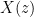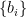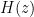Mathuranathan Viswanathan, is an author @ gaussianwaves.com that has garnered worldwide readership. He is a masters in communication engineering and has 12 years of technical expertise in channel modeling and has worked in various technologies ranging from read channel, OFDM, MIMO, 3GPP PHY layer, Data Science & Machine learning.
Note: There is a rating embedded within this post, please visit this post to rate it.
In modulations, information is mapped on to changes in frequency, phase or amplitude (or a combination of them) of a carrier signal. Multiplexing deals with allocation/accommodation of users in a given bandwidth (i.e. it deals with allocation of available resource). OFDM is a combination of modulation and multiplexing. In this technique, the given resource (bandwidth) is shared among individual modulated data sources. Normal modulation techniques (like AM, PM, FM, BPSK, QPSK, etc.., ) are single carrier modulation techniques, in which the incoming information is modulated over a single carrier. OFDM is a multicarrier modulation technique, which employs several carriers, within the allocated bandwidth, to convey the information from source to destination. Each carrier may employ one of the several available digital modulation techniques (BPSK, QPSK, QAM etc..,).
Why OFDM
OFDM is very effective for communication over channels with frequency selective fading ( different frequency components of the signal experience different fading). It is very difficult to handle frequency selective fading in the receiver , in which case, the design of the receiver is hugely complex. Instead of trying to mitigate frequency selective fading as a whole (which occurs when a huge bandwidth is allocated for the data transmission over a frequency selective fading channel), OFDM mitigates the problem by converting the entire frequency selective fading channel into small flat fading channels (as seen by the individual subcarriers). Flat fading is easier to combat (compared to frequency selective fading) by employing simple error correction and equalization schemes.
Difference between FDM and OFDM:
OFDM is a special case of FDM ( Frequency Division Multiplexing). In FDM, the given bandwidth is subdivided among a set of carriers. There is no relationship between the carrier frequencies in FDM. For example, consider that the given bandwidth has to be divided among 5 carriers (say a,b,c,d,e). There is no relationship between the subcarriers ; a,b,c,d and e can anything within the given bandwidth.
If the carriers are harmonics, say (b=2a,c=3a,d=4a,d=5a , integral multiple of fundamental component a ) then they become orthogonal. This is a special case of FDM, which is called OFDM (as implied by the word – ‘orthogonal’ in OFDM)
Designing OFDM Transmitter:
Consider that we want to send the following data bits using OFDM : D = {d0,d1,d2,…). The first thing that should be considered in designing the OFDM transmitter is the number of subcarriers required to send the given data. As a generic case, lets assume that we have N subcarriers. Each subcarriers are centered at frequencies that are orthogonal to each other (usually multiples of frequencies).
The second design parameter could be the modulation format that we wish to use. An OFDM signal can be constructed using anyone of the following digital modulation techniques namely BPSK, QPSK, QAM etc.., The data (D) has to be first converted from serial stream into parallel stream depending on the number of sub-carriers (N). Since we assumed that there are N subcarriers allowed for the OFDM transmission, we name the subcarriers from 0 to N-1. Now, the Serial to Parallel converter takes the serial stream of input bits and outputs N parallel streams (indexed from 0 to N-1). These parallel streams are individually converted into the required digital modulation format (BPSK, QPSK, QAM etc..,). Lets call this output S0,S1,..SN. The conversion of parallel data (D) into the digitally modulated data (S) is usually achieved by a constellation mapper, which is essentially a look up table (LUT). Once the data bits are converted to required modulation format, they need to be superimposed on the required orthogonal subcarriers for transmission. This is achieved by a series of N parallel sinusoidal oscillators tuned to N orthogonal frequencies (f0,f1,…fN-1). Finally, the resultant output from the N parallel arms are summed up together to produce the OFDM signal.
The following figure illustrates the basic concept of OFDM transmission (note: In order to give a simple explanation to illustrate the underlying concept,the usual IFFT/FFT blocks that are used in actual OFDM system, are not used in the block diagram) .
OFDM Transmitter
Example:
The first example illustrates the concept of OFDM transmission with BPSK modulation as its underlying modulation format. The second example illustrates the OFDM transmission with pi/4 shifted QPSK modulation. Here 5 orthogonal subcarriers are assumed for the OFDM transmission.
The phenomenon of Rayleigh Flat fading and its simulation using Clarke’s model and Young’s model were discussed in the previous posts. The performance (Eb/N0 Vs BER) of BPSK modulation (with coherent detection) over Rayleigh Fading channel and its comparison over AWGN channel is discussed in this post.
We first investigate the non-coherent detection of BPSK over Rayleigh Fading channel and then we move on to the coherent detection. For both the cases, we consider a simple flat fading Rayleigh channel (modeled as a – single tap filter – with complex impulse response – h). The channel also adds AWGN noise to the signal samples after it suffers from Rayleigh Fading.
The received signal y can be represented as
$$ y=hx+n $$
where n is the noise contributed by AWGN which is Gaussian distributed with zero mean and unit variance and h is the Rayleigh Fading response with zero mean and unit variance. (For a simple AWGN channel without Rayleigh Fading the received signal is represented as y=x+n).
Non-Coherent Detection:
In non-coherent detection, prior knowledge of the channel impulse response (“h” in this case) is not known at the receiver. Consider the BPSK signaling scheme with ‘x=+/- a’ being transmitted over such a channel as described above. This signaling scheme fails completely (in non coherent detection scheme), even in the absence of noise, since the phase of the received signal y is uniformly distributed between 0 and 2pi regardless of whether x[m]=+a or x[m]=-a is transmitted. So the non coherent detection of the BPSK signaling is not a suitable method of detection especially in a Fading environment.
Coherent Detection:
In coherent detection, the receiver has sufficient knowledge about the channel impulse response.Techniques like pilot transmissions are used to estimate the channel impulse response at the receiver, before the actual data transmission could begin. Lets consider that the channel impulse response estimate at receiver is known and is perfect & accurate.The transmitted symbols (‘x’) can be obtained from the received signal (‘y’) by the process of equalization as given below.
$$ \hat{y}=\frac{y}{h}=\frac{hx+n}{h}=x+z $$
here z is still an AWGN noise except for the scaling factor 1/h. Now the detection of x can be performed in a manner similar to the detection in AWGN channels.
The input binary bits to the BPSK modulation system are detected as
where h(τ,t) is the time varying impulse response of the multipath fading channel having L multipaths and hi(t) and τi(t) denote the time varying complex gain and excess delay of the i-th path. The above mentioned impulse response can be implemented as a FIR filter as shown below :
Multipath Fading phenomena – modelled as a Time Varying FIR Filter
The channel under consideration can be modeled as a multipath fading channel in which the impulse response may follow distributions like Rayleigh distribution ( in which there is no Line of Sight (LOS) ray between transmitter and receiver) or as Rician distribution ( dominant LOS path exist between transmitter and receiver), Nagami distribution, Weibull distribution etc.
Different methods of simulation techniques were proposed to simulate/model multipath channels. Some of the models include clarke’s reference model, Jake’s model, Young’s model , filtered gaussian noise model etc.
A Rayleigh fading channel (flat fading channel) is considered in this text.For simplicity we fix the excess delays τi(t) in the above equation and we generate hi(t) that follows Rayleigh distribution. In this simulation Clarke’s Rayleigh fading model is used. This model is also called mathematical reference model and is commonly considered as a computationally inefficient model compared to Jake’s Rayleigh Fading simulator.
Theory of Rayleigh Fading:
Lets denote the complex impulse response h(t) of the flat fading channel as follows :
$$ h(t) = h_{I}(t) + jh_{Q}(t) $$
where hI(t) and hQ(t) are zero mean gaussian distributed. Therefore the fading envelope is Rayleigh distributed and is given by
We will use the Clarke’s Rayleigh Fading model (given below) and check the statistical properties of the random process generated by the model against the statistical properties of Rayleigh distribution (given above).
Clarke’s Rayleigh Fading model:
The random process of flat Rayleigh fading with M multipaths can be simulated with the sum-of-sinusoid method described as
Simulation:
1) The rayleigh fading model is implemented as a function in matlab with following parameters:
M=number of multipaths in the fading channel, N = number of samples to generate, fd=maximum Doppler spread in Hz, Ts = sampling period.
function [h]=rayleighFading(M,N,fd,Ts)
% function to generate rayleigh Fading samples based on Clarke's model
% M = number of multipaths in the channel
% N = number of samples to generate
% fd = maximum Doppler frequency
% Ts = sampling period
% Author : Mathuranathan for https://www.gaussianwaves.com
%Code available in the ebook - Simulation of Digital Communication Systems using Matlab
2)The above mentioned function is used to generate Rayleigh Fading samples with the following values for the function arguments. M=15; N=10^5; fd=100 Hz;Ts=0.0001 second;
Investigation of Statistical Properties of samples generated using Clarke’s model:
3) Mean and Variance of the real and imaginary parts of generated samples are
Mean of real part ~=0
Mean of imag part ~=0
Variance of real part = 0.4989 ~=0.5
Variance of imag part = 0.4989 ~=0.5
The results implies that the mean of the real and imaginary parts are same and are equal to zero.The variance of the real and imaginary parts are approximately equal to 0.5.
4)Next, the pdf of the real part of the simulated samples are plotted and compared against the pdf of Gaussian distribution (with mean=0 and variance =0.5)
Real Part of simulated samples exhibiting Gaussian Distribution characteristics
5)The pdf of the generated Rayleigh fading samples are plotted and compared against pdf of Rayleigh distribution (with variance=1)
PDF of simulated Rayleigh Fading Samples
6) From 4) and 5) we confirm that the samples generated by Clarke’s model follows Rayleigh distribution (with variance = 1) and the real and imaginary part of the samples follow Gaussian distribution (with mean=0 and variance =0.5).
7) The Magnitude and Phase response of the generated Rayleigh Fading samples are plotted here.
The Magnitude and Phase response of the generated Rayleigh Fading samples
Modified Duobinary Signaling is an extension of duobinary signaling. It has the advantage of zero PSD at low frequencies (especially at DC ) that is suitable for channels with poor DC response. It correlates two symbols that are 2T time instants apart, whereas in duobinary signaling, symbols that are 1T apart are correlated.
The general condition to achieve zero ISI is given by
As discussed in a previous article, in correlative coding , the requirement of zero ISI condition is relaxed as a controlled amount of ISI is introduced in the transmitted signal and is counteracted in the receiver side
In the case of modified duobinary signaling, the above equation is modified as
which states that the ISI is limited to two alternate samples. Here a controlled or “deterministic” amount of ISI is introduced and hence its effect can be removed upon signal detection at the receiver.
Modified Duobinary Signaling:
The following figure shows the modified duobinary signaling scheme (click to enlarge).
Modified DuoBinary Signaling
Encoding Process:
1) an = binary input bit; an ∈ {0,1}.
2) bn = NRZ polar output of Level converter in the precoder and is given by,
where ak is the precoded output (before level converter).
3) yn can be represented as
Note that the samples bn are uncorrelated ( i.e either +d for “1” or -d for “0” input). On the other-hand,the samples yn are correlated ( i.e. there are three possible values +2d,0,-2d depending on ak and ak-2). Meaning that the modified duobinary encoding correlates present sample ak and the previous input sample ak-2.
4) From the diagram,impulse response of the modified duobinary encoder is computed as
Decoding Process:
5) The receiver consists of a modified duobinary decoder and a postcoder (inverse of precoder). The decoder implements the following equation (which can be deduced from the equation given under step 3 (see above))
This equation indicates that the decoding process is prone to error propagation as the estimate of present sample relies on the estimate of previous sample. This error propagation is avoided by using a precoder before modified-duobinary encoder at the transmitter and a postcoder after the modified-duobinary decoder. The precoder ties the present sample and the sample that precedes the previous sample ( correlates these two samples) and the postcoder does the reverse process.
6) The entire process of modified-duobinary decoding and the postcoding can be combined together as one algorithm. The following decision rule is used for detecting the original modified-duobinary signal samples {an} from {yn}
The condition for zero ISI (Inter Symbol Interference) is
which states that when sampling a particular symbol (at time instant nT=0), the effect of all other symbols on the current sampled symbol is zero.
As discussed in the previous article, one of the practical ways to mitigate ISI is to use partial response signaling technique ( otherwise called as “correlative coding”). In partial response signaling, the requirement of zero ISI condition is relaxed as a controlled amount of ISI is introduced in the transmitted signal and is counteracted in the receiver side.
By relaxing the zero ISI condition, the above equation can be modified as,
which states that the ISI is limited to two adjacent samples. Here we introduce a controlled or “deterministic” amount of ISI and hence its effect can be removed upon signal detection at the receiver.
Duobinary Signaling:
The following figure shows the duobinary signaling scheme.
Figure 1: DuoBinary signaling scheme
Encoding Process:
1) an = binary input bit; an ∈ {0,1}. 2) bn = NRZ polar output of Level converter in the precoder and is given by,
3) yn can be represented as
Note that the samples bn are uncorrelated ( i.e either +d for “1” or -d for “0” input). On the other-hand, the samples yn are correlated ( i.e. there are three possible values +2d,0,-2d depending on an and an-1). Meaning that the duobinary encoding correlates present sample an and the previous input sample an-1.
4) From the diagram,impulse response of the duobinary encoder is computed as
Decoding Process:
5) The receiver consists of a duobinary decoder and a postcoder (inverse of precoder).The duobinary decoder implements the following equation (which can be deduced from the equation given under step 3 (see above))
This equation indicates that the decoding process is prone to error propagation as the estimate of present sample relies on the estimate of previous sample. This error propagation is avoided by using a precoder before duobinary encoder at the transmitter and a postcoder after the duobinary decoder. The precoder ties the present sample and previous sample ( correlates these two samples) and the postcoder does the reverse process.
6) The entire process of duobinary decoding and the postcoding can be combined together as one algorithm. The following decision rule is used for detecting the original duobinary signal samples {an} from {yn}
Note: There is a rating embedded within this post, please visit this post to rate it.
The following is a function to generate a Walsh Hadamard Matrix of given codeword size. The codeword size has to be a power of 2.
function [H]=generateHadamardMatrix(codeSize)
%[H]=generateHadamardMatrix(codeSize);
% Function to generate Walsh-Hadamard Matrix where "codeSize" is the code
% length of walsh code. The first matrix gives us two codes; 00, 01. The second
% matrix gives: 0000, 0101, 0011, 0110 and so on
% Author: Mathuranathan for https://www.gaussianwaves.com
% License: Creative Commons: Attribution-NonCommercial-ShareAlike 3.0
% Unported
%codeSize=64; %For testing only
N=2;
H=[0 0 ; 0 1];
if bitand(codeSize,codeSize-1)==0
while(N~=codeSize)
N=N*2;
H=repmat(H,[2,2]);
[m,n]=size(H);
%Invert the matrix located at the bottom right hand corner
for i=m/2+1:m,
for j=n/2+1:n,
H(i,j)=~H(i,j);
end
end
end
else
disp('INVALID CODE SIZE:The code size must be a power of 2');
end
Example:
To Generate Walsh Codes used in IS-95 (which utilizes 64 Walsh codes of size 64 bits each, use : [H]=generateHadamardMatrix(64). This will generate 64 Walsh Codes of length 64-bits (for each code).
Test Program:
Click Here to download
Also given below is a program to test the cross-correlation and auto-correlation of Walsh code. A set of 8-Walsh codes are used for this purpose.
% Matlab Program to test Walsh Hadamard Codes and to test their orthogonality
% Plots cross-correlation and auto correlation of Walsh Hadamard Codes
% Author: Mathuranathan Viswanathan for https://www.gaussianwaves.com
% License: Creative Commons: Attribution-NonCommercial-ShareAlike 3.0
% Unported
codeSize=8;
[H]=generateHadamardMatrix(codeSize);
%-----------------------------------------------------------
%Cross-Correlation of Walsh Code 1 with rest of Walsh Codes
h = zeros(1, codeSize-1); %For dynamic Legends
s = cell(1, codeSize-1); %For dynamic Legends
for rows=2:codeSize
[crossCorrelation,lags]=crossCorr(H(1,:),H(rows,:));
h(rows-1)=plot(lags,crossCorrelation);
s{rows-1} = sprintf('Walsh Code Sequence #-%d', rows);
hold all;
end
%Dynamic Legends
% Select the plots to include in the legend
index = 1:codeSize-1;
% Create legend for the selected plots
legend(h(index),s{index});
title('Cross Correlation of Walsh Code 1 with the rest of the Walsh Codes');
ylabel('Cross Correlation');
xlabel('Lags');
%-----------------------------------------------------------
%AutoCorrelation of Walsh Code - 1
autoCorr2(H(2,:),8,2,1);
Simulation Results
From the plots below, it can be ascertained that the Walsh codes has excellent cross-correlation property and poor autocorrelation property. Excellent cross-correlation property (zero cross-correlation) implies orthogonality, which makes it suitable for CDMA applications.
Note: There is a rating embedded within this post, please visit this post to rate it.
IS-95 CDMA Standard uses three types of codes namely 1) Long code 2) Short code and 3) Walsh Hadamard codes.
IS-95 Architecture
Long Code:
Long codes run at 1.2288 Mb/s and are 42 bits longs (created using a 42 bits LFSR register). It takes approx 41.2 days to repeat a long code at this rate. It is used for both encryption and spreading. Encryption is achieved by using a mask called Long Code mask which is a created using a 64-bit authentication key called A-key (assigned by CAVE protocol) and Electronic Serial Number ( ESN – assigned each user based on the mobile number). The Long code changes each time a new connection is created.
Short Code:
Short code is a m-sequence of lenght 215-1 (created using a 15 bit LFSR register) and is used for synchronization purpose in the forward as well as reverse links. The short code is also used to identify cell/base station connection in the forward link. It repeats approx 75 times in 2 seconds. Each base station is assigned a cyclically shifted version of same short code sequence to differentiate the base stations.This is also called PN offset in CDMA jargon. Since the cyclically shifted versions of a same m-sequence offer poor correlation, it is easier to differentiate between different base station links.
During the initial call setup stage, a mobile phone tries to find a base station (in 2 seconds max allowed time), if it find a base station, the mobile phone is validated using a database by the base station and is assigned a PN Short code sequence. This PN short code sequence uniquely identifies the connection between the particular base station and the mobile devices served under that base station.
In reality two short code sequences are used one for I channel and another for Q channel (used in spreading and de-spreading).
Walsh Hadamard Code:
CDMA used another type of code called Walsh Hadamard Code. In IS-95 CDMA, 64 Walsh codes are used per base station. This enables to create 64 separate channels per base stations (i.e. a base station can handle maximum 64 unique users at a given time).In CDMA-2000 standard, 256 Walsh codes are used to handle maximum 256 unique users under a base.
Walsh codes are created using Hadamard Matrix and transform. The codes under a family of Walsh codes, posses a beautiful property of being orthogonal to each other (what else do we want to identify/accommodate users ?).
The first matrix in a Hadamard transform is
$$ H1=\begin{bmatrix} 0 & 0\\ 0 & 1 \end{bmatrix} $$
Each row of a Hadamard matrix represent a unique Walsh code and all the Walsh codes in a given matrices are orthogonal. The length of the row of the matrix ( number of columns otherwise) is the code-length of the Walsh codes. To get a 64-Walsh code matrix we need to transform the matrices till H8 (this matrix contains 64 rows – representing 64 walsh codes and each code is of 64 bits length).
Walsh codes posses excellent cross-correlation property ( cross correlation of one Walsh code with another is always zero) therefore possess excellent orthogonality property. The auto-correlation property of Walsh code is very poor and so it is used only in synchronous CDMA networks, which maintains a synchronizing mechanism to identify the starting of the codeword.
Actually in IS-95, out of the 64 available Walsh codes, Walsh code 0 is reserved for pilot channel, 1 to 7 are assigned for synch channel and paging channels and the remaining 8-63 are assigned for users (traffic channel).
Spectral leakage due to FFT is caused by: mismatch between desired tone and chosen frequency resolution, time limiting an observation. Understand the concept using hands-on examples.
Limits of frequency domain studies
Frequency Transform is used to study a signal’s frequency domain characteristics. When using FFT to study the frequency domain characteristics of a signal, there are two limits : 1) The detect-ability of a small signal in the presence of a larger one; 2) frequency resolution – which distinguishes two different frequencies.
In practice, the measured signals are limited in time and the FFT calculates the frequency transform over a certain number of discrete frequencies called bins.
Spectral Leakage:
In reality, signals are of time-limited nature and nothing can be known about the signal beyond the measured interval. For example, if the measurement of a never ending continuous train of sinusoidal wave is of interest, at some point of time we need to terminate our observation to do further analysis. The limit on the time is also posed by limitations of the measurement system itself (example: buffer size), besides other factors.
It is often said that the FFT implicitly assumes that the signal essentially repeats itself after the measured interval and hence the FFT assumes the signal to be continuous (conceptually, juxtapose the measured signal repetitively). This lead to glitches in the assumed signal (see Figure 1). When the measurement time is purposefully made to be a non-integral multiple of the actual signal rate, these sharp discontinuities will spread out in the frequency domain leading to spectral leakage. This explanation for spectral leakage need to be carefully investigated.
Figure 1:Impact of observation interval on FFT
Experiment 1: Effect of FFT length and frequency resolution
Consider a pure sinusoidal signal of frequency \(f_x = 10 \;Hz\) and to represent in computer memory, the signal is observed for 1 second and sampled at frequency \(F_s=100 \; Hz\). Now, there will be 100 samples in the buffer and the buffer will contain integral number of waveform cycles (10 cycles in this case). The signal samples are analyzed using N-point DFT. Two cases are considered here for investigation : 1) The FFT size \(N\) is same as the length of the signal samples, i.e, N=100 and 2) FFT size set to next power of 2 that fits the signal samples i.e, N=128. The result are plotted next.
Fx=10; %Frequency of the sinusoid
Fs=100; %Sampling Frequency
observationTime = 1; %observation time in seconds
t=0:1/Fs:observationTime-1/Fs; %time base
x=sin(2*pi*Fx*t);%sampled sine wave
N=100; %DFT length same as signal length
X1 = 1/N*fftshift(fft(x,N));%N-point complex DFT of x
f1=(-N/2:1:N/2-1)*Fs/N; %frequencies on x-axis, Fs/N is the frequency resolution
N=128; %DFT length
X2 = 1/N*fftshift(fft(x,N));%N-point complex DFT of x
f2=(-N/2:1:N/2-1)*Fs/N; %frequencies on x-axis, Fs/N is the frequency resolution
figure;
subplot(3,1,1);stem(x,'r')
title('Time domain');xlabel('Sample index (n)');ylabel('x[n]');
subplot(3,1,2);stem(f1,abs(X1)); %magnitudes vs frequencies
xlim([-16,16]);title(['FFT, N=100, \Delta f=',num2str(Fs/100)]);xlabel('f (Hz)'); ylabel('|X(k)|');
subplot(3,1,3);stem(f2,abs(X2)); %magnitudes vs frequencies
xlim([-16,16]);title(['FFT, N=128, \Delta f=',num2str(Fs/128)]);xlabel('f (Hz)'); ylabel('|X(k)|');
Figure 2: Effect of FFT length and frequency resolution
One might wonder, even though the buffered samples contain integral number of waveform cycles, why the frequency spectrum registered a distinct spike at \(10 \; Hz\) when \(N=100\) and not when \(N=128\). This is due to the different frequency resolution, the measure of ability to resolve two different adjacent frequencies
For case 1, the frequency resolution is \(\Delta f = f_s/N = 100/10 = 1 Hz\). This means that the frequency bins are spaced 1 Hz apart and that is why it is able to hit the bull’s eye at 10 Hz peak.
For case 2, the frequency resolution is \(\Delta f = f_s/128 = 100/128 = 0.7813 Hz\). With this frequency resolution, the x-axis of the frequency plot cannot have exact value of 10 Hz. Instead, the nearest adjacent frequency bins are 9.375 Hz and 10.1563 Hz respectively. Therefore, the frequency spectrum cannot represent 10 Hz and the energy of the signal gets leaked to adjacent bins, leading to spectral leakage.
Experiment 2: Effect of time-limited observation
In the previous experiment, the signal wave observed for 1 second duration and that fetched whole 10 cycles in the signal buffer. Now, reduce the observation time to 0.91 second and re-run the same code, results below. In this case, the signal buffer will have 9.1 cycles of the sinewave, which is not a whole number. For case 1, the frequency resolution is 1 Hz and the FFT plot has registered a distinct peak at 10 Hz. Careful investigation of the plot will reveal very low spectral leakage even in case 1 (observe the non-zero amplitude values for the rest of the bins). This is primarily due to the change in the observation interval leading to non-integral number of cycles within the observed window. The spectral leakage in case 2, when N=128, is predominantly due to mismatch in the frequency resolution.
Figure 3: Effect of limited time observation on spectral leakage in time domain
From these two experiments, we can say that 1) The mismatch between the tone of the signal and the chosen frequency resolution (result of sampling frequency and the FFT length) leads to spectral leakage (experiment 1). 2) Time-limiting an observation (at inappropriate times), may lead to spectral leakage (experiment 2). 3) Hence, the spectral leakage from a larger signal component, if present, may significantly overshadow other smaller signals making them difficult to identify or detect.
Rate this article: Note: There is a rating embedded within this post, please visit this post to rate it.
The moving average filter is a simple Low Pass FIR (Finite Impulse Response) filter commonly used for smoothing an array of sampled data/signal. It takes samples of input at a time and takes the average of those -samples and produces a single output point. It is a very simple LPF (Low Pass Filter) structure that comes handy for scientists and engineers to filter unwanted noisy component from the intended data.
As the filter length increases (the parameter ) the smoothness of the output increases, whereas the sharp transitions in the data are made increasingly blunt. This implies that this filter has excellent time domain response but a poor frequency response.
The MA filter performs three important functions:
1) It takes input points, computes the average of those -points and produces a single output point 2) Due to the computation/calculations involved, the filter introduces a definite amount of delay 3) The filter acts as a Low Pass Filter (with poor frequency domain response and a good time domain response).
Implementation
The difference equation for a -point discrete-time moving average filter with input represented by the vector and the averaged output vector , is
For example, a -point Moving Average FIR filter takes the current and previous four samples of input and calculates the average. This operation is represented as shown in the Figure 1 with the following difference equation for the input output relationship in discrete-time.
Figure 1: Discrete-time 5-point Moving Average FIR filter
The unit delay shown in Figure 1 is realized by either of the two options:
Representing the input samples as an array in the computer memory and processing them
Using D-Flip flop shift registers for digital hardware implementation. If each discrete value of the input is represented as a -bit signal line from ADC (analog to digital converter), then we would require 4 sets of 12-Flip flops to implement the -point moving average filter shown in Figure 1.
Z-Transform and Transfer function
In signal processing, delaying a signal by sample period (unit delay) is equivalent to multiplying the Z-transform by . By applying this idea, we can find the Z-transform of the -point moving average filter in equation (2) as
The transfer function describes the input-output relationship of the system and for the -point Moving Average filter, the transfer function is given by
where, and are the filter coefficients and the order of the filter is the maximum of and
For implementing equation (6) using the filter function, the Matlab function is called as
B = [b_0, b_1, b_2, ..., b_n] %numerator coefficients
A = [a_0, a_1, a_2, ..., a_m] %denominator coefficients
y = filter(B,A,x) %filter input x and get result in y
We can note from the difference equation and transfer function of the -point moving average filter, that following values for the numerator coefficients and denominator coefficients .
Therefore, the -point moving average filter can be coded as
B = [0.2, 0.2, 0.2, 0.2, 0.2] %numerator coefficients
A = [1] %denominator coefficients
y = filter(B,A,x) %filter input x and get result in y
The numerator coefficients for the moving average filter can be conveniently expressed in short notion as shown below
L = 5
B = ones(1,L)/L %numerator coefficients
A = [1] %denominator coefficients
x = rand(1,10) %random samples for x
y = filter(B,A,x) %filter input x and get result in y
When using conv function to implement the moving average filter, the following code can be used
L = 5;
x = rand(1,10) %random samples for x;
y = conv(x,ones(1,L)/L)
There exists a difference between using conv function and filter function for implementing an FIR filter. The conv function gives the result of complete convolution and the length of the result is length(x)+ L -1. Whereas, the filter function gives the output that is of same length as that of the input .
In python, the filtering operation can be performed using the lfilter and convolve functions available in the scipy signal processing package. The equivalent python code is shown below.
import numpy as np
from scipy import signal
L=5 #L-point filter
b = (np.ones(L))/L #numerator co-effs of filter transfer function
a = np.ones(1) #denominator co-effs of filter transfer function
x = np.random.randn(10) #10 random samples for x
y = signal.convolve(x,b) #filter output using convolution
y = signal.lfilter(b,a,x) #filter output using lfilter function
Pole-zero plot and frequency response
A pole-zero plot for a filter transfer function , displays the pole and zero locations in the z-plane. In the pole-zero plot, the zeros occur at locations (frequencies) where and the poles occur at locations (frequencies) where . Equivalently, zeros occurs at frequencies for which the numerator of the transfer function in equation 6 becomes zero and the poles occurs at frequencies for which the denominator of the transfer function becomes zero.
In a pole-zero plot, the locations of the poles are usually marked by cross () and the zeros are marked as circles (). The poles and zeros of a transfer function effectively define the system response and determines the stability and performance of the filtering system.
In Matlab, the pole-zero plot and the frequency response of the -point moving average can be obtained as follows.
L=11
zplane([ones(1,L)]/L,1); %pole-zero plot
w = -pi:(pi/100):pi; %to plot frequency response
freqz([ones(1,L)]/L,1,w); %plot magnitude and phase response
Figure 2: Pole-Zero plot for L=11-point Moving Average filter
Figure 3: Magnitude and phase response of L=11-point Moving Average filter
The magnitude and phase frequency responses can be coded in Python as follows
import numpy as np
from scipy import signal
import matplotlib.pyplot as plt
L=11 #L-point filter
b = (np.ones(L))/L #numerator co-effs of filter transfer function
a = np.ones(1) #denominator co-effs of filter transfer function
w, h = signal.freqz(b,a)
plt.subplot(2, 1, 1)
plt.plot(w, 20 * np.log10(abs(h)))
plt.ylabel('Magnitude [dB]')
plt.xlabel('Frequency [rad/sample]')
plt.subplot(2, 1, 2)
angles = np.unwrap(np.angle(h))
plt.plot(w, angles)
plt.ylabel('Angle (radians)')
plt.xlabel('Frequency [rad/sample]')
plt.show()
Figure 4: Impulse response, Pole-zero plot, magnitude and phase response of L=11 moving average filter
Case study:
Following figures depict the time domain & frequency domain responses of a -point Moving Average filter. A noisy square wave signal is driven through the filter and the time domain response is obtained.
Figure 5: Processing a signal through Moving average filter of various lengths
On the first plot, we have the noisy square wave signal that is going into the moving average filter. The input is noisy and our objective is to reduce the noise as much as possible. The next figure is the output response of a 3-point Moving Average filter. It can be deduced from the figure that the 3-point Moving Average filter has not done much in filtering out the noise. We increase the filter taps to 10-points and we can see that the noise in the output has reduced a lot, which is depicted in next figure.
With L=51 tap filter, though the noise is almost zero, the transitions are blunted out drastically (observe the slope on the either side of the signal and compare them with the ideal brick wall transitions in the input signal).
From the frequency response of lower order filters (L=3, L=10), it can be asserted that the roll-off is very slow and the stop band attenuation is not good. Given this stop band attenuation, clearly, the moving average filter cannot separate one band of frequencies from another. As we increase the filter order to 51, the transitions are not preserved in time domain. Good performance in the time domain results in poor performance in the frequency domain, and vice versa. Compromise need for optimal filter design.
Rate this article: Note: There is a rating embedded within this post, please visit this post to rate it.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.



















![\begin{matrix} h_{I}(nT_{s})=\frac{1}{\sqrt{M}}\sum_{m=1}^{M}cos\left \{ 2\pi f_{D}\,cos\left [ \frac{(2m-1)\pi + \theta}{4M} \right ].nT_{s}+\alpha_{m} \right \}\\ h_{Q}(nT_{s})=\frac{1}{\sqrt{M}}\sum_{m=1}^{M}sin\left \{ 2\pi f_{D}\,cos\left [ \frac{(2m-1)\pi + \theta}{4M} \right ].nT_{s}+\beta_{m} \right \} \\ h(nT_{s}) = h_{I}(nT_{s})+jh_{Q}(nT_{s}) \\\\ where \; \theta , \; \alpha_{m} \; and \; \beta_{m}\; are\; uniformly \;distributed\; over\; [0,2\pi)\\ for \;all\; n \;and\; are\; mutually\; distributed , \; \\ f_{D} = maximum\; Doppler\; spread, \; \\ T_{s}=sampling\; period, \; n=sample \; index \end{matrix}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Bmatrix%7D+h_%7BI%7D%28nT_%7Bs%7D%29%3D%5Cfrac%7B1%7D%7B%5Csqrt%7BM%7D%7D%5Csum_%7Bm%3D1%7D%5E%7BM%7Dcos%5Cleft+%5C%7B+2%5Cpi+f_%7BD%7D%5C%2Ccos%5Cleft+%5B+%5Cfrac%7B%282m-1%29%5Cpi+%2B+%5Ctheta%7D%7B4M%7D+%5Cright+%5D.nT_%7Bs%7D%2B%5Calpha_%7Bm%7D+%5Cright+%5C%7D%5C%5C+h_%7BQ%7D%28nT_%7Bs%7D%29%3D%5Cfrac%7B1%7D%7B%5Csqrt%7BM%7D%7D%5Csum_%7Bm%3D1%7D%5E%7BM%7Dsin%5Cleft+%5C%7B+2%5Cpi+f_%7BD%7D%5C%2Ccos%5Cleft+%5B+%5Cfrac%7B%282m-1%29%5Cpi+%2B+%5Ctheta%7D%7B4M%7D+%5Cright+%5D.nT_%7Bs%7D%2B%5Cbeta_%7Bm%7D+%5Cright+%5C%7D+%5C%5C+h%28nT_%7Bs%7D%29+%3D+h_%7BI%7D%28nT_%7Bs%7D%29%2Bjh_%7BQ%7D%28nT_%7Bs%7D%29+%5C%5C%5C%5C+where+%5C%3B+%5Ctheta+%2C+%5C%3B+%5Calpha_%7Bm%7D+%5C%3B+and+%5C%3B+%5Cbeta_%7Bm%7D%5C%3B+are%5C%3B+uniformly+%5C%3Bdistributed%5C%3B+over%5C%3B+%5B0%2C2%5Cpi%29%5C%5C+for+%5C%3Ball%5C%3B+n+%5C%3Band%5C%3B+are%5C%3B+mutually%5C%3B+distributed+%2C+%5C%3B+%5C%5C+f_%7BD%7D+%3D+maximum%5C%3B+Doppler%5C%3B+spread%2C+%5C%3B+%5C%5C+T_%7Bs%7D%3Dsampling%5C%3B+period%2C+%5C%3B+n%3Dsample+%5C%3B+index+%5Cend%7Bmatrix%7D+&bg=ffffff&fg=0000A0&s=2&c=20201002)



















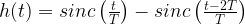













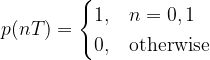







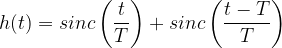




















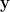

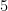





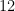

![x[n]](https://s0.wp.com/latex.php?latex=x%5Bn%5D&bg=ffffff&fg=000&s=0&c=20201002)



![X[z]](https://s0.wp.com/latex.php?latex=X%5Bz%5D&bg=ffffff&fg=000&s=0&c=20201002)