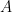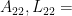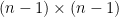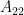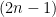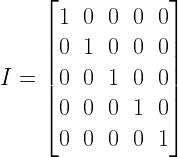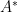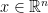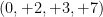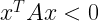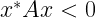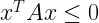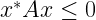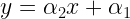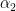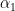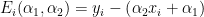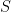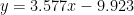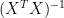Key focus: AR, MA & ARMA models express the nature of transfer function of LTI system. Understand the basic idea behind those models & know their frequency responses.
Introduction
Signal models are used to analyze stationary univariate time series. The goal of signal modeling is to estimate the process from which the desired signal is generated. Though the concept described here is related to the topic of “system identification”, they are quite different.
A signal model is an unique combination of a filter and a source input, that may fall into any of the following categories
- Filter: state-space model, AR, MA, ARMA (see below)
- Source:pulse, pulse train, white noise,…
Motivation
Let’s say we observe a real world signal x[n] that has a spectrum x[ɷ] (the spectrum can be arbitrary – bandpass, baseband etc..,). We would like to describe the long sequence of x[n] using very few parameters (application : Linear Predictive Coding (LPC) ). The modelling approach, described here, tries to answer the following two questions.
- Is it possible to model the first order (mean/variance) and second order (correlations, spectrum) statistics of the signal just by shaping a white noise spectrum using a transfer function ? (see Figure 1)
- Does this produce the same statistics (spectrum, correlations, mean and variance) for a white noise input ?
If the answer is “yes” to the above two questions, we can simply set the modeled parameters of the system and excite the system with white (flat) noise to produce the desired real world signal. This reduces the amount to data we wish to transmit in a communication system application.


LTI system model
In the model given below, the random signal x[n] is observed. Given the observed signal x[n], the goal here is to find a model that best describes the spectral properties of x[n] under the following assumptions
● x[n] is WSS (Wide Sense Stationary) and ergodic.
● The input signal to the LTI system is white noise following Gaussian distribution – zero mean and variance σ2.
● The LTI system is BIBO (Bounded Input Bounded Output) stable.


In the model shown above, the input to the LTI system is a white noise following Gaussian distribution – zero mean and variance σ2. The power spectral density (PSD) of the noise w[n] is


The noise process drives the LTI system with frequency response H(ejɷ) producing the signal of interest x[n]. The PSD of the output process is therefore,


Three cases are possible given the nature of the transfer function of the LTI system that is under investigation here.
- Auto Regressive (AR) models : H(ejɷ) is an all-poles system
- Moving Average (MA) models : H(ejɷ) is an all-zeros system
- Auto Regressive Moving Average (ARMA) models : H(ejɷ) is a pole-zero system
Auto Regressive (AR) models (all-poles model)
In the AR model, the present output sample x[n] and the past N output samples determine the source input w[n]. The difference equation that characterizes this model is given by

![x[n] + a_1 x[n-1] + a_2 x[n-2] + \cdots + a_N x[n-N] = w[n]](https://s0.wp.com/latex.php?latex=x%5Bn%5D+%2B+a_1+x%5Bn-1%5D+%2B+a_2+x%5Bn-2%5D+%2B+%5Ccdots+%2B+a_N+x%5Bn-N%5D+%3D+w%5Bn%5D+&bg=ffffff&fg=000&s=1&c=20201002)
Here, the LTI system is an Infinite Impulse Response (IIR) filter. This is evident from the fact that the above equation considered past samples of x[n] when determining w[n], there by creating a feedback loop from the output of the filter.
The frequency response of the IIR filter is well known

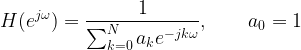


The transfer function H(ejɷ) is an all-pole transfer function (when the denominator is set to zero, the transfer function goes to infinity -> creating peaks in the spectrum). Poles are best suited to model resonant peaks in a given spectrum. At the peaks, the poles are closer to unit circle. This model is well suited for modeling peaky spectra.
Read all articles tagged Auto-regressive model.
Moving Average (MA) models (all-zeros model)
In the MA model, the present output sample x[n] is determined by the present source input w[n] and past N samples of source input w[n]. The difference equation that characterizes this model is given by

![x[n] = b_0 w[n] + b_1 w[n-1] + b_2 w[n-2] + \cdots + b_M w[n-M]](https://s0.wp.com/latex.php?latex=x%5Bn%5D+%3D+b_0+w%5Bn%5D+%2B+b_1+w%5Bn-1%5D+%2B+b_2+w%5Bn-2%5D+%2B+%5Ccdots+%2B+b_M+w%5Bn-M%5D++&bg=ffffff&fg=000&s=1&c=20201002)
Here, the LTI system is an Finite Impulse Response (FIR) filter. This is evident from the fact that the above equation that no feedback is involved from output to input.
The frequency response of the FIR filter is well known


The transfer function H(ejɷ) is an all-zero transfer function (when the numerator is set to zero, the transfer function goes to zero -> creating nulls in the spectrum). Zeros are best suited to model sharp nulls in a given spectrum.


Auto Regressive Moving Average (ARMA) model (pole-zero model)
ARMA model is a generalized model that is a combination of AR and MA model. The output of the filter is linear combination of both weighted inputs (present and past samples) and weight outputs (present and past samples). The difference equation that characterizes this model is given by

![x[n] + a_1 x[n-1] + \cdots + a_N x[n-N] = b_0 w[n] + b_1 w[n-1] + \cdots + b_M w[n-M]](https://s0.wp.com/latex.php?latex=x%5Bn%5D+%2B+a_1+x%5Bn-1%5D+%2B+%5Ccdots+%2B+a_N+x%5Bn-N%5D+%3D+b_0+w%5Bn%5D+%2B+b_1+w%5Bn-1%5D+%2B+%5Ccdots+%2B+b_M+w%5Bn-M%5D+&bg=ffffff&fg=000&s=1&c=20201002)
The frequency response of this generalized filter is well known

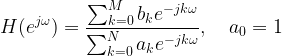


The transfer function H(ejɷ) is a pole-zero transfer function. It is best suited for modelling complex spectra having well defined resonant peaks and nulls.
Next post: Comparing AR and ARMA model – minimization of squared error
Rate this article: Note: There is a rating embedded within this post, please visit this post to rate it.
Related topics
Books by the author
 Wireless Communication Systems in Matlab Second Edition(PDF) Note: There is a rating embedded within this post, please visit this post to rate it. |  Digital Modulations using Python (PDF ebook) Note: There is a rating embedded within this post, please visit this post to rate it. |  Digital Modulations using Matlab (PDF ebook) Note: There is a rating embedded within this post, please visit this post to rate it. |
| Hand-picked Best books on Communication Engineering Best books on Signal Processing |
||




![\mathbb{\theta}=[ \theta_1, \theta_2, ..., \theta_p]^{T}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7B%5Ctheta%7D%3D%5B+%5Ctheta_1%2C+%5Ctheta_2%2C+...%2C+%5Ctheta_p%5D%5E%7BT%7D+&bg=ffffff&fg=000&s=0&c=20201002)

![\mathbb{\hat{\theta}} = [ \hat{\theta_1}, \hat{\theta_2}, ..., \hat{\theta_p} ]^{T}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7B%5Chat%7B%5Ctheta%7D%7D+%3D+%5B+%5Chat%7B%5Ctheta_1%7D%2C+%5Chat%7B%5Ctheta_2%7D%2C+...%2C+%5Chat%7B%5Ctheta_p%7D+%5D%5E%7BT%7D&bg=ffffff&fg=000&s=0&c=20201002)

![E[\hat{\theta}] = \theta](https://s0.wp.com/latex.php?latex=E%5B%5Chat%7B%5Ctheta%7D%5D+%3D+%5Ctheta+&bg=ffffff&fg=000&s=0&c=20201002)

![C_{\hat{\theta}} =var ( \hat{\theta} ) = E \left[ ( \hat{\theta} - \theta )( \hat{\theta} - \theta )^T \right]](https://s0.wp.com/latex.php?latex=C_%7B%5Chat%7B%5Ctheta%7D%7D+%3Dvar+%28+%5Chat%7B%5Ctheta%7D+%29+%C2%A0%3D+E+%5Cleft%5B+%C2%A0%28+%5Chat%7B%5Ctheta%7D+-+%5Ctheta+%29%28+%5Chat%7B%5Ctheta%7D+-+%5Ctheta+%29%5ET+%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)

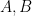

![\theta = [A,B,C] ^T](https://s0.wp.com/latex.php?latex=%5Ctheta+%3D+%5BA%2CB%2CC%5D+%5ET+&bg=ffffff&fg=000&s=0&c=20201002)

![C_{\hat{\theta}} = \left[ \begin{matrix} var(\hat{A}) & cov(\hat{A},\hat{B}) & cov(\hat{A},\hat{C}) \\ cov(\hat{B},\hat{A}) & var(\hat{B}) & cov(\hat{B},\hat{C}) \\ cov(\hat{C},\hat{A}) & cov(\hat{C},\hat{B}) & var(\hat{C}) \end{matrix} \right]](https://s0.wp.com/latex.php?latex=C_%7B%5Chat%7B%5Ctheta%7D%7D+%3D+%5Cleft%5B+%C2%A0%5Cbegin%7Bmatrix%7D+var%28%5Chat%7BA%7D%29+%26+cov%28%5Chat%7BA%7D%2C%5Chat%7BB%7D%29+%26+cov%28%5Chat%7BA%7D%2C%5Chat%7BC%7D%29+%5C%5C+%C2%A0cov%28%5Chat%7BB%7D%2C%5Chat%7BA%7D%29+%26+var%28%5Chat%7BB%7D%29+%26+cov%28%5Chat%7BB%7D%2C%5Chat%7BC%7D%29+%5C%5C+%C2%A0cov%28%5Chat%7BC%7D%2C%5Chat%7BA%7D%29+%26+cov%28%5Chat%7BC%7D%2C%5Chat%7BB%7D%29+%26+var%28%5Chat%7BC%7D%29+%5Cend%7Bmatrix%7D+%5Cright%5D%C2%A0+&bg=ffffff&fg=000&s=1&c=20201002)



![[I(\theta)] _{ij} = \displaystyle{-E \left[ \frac{\delta^2}{\delta \theta_i \delta \theta_j} ln \; p(x;\theta) \right]} \; \; i,j =1,2,3,\cdots,p](https://s0.wp.com/latex.php?latex=%C2%A0%5BI%28%5Ctheta%29%5D+_%7Bij%7D+%3D+%5Cdisplaystyle%7B-E+%5Cleft%5B+%C2%A0%5Cfrac%7B%5Cdelta%5E2%7D%7B%5Cdelta+%5Ctheta_i+%5Cdelta+%5Ctheta_j%7D+ln+%5C%3B+p%28x%3B%5Ctheta%29+%5Cright%5D%7D%C2%A0+%5C%3B+%5C%3B+i%2Cj+%3D1%2C2%2C3%2C%5Ccdots%2Cp+&bg=ffffff&fg=000&s=1&c=20201002)

![\displaystyle{E \left[ \frac{\delta}{ \delta \theta} ln\; p(x;\theta) \right] = 0} \;\;\; \forall \theta](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7BE+%5Cleft%5B+%5Cfrac%7B%5Cdelta%7D%7B+%5Cdelta+%5Ctheta%7D+ln%5C%3B+p%28x%3B%5Ctheta%29+%5Cright%5D+%3D+0%7D+%5C%3B%5C%3B%5C%3B+%5Cforall+%5Ctheta+&bg=ffffff&fg=000&s=1&c=20201002)



![\left[ C_{(\hat{\theta})} \right]_{ii} \geq \left[ I^{-1}(\theta) \right]_{ii}](https://s0.wp.com/latex.php?latex=%C2%A0+%5Cleft%5B+C_%7B%28%5Chat%7B%5Ctheta%7D%29%7D+%5Cright%5D_%7Bii%7D+%5Cgeq+%C2%A0%5Cleft%5B+I%5E%7B-1%7D%28%5Ctheta%29+%5Cright%5D_%7Bii%7D%C2%A0+&bg=ffffff&fg=000&s=1&c=20201002)