cpartial%5E2+%5C%3B+ln+%5C%3B+L%28%5Cmathbf%7Bx%3B%5Cphi%7D%29%7D%7B%5Cpartial%5E2+%5Cphi%7D+%5Cright%5D+%26%3D+%5Cfrac%7BA%7D%7B%5Csigma%5E2%7D+%5Csum_%7Bn%3D0%7D%5E%7BN-1%7D+%5Cleft%5B+E%28x%5Bn%5D%29cos%5Cleft%28+2+%5Cpi+f_c+n+%2B+%5Cphi+%5Cright%29+-+A+%5C%3B+cos%5Cleft%28+4+%5Cpi+f_c+n+%2B+2+%5Cphi+%5Cright%29+%5Cright%5D+%5C%5C+%26%3D+%5Cfrac%7BA%7D%7B%5Csigma%5E2%7D+%5Csum_%7Bn%3D0%7D%5E%7BN-1%7D+%5Cleft%5B+A+%5C%3B+cos%5E2+%5Cleft%28+2+%5Cpi+f_c+n+%2B+%5Cphi+%5Cright%29+-+A+%5C%3B+cos+%5Cleft%28+4+%5Cpi+f_c+n+%2B+2+%5Cphi+%5Cright%29%5Cright%5D+%5C%5C+%26%3D+%5Cfrac%7BA%5E2%7D%7B%5Csigma%5E2%7D+%5Csum_%7Bn%3D0%7D%5E%7BN-1%7D+%5Cleft%5B+%5Cfrac%7B1%7D%7B2%7D+%2B+%5Cfrac%7B1%7D%7B2%7D+cos+%5Cleft%28+4+%5Cpi+f_c+n+%2B+2+%5Cphi+%5Cright%29+-+cos%5Cleft%28+4+%5Cpi+f_c+n+%2B+2+%5Cphi+%5Cright%29+%5Cright%5D+%5C%5C+%26%3D%5Cfrac%7BA%5E2%7D%7B2+%5Csigma%5E2%7D+%5Csum_%7Bn%3D0%7D%5E%7BN-1%7D+%5Cleft%5B+1+-+cos+%5Cleft%28+4+%5Cpi+f_c+n+%2B+2+%5Cphi%5Cright%29%5Cright%5D+%5C%5C+%26+%5Capprox+%5Cfrac%7BA%5E2%7D%7B2+%5Csigma%5E2%7D+%5Cleft%5B+N+-+0+%5Cright%5D+%3D+%5Cfrac%7BN+A%5E2%7D%7B2+%5Csigma%5E2%7D%5Cend%7Baligned%7D%7D++&bg=ffffff&fg=000&s=1&c=20201002)

![\displaystyle{ I(\phi) = -E \left[\frac{\partial^2 \; ln \; L(\mathbf{x;\phi})}{\partial^2 \phi} \right] = \frac{N A^2}{ 2 \sigma^2}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+I%28%5Cphi%29+%3D+-E+%5Cleft%5B%5Cfrac%7B%5Cpartial%5E2+%5C%3B+ln+%5C%3B+L%28%5Cmathbf%7Bx%3B%5Cphi%7D%29%7D%7B%5Cpartial%5E2+%5Cphi%7D+%5Cright%5D+%3D+%5Cfrac%7BN+A%5E2%7D%7B+2+%5Csigma%5E2%7D%7D+&bg=ffffff&fg=000&s=1&c=20201002)



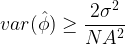

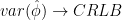

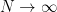



![\displaystyle{ \frac{\partial \; ln \; L(\mathbf{x;\phi}) }{\partial \phi} = I(\phi) \left[ g(\mathbf{x}) - \phi \right]}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cfrac%7B%5Cpartial+%5C%3B+ln+%5C%3B+L%28%5Cmathbf%7Bx%3B%5Cphi%7D%29+%7D%7B%5Cpartial+%5Cphi%7D+%3D+I%28%5Cphi%29+%5Cleft%5B+g%28%5Cmathbf%7Bx%7D%29+-+%5Cphi+%5Cright%5D%7D+&bg=ffffff&fg=000&s=1&c=20201002)

![\displaystyle{ \frac{\partial \; ln \; L(\mathbf{x;\phi}) }{\partial \phi} = - \frac{A}{\sigma^2} \sum_{n=0}^{N-1} \left[ x[n] \; sin \left( 2 \pi f_c n + \phi\right) - \frac{A}{2} sin \left( 4 \pi f_c n + 2 \phi \right) \right]}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cfrac%7B%5Cpartial+%5C%3B+ln+%5C%3B+L%28%5Cmathbf%7Bx%3B%5Cphi%7D%29+%7D%7B%5Cpartial+%5Cphi%7D+%3D+-+%5Cfrac%7BA%7D%7B%5Csigma%5E2%7D+%5Csum_%7Bn%3D0%7D%5E%7BN-1%7D+%5Cleft%5B+x%5Bn%5D+%5C%3B+sin+%5Cleft%28+2+%5Cpi+f_c+n+%2B+%5Cphi%5Cright%29+-+%5Cfrac%7BA%7D%7B2%7D+sin+%5Cleft%28+4+%5Cpi+f_c+n+%2B+2+%5Cphi+%5Cright%29+%5Cright%5D%7D+&bg=ffffff&fg=000&s=1&c=20201002)

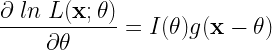

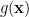














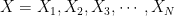

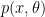

![I(\theta) = -E\left [ \frac{\partial^2 ln L(\theta)}{\partial \theta^2} \right ]](https://s0.wp.com/latex.php?latex=I%28%5Ctheta%29+%3D+-E%5Cleft+%5B+%5Cfrac%7B%5Cpartial%5E2+ln+L%28%5Ctheta%29%7D%7B%5Cpartial+%5Ctheta%5E2%7D+%5Cright+%5D+&bg=ffffff&fg=000&s=2&c=20201002)

![E\left [ \frac{\partial ln L(\theta) }{\partial \theta } \right ] = 0 \;\;\; \forall\theta](https://s0.wp.com/latex.php?latex=E%5Cleft+%5B+%5Cfrac%7B%5Cpartial+ln+L%28%5Ctheta%29+%7D%7B%5Cpartial+%5Ctheta+%7D+%5Cright+%5D+%3D+0+%5C%3B%5C%3B%5C%3B+%5Cforall%5Ctheta+&bg=ffffff&fg=000&s=2&c=20201002)





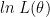

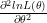

![\text{Data Model: } x[n] = A + w[n], \;\;\; n=0,1,2,\cdots,N-1](https://s0.wp.com/latex.php?latex=%5Ctext%7BData+Model%3A+%7D+x%5Bn%5D+%3D+A+%2B+w%5Bn%5D%2C+%5C%3B%5C%3B%5C%3B+n%3D0%2C1%2C2%2C%5Ccdots%2CN-1%C2%A0+&bg=ffffff&fg=000&s=2&c=20201002)


![x[n]](https://s0.wp.com/latex.php?latex=x%5Bn%5D&bg=ffffff&fg=000&s=0&c=20201002)

![w[n]](https://s0.wp.com/latex.php?latex=w%5Bn%5D&bg=ffffff&fg=000&s=0&c=20201002)





![\displaystyle{ln\;L(x;A) =-\frac{N}{2}ln(2\pi\sigma^2) - \frac{1}{2\sigma^2}\sum_{n=0}^{N-1}(x[n]-A)^2}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7Bln%5C%3BL%28x%3BA%29+%3D-%5Cfrac%7BN%7D%7B2%7Dln%282%5Cpi%5Csigma%5E2%29+-+%5Cfrac%7B1%7D%7B2%5Csigma%5E2%7D%5Csum_%7Bn%3D0%7D%5E%7BN-1%7D%28x%5Bn%5D-A%29%5E2%7D+&bg=ffffff&fg=000&s=2&c=20201002)









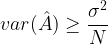

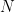

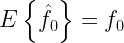

![\sigma^{2}_{ \hat{f}_0 }=E \left\{ \left( \hat{f}_0 - E [ \hat{f}_0 ] \right)^2 \right\} \quad \text{should be minimum}](https://s0.wp.com/latex.php?latex=%5Csigma%5E%7B2%7D_%7B+%5Chat%7Bf%7D_0+%7D%3DE+%5Cleft%5C%7B+%5Cleft%28+%5Chat%7Bf%7D_0+-+E+%5B+%5Chat%7Bf%7D_0+%5D++%5Cright%29%5E2+%5Cright%5C%7D+%5Cquad+%5Ctext%7Bshould+be+minimum%7D+&bg=ffffff&fg=000&s=2&c=20201002)





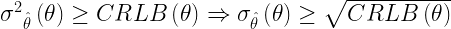





![u(\theta) =\frac{\partial }{\partial \theta} \left[ ln L(\theta) \right ]](https://s0.wp.com/latex.php?latex=u%28%5Ctheta%29+%3D%5Cfrac%7B%5Cpartial+%7D%7B%5Cpartial+%5Ctheta%7D+%5Cleft%5B+ln+L%28%5Ctheta%29+%5Cright+%5D+&bg=ffffff&fg=000&s=1&c=20201002)
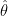

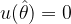

![E[u(\theta)] = 0](https://s0.wp.com/latex.php?latex=E%5Bu%28%5Ctheta%29%5D+%3D+0+&bg=ffffff&fg=000&s=1&c=20201002)



![\displaystyle{\begin{aligned} I(\theta) &= -var \left[ u (\theta) \right] \\ &= - E \left[ u (\theta) u^\ast (\theta) \right] \\ &= - E \left[ \frac{\partial^2 \; ln \left[ L(\theta) \right] }{\partial \theta^2} \right] \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B%5Cbegin%7Baligned%7D+I%28%5Ctheta%29+%26%3D+-var+%5Cleft%5B+u+%28%5Ctheta%29+%5Cright%5D+%5C%5C+%26%3D+-+E+%5Cleft%5B+u+%28%5Ctheta%29+u%5E%5Cast+%28%5Ctheta%29+%5Cright%5D+%5C%5C+%26%3D+-+E+%5Cleft%5B+%5Cfrac%7B%5Cpartial%5E2+%5C%3B+ln+%5Cleft%5B+L%28%5Ctheta%29+%5Cright%5D+%7D%7B%5Cpartial+%5Ctheta%5E2%7D+%5Cright%5D+%5Cend%7Baligned%7D%7D+&bg=ffffff&fg=000&s=1&c=20201002)














