What are hard and soft decision decoding
Hard decision decoding and soft decision decoding are two different methods used for decoding error-correcting codes.
With hard decision decoding, the received signal is compared to a set threshold value to determine whether the transmitted bit is a 0 or a 1. This is commonly used in digital communication systems that experience noise or interference, resulting in a low signal-to-noise ratio.
Soft decision decoding, on the other hand, treats the received signal as a probability distribution and calculates the likelihood of each possible transmitted bit based on the characteristics of the received signal. This approach is often used in modern digital communication and data storage systems where the signal-to-noise ratio is relatively high and there is a need for higher accuracy and reliability.
While soft decision decoding can achieve better error correction, it is more complex and computationally expensive than hard decision decoding.
More details
Let’s expatiate on the concepts of hard decision and soft decision decoding. Consider a simple even parity encoder given below.
|
Input Bit 1
|
Input Bit 2
|
Parity bit added by encoder
|
Codeword Generated
|
|
0
|
0
|
0
|
000
|
|
0
|
1
|
1
|
011
|
|
1
|
0
|
1
|
101
|
|
1
|
1
|
0
|
110
|
The set of all possible codewords generated by the encoder are 000,011,101 and 110.
Lets say we are want to transmit the message “01” through a communication channel.
Hard decision decoding
Case 1 : Assume that our communication model consists of a parity encoder, communication channel (attenuates the data randomly) and a hard decision decoder
The message bits “01” are applied to the parity encoder and we get “011” as the output codeword.


The output codeword “011” is transmitted through the channel. “0” is transmitted as “0 Volt and “1” as “1 Volt”. The channel attenuates the signal that is being transmitted and the receiver sees a distorted waveform ( “Red color waveform”). The hard decision decoder makes a decision based on the threshold voltage. In our case the threshold voltage is chosen as 0.5 Volt ( midway between “0” and “1” Volt ) . At each sampling instant in the receiver (as shown in the figure above) the hard decision detector determines the state of the bit to be “0” if the voltage level falls below the threshold and “1” if the voltage level is above the threshold. Therefore, the output of the hard decision block is “001”. Perhaps this “001” output is not a valid codeword ( compare this with the all possible codewords given in the table above) , which implies that the message bits cannot be recovered properly. The decoder compares the output of the hard decision block with the all possible codewords and computes the minimum Hamming distance for each case (as illustrated in the table below).
|
All possible Codewords
|
Hard decision output
|
Hamming distance
|
|
000
|
001
|
1
|
|
011
|
001
|
1
|
|
101
|
001
|
1
|
|
110
|
001
|
3
|
The decoder’s job is to choose a valid codeword which has the minimum Hamming distance. In our case, the minimum Hamming distance is “1” and there are 3 valid codewords with this distance. The decoder may choose any of the three possibility and the probability of getting the correct codeword (“001” – this is what we transmitted) is always 1/3. So when the hard decision decoding is employed the probability of recovering our data ( in this particular case) is 1/3. Lets see what “Soft decision decoding” offers …
Soft Decision Decoding
The difference between hard and soft decision decoder is as follows
- In Hard decision decoding, the received codeword is compared with the all possible codewords and the codeword which gives the minimum Hamming distance is selected
- In Soft decision decoding, the received codeword is compared with the all possible codewords and the codeword which gives the minimum Euclidean distance is selected. Thus the soft decision decoding improves the decision making process by supplying additional reliability information ( calculated Euclidean distance or calculated log-likelihood ratio)
For the same encoder and channel combination lets see the effect of replacing the hard decision block with a soft decision block.


Voltage levels of the received signal at each sampling instant are shown in the figure. The soft decision block calculates the Euclidean distance between the received signal and the all possible codewords.
| Valid codewords | Voltage levels at each sampling instant of received waveform | Euclidean distance calculation | Euclidean distance |
|
0 0 0
( 0V 0V 0V )
|
0.2V 0.4V 0.7V
|
(0-0.2)2+ (0-0.4)2+ (0-0.7)2
|
0.69
|
|
0 1 1
( 0V 1V 1V )
|
0.2V 0.4V 0.7V
|
(0-0.2)2+ (1-0.4)2+ (1-0.7)2
|
0.49
|
|
1 0 1
( 1V 0V 1V )
|
0.2V 0.4V 0.7V
|
(1-0.2)2+ (0-0.4)2+ (1-0.7)2
|
0.89
|
|
1 1 0
( 1V 1V 0V )
|
0.2V 0.4V 0.7V
|
(1-0.2)2+ (1-0.4)2+ (0-0.7)2
|
1.49
|
The minimum Euclidean distance is “0.49” corresponding to “0 1 1” codeword (which is what we transmitted). The decoder selects this codeword as the output. Even though the parity encoder cannot correct errors, the soft decision scheme helped in recovering the data in this case. This fact delineates the improvement that will be seen when this soft decision scheme is used in combination with forward error correcting (FEC) schemes like convolution codes , LDPC etc
From this illustration we can understand that the soft decision decoders uses all of the information ( voltage levels in this case) in the process of decision making whereas the hard decision decoders does not fully utilize the information available in the received signal (evident from calculating Hamming distance just by comparing the signal level with the threshold whereby neglecting the actual voltage levels).
Note: This is just to illustrate the concept of Soft decision and Hard decision decoding. Prudent souls will be quick enough to find that the parity code example will fail for other voltage levels (e.g. : 0.2V , 0.4 V and 0.6V) . This is because the parity encoders are not capable of correcting errors but are capable of detecting single bit errors.
Soft decision decoding scheme is often realized using Viterbi decoders. Such decoders utilize Soft Output Viterbi Algorithm (SOVA) which takes into account the apriori probabilities of the input symbols producing a soft output indicating the reliability of the decision.
Rate this article: Note: There is a rating embedded within this post, please visit this post to rate it.
For further reading
Books by the author
 Wireless Communication Systems in Matlab Second Edition(PDF) Note: There is a rating embedded within this post, please visit this post to rate it. |  Digital Modulations using Python (PDF ebook) Note: There is a rating embedded within this post, please visit this post to rate it. |  Digital Modulations using Matlab (PDF ebook) Note: There is a rating embedded within this post, please visit this post to rate it. |
| Hand-picked Best books on Communication Engineering Best books on Signal Processing |
||






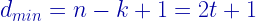
















































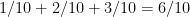

![E\left[X \right] = \int_{-\infty }^{\infty}xf_X(x)dx](https://s0.wp.com/latex.php?latex=E%5Cleft%5BX+%5Cright%5D+%3D+%5Cint_%7B-%5Cinfty+%7D%5E%7B%5Cinfty%7Dxf_X%28x%29dx+&bg=ffffff&fg=000&s=1&c=20201002)

![E\left[X \right] = \mu{_X} = \sum_{-\infty }^{\infty}x_{i}p_{i}](https://s0.wp.com/latex.php?latex=E%5Cleft%5BX+%5Cright%5D+%3D+%5Cmu%7B_X%7D+%3D+%5Csum_%7B-%5Cinfty+%7D%5E%7B%5Cinfty%7Dx_%7Bi%7Dp_%7Bi%7D+&bg=ffffff&fg=000&s=1&c=20201002)

![var \left[X\right] = \int_{-\infty }^{\infty} \left(x - E\left[X \right] \right)^2 f_X(x) dx](https://s0.wp.com/latex.php?latex=var+%5Cleft%5BX%5Cright%5D+%3D+%5Cint_%7B-%5Cinfty+%7D%5E%7B%5Cinfty%7D+%5Cleft%28x+-+E%5Cleft%5BX+%5Cright%5D+%5Cright%29%5E2+f_X%28x%29+dx+&bg=ffffff&fg=000&s=1&c=20201002)

![var \left[X\right] = {\sigma^2}_X = \sum_{-\infty }^{\infty} \left( x_i - \mu_X\right)^2 p_{i}](https://s0.wp.com/latex.php?latex=var+%5Cleft%5BX%5Cright%5D+%3D+%7B%5Csigma%5E2%7D_X+%3D+%5Csum_%7B-%5Cinfty+%7D%5E%7B%5Cinfty%7D+%5Cleft%28+x_i+-+%5Cmu_X%5Cright%29%5E2+p_%7Bi%7D+&bg=ffffff&fg=000&s=1&c=20201002)





![E\left[cX\right] = c E\left[X\right]](https://s0.wp.com/latex.php?latex=E%5Cleft%5BcX%5Cright%5D+%3D+c+E%5Cleft%5BX%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)

![E\left[X+c\right] = E\left[X\right]+c](https://s0.wp.com/latex.php?latex=E%5Cleft%5BX%2Bc%5Cright%5D+%3D+E%5Cleft%5BX%5Cright%5D%2Bc+&bg=ffffff&fg=000&s=1&c=20201002)

![E\left[c\right] = c](https://s0.wp.com/latex.php?latex=E%5Cleft%5Bc%5Cright%5D+%3D+c+&bg=ffffff&fg=000&s=1&c=20201002)

![var\left[cX\right] = c^2 var\left[X\right]](https://s0.wp.com/latex.php?latex=var%5Cleft%5BcX%5Cright%5D+%3D+c%5E2+var%5Cleft%5BX%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)

![var\left[X+c\right] = var\left[X\right]](https://s0.wp.com/latex.php?latex=var%5Cleft%5BX%2Bc%5Cright%5D+%3D+var%5Cleft%5BX%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)

![var\left[c\right] = 0](https://s0.wp.com/latex.php?latex=var%5Cleft%5Bc%5Cright%5D+%3D+0+&bg=ffffff&fg=000&s=1&c=20201002)











