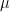Markov chains are useful in computing the probability of events that are observable. However, in many real world applications, the events that we are interested in are usually hidden, that is we don’t observe them directly. These hidden events need to be inferred. For example, given a sentence in a natural language we only observe the words and characters directly. The parts-of-speech from the sentence are hidden, they have to be inferred. This bring us to the following topic– the hidden Markov models.
Hidden Markov models enables us to visualize both observations and the associated hidden events. Let’s consider an example for understanding the concept.
The cheating casino and the gullible gambler
Consider a dishonest casino that deceives it player by using two types of die : a fair die (F) and a loaded die (L). For a fair die, each of the faces has the same probability of landing facing up. For the loaded die, the probabilities of the faces are skewed as given next


When the gambler throws the die, numbers land facing up. These are our observations at a given time t (denoted as Ot = {1,2,3,4,5,6}). At any given time t, whether these number are rolled from a fair die (state St = F) or a loaded die (St = L), is unknown to an observer and therefore they are the hidden events.
Emission probabilities
The probabilities associated with the observations are the observation likelihoods, also called emission probabilities (B).


Initial probabilities
The initial probability of starting (at time = 0) with any of fair die or loaded die (hidden event) is 50%.


Transition probabilities
A gullible gambler switches from the fair die to loaded die with 10% probability. He switches back from loaded die to fair die with 5% probability.
The probabilities of transitioning from one hidden event to another is described by the transition probability matrix (A). The elements of the probability transition matrix, are the transition probabilities (pij) of moving from one hidden state i to another hidden state j.


The transition probabilities from time t-1 to t, for the hidden events are


Therefore, the transition probability matrix is


Based on the given information so far, a probability model is constructed. This is the Hidden Markov Model (HMM) for the given problem.


Assumptions
We saw, in previous article, that the Markov models come with assumptions. Similarly, HMMs models also have such assumptions.
1. Assumption on probability of hidden states
In the model given here, the probability of a given hidden state depends only on the previous hidden state. This is a typical first order Markov chain assumption.


2. Assumption on Output
The probability of any observation (output) depends on the hidden state that produce it and not on any other hidden state or output observations.


Problems and Algorithms
Let’s briefly discuss the different problems and the related algorithms for HMMs. The algorithms will be explained in detail in the future articles.
In the dishonest casino, the gambler rolls the following numbers:


1. Evaluation
Given the model of the dishonest casino, what is the probability of obtaining the above sequence ? This is a typical evaluation problem in HMMs. Forward algorithm is applied for such evaluation problems.
2. Decoding
What is the most likely sequence of die (hidden states) given the above sequence ? Such problems are addressed by Viterbi decoding.
What is the probability of fourth die being loaded, given the above sequence ? Forward-backward algorithm to our rescue.
3. Learning
Learning problems involve parametrization of the model. In learning problems, we attempt to find the various parameters (transition probabilities, emission probabilities) of the HMM, given the observation. Baum-Welch algorithm helps us to find the unknown parameters of a HMM.
Some real-life examples
Here are some real-life examples of HMM applications:
- Speech recognition: HMMs are widely used in speech recognition systems to model the variability of speech sounds. In this application, the observable events are the acoustic features of the speech signal, while the hidden states represent the phonemes or words that generate the speech signal.
- Handwriting recognition: HMMs can be used to recognize handwritten characters by modeling the temporal variability of the pen strokes. In this application, the observable events are the coordinates of the pen on the writing surface, while the hidden states represent the letters or symbols that generate the handwriting.
- Stock price prediction: HMMs can be used to model the behavior of stock prices and predict future price movements. In this application, the observable events are the daily price movements, while the hidden states represent the different market conditions that generate the price movements.
- Gene prediction: HMMs can be used to identify genes in DNA sequences. In this application, the observable events are the nucleotides in the DNA sequence, while the hidden states represent the different regions of the genome that generate the sequence.
- Natural language processing: HMMs are used in many natural language processing tasks, such as part-of-speech tagging and named entity recognition. In these applications, the observable events are the words in the text, while the hidden states represent the grammatical structures or semantic categories that generate the text.
- Image and video analysis: HMMs can be used to analyze images and videos, such as for object recognition and tracking. In this application, the observable events are the pixel values in the image or video, while the hidden states represent the object or motion that generates the pixel values.
- Bio-signal analysis: HMMs can be used to analyze physiological signals, such as electroencephalograms (EEGs) and electrocardiograms (ECGs). In this application, the observable events are the signal measurements, while the hidden states represent the physiological states that generate the signal.
- Radar signal processing: HMMs can be used to process radar signals and detect targets in noisy environments. In this application, the observable events are the radar measurements, while the hidden states represent the presence or absence of targets.
Rate this post: Note: There is a rating embedded within this post, please visit this post to rate it.
Books by the author
 Wireless Communication Systems in Matlab Second Edition(PDF) Note: There is a rating embedded within this post, please visit this post to rate it. |  Digital Modulations using Python (PDF ebook) Note: There is a rating embedded within this post, please visit this post to rate it. |  Digital Modulations using Matlab (PDF ebook) Note: There is a rating embedded within this post, please visit this post to rate it. |
| Hand-picked Best books on Communication Engineering Best books on Signal Processing |
||



Similar topics



















![x[n]](https://s0.wp.com/latex.php?latex=x%5Bn%5D&bg=ffffff&fg=000&s=0&c=20201002)

![y[n]](https://s0.wp.com/latex.php?latex=y%5Bn%5D&bg=ffffff&fg=000&s=0&c=20201002)




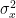





![R_{yy}[k]](https://s0.wp.com/latex.php?latex=R_%7Byy%7D%5Bk%5D&bg=ffffff&fg=000&s=0&c=20201002)

![R_{yy}[n]](https://s0.wp.com/latex.php?latex=R_%7Byy%7D%5Bn%5D&bg=ffffff&fg=000&s=0&c=20201002)

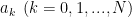











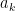



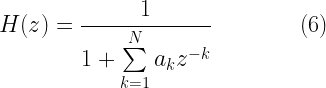



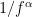




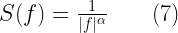












![\sum_{k=0}^{k=N} a_k y[n - k] = x[n] \quad \quad \quad \quad (8)](https://s0.wp.com/latex.php?latex=%5Csum_%7Bk%3D0%7D%5E%7Bk%3DN%7D+a_k+y%5Bn+-+k%5D+%3D+x%5Bn%5D+%5Cquad+%5Cquad+%5Cquad+%5Cquad+%288%29+&bg=ffffff&fg=000&s=2&c=20201002)







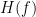







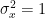
![h[n]](https://s0.wp.com/latex.php?latex=h%5Bn%5D&bg=ffffff&fg=000&s=0&c=20201002)

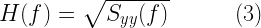



![H(f) = \sqrt{S_{yy}(f)} = \sqrt{\pi f_{max}} \left[1- \left(f/f_{max}\right)^2\right]^{-1/4} \quad (5)](https://s0.wp.com/latex.php?latex=H%28f%29+%3D+%5Csqrt%7BS_%7Byy%7D%28f%29%7D+%3D+%5Csqrt%7B%5Cpi+f_%7Bmax%7D%7D+%5Cleft%5B1-+%5Cleft%28f%2Ff_%7Bmax%7D%5Cright%29%5E2%5Cright%5D%5E%7B-1%2F4%7D+%5Cquad+%285%29+&bg=ffffff&fg=000&s=2&c=20201002)

![h[n] = C f_{max} x^{-1/4} J_{1/4} (x) , \quad \quad x = 2 \pi f_{max} |n T_s| \quad (6)](https://s0.wp.com/latex.php?latex=h%5Bn%5D+%3D+C+f_%7Bmax%7D+x%5E%7B-1%2F4%7D+J_%7B1%2F4%7D+%28x%29+%2C+%5Cquad+%5Cquad+x+%3D+2+%5Cpi+f_%7Bmax%7D+%7Cn+T_s%7C+%5Cquad+%286%29+&bg=ffffff&fg=000&s=2&c=20201002)
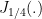

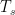





![h_{norm}[n] = x^{-1/4} J_{1/4} (x), \quad \quad x = 2 \pi f_{max} |n T_s| \quad (7)](https://s0.wp.com/latex.php?latex=h_%7Bnorm%7D%5Bn%5D+%3D+x%5E%7B-1%2F4%7D+J_%7B1%2F4%7D+%28x%29%2C+%5Cquad+%5Cquad+x+%3D+2+%5Cpi+f_%7Bmax%7D+%7Cn+T_s%7C+%5Cquad+%287%29+&bg=ffffff&fg=000&s=2&c=20201002)

![h_{w}[n] = h_{norm}[n] w_{H}[n] \quad \quad (8)](https://s0.wp.com/latex.php?latex=h_%7Bw%7D%5Bn%5D+%3D+h_%7Bnorm%7D%5Bn%5D+w_%7BH%7D%5Bn%5D+%5Cquad+%5Cquad+%288%29+&bg=ffffff&fg=000&s=2&c=20201002)

![w_{H}[n] = 0.54-0.46 \; cos(2 \pi n /N) \quad \quad (9)](https://s0.wp.com/latex.php?latex=w_%7BH%7D%5Bn%5D+%3D+0.54-0.46+%5C%3B+cos%282+%5Cpi+n+%2FN%29+%5Cquad+%5Cquad+%289%29+&bg=ffffff&fg=000&s=2&c=20201002)