Keyfocus: Fading channel models for simulation. Learn how fading channels can be modeled as FIR filters for simplified modulation & detection. Rayleigh/Rician fading.
Introduction
A fading channel is a wireless communication channel in which the quality of the signal fluctuates over time due to changes in the transmission environment. These changes can be caused by different factors such as distance, obstacles, and interference, resulting in attenuation and phase shifting. The signal fluctuations can cause errors or loss of information during transmission.
Fading channels are categorized into slow fading and fast fading depending on the rate of channel variation. Slow fading occurs over long periods, while fast fading happens rapidly over short periods, typically due to multipath interference.
To overcome the negative effects of fading, various techniques are used, including diversity techniques, equalization, and channel coding.
Fading channel in frequency domain
With respect to the frequency domain characteristics, the fading channels can be classified into frequency selective and frequency-flat fading.
A frequency flat fading channel is a wireless communication channel where the attenuation and phase shift of the signal are constant across the entire frequency band. This means that the signal experiences the same amount of fading at all frequencies, and there is no frequency-dependent distortion of the signal.
In contrast, a frequency selective fading channel is a wireless communication channel where the attenuation and phase shift of the signal vary with frequency. This means that the signal experiences different levels of fading at different frequencies, resulting in a frequency-dependent distortion of the signal.
Frequency selective fading can occur due to various factors such as multipath interference and the presence of objects that scatter or absorb certain frequencies more than others. To mitigate the effects of frequency selective fading, various techniques can be used, such as equalization and frequency hopping.
The channel fading can be modeled with different statistics like Rayleigh, Rician, Nakagami fading. The fading channel models, in this section, are utilized for obtaining the simulated performance of various modulations over Rayleigh flat fading and Rician flat fading channels. Modeling of frequency selective fading channel is discussed in this article.
Linear time invariant channel model and FIR filters
The most significant feature of a real world channel is that the channel does not immediately respond to the input. Physically, this indicates some sort of inertia built into the channel/medium, that takes some time to respond. As a consequence, it may introduce distortion effects like inter-symbol interference (ISI) at the channel output. Such effects are best studied with the linear time invariant (LTI) channel model, given in Figure 1.


In this model, the channel response to any input depends only on the channel impulse response(CIR) function of the channel. The CIR is usually defined for finite length \(L\) as \(\mathbf{h}=[h_0,h_1,h_2, \cdots,h_{L-1}]\) where \(h_0\) is the CIR at symbol sampling instant \(0T_{sym}\) and \(h_{L-1}\) is the CIR at symbol sampling instant \((L-1)T_{sym}\). Such a channel can be modeled as a tapped delay line (TDL) filter, otherwise called finite impulse response (FIR) filter. Here, we only consider the CIR at symbol sampling instances. It is well known that the output of such a channel (\(\mathbf{r}\)) is given as the linear convolution of the input symbols (\(\mathbf{s}\)) and the CIR (\(\mathbf{h}\)) at symbol sampling instances. In addition, channel noise in the form of AWGN can also be included the model. Therefore, the resulting vector of from the entire channel model is given as
This article is part of the following books |
Simulation model for detection in flat fading channel
A flat-fading (also called as frequency-non-selective) channel is modeled with a single tap (\(L=1\)) FIR filter with the tap weights drawn from distributions like Rayleigh, Rician or Nakagami distributions. We will assume block fading, which implies that the fading process is approximately constant for a given transmission interval. For block fading, the random tap coefficient \(h=h[0]\) is a complex random variable (not random processes) and for each channel realization, a new set of complex random values are drawn from Rayleigh or Rician or Nakagami fading according to the type of fading desired.


Simulation models for modulation and detection over a fading channel is shown in Figure 2. For a flat fading channel, the output of the channel can be expressed simply as the product of time varying channel response and the input signal. Thus, equation (1) can be simplified (refer this article for derivation) as follows for the flat fading channel.
Since the channel and noise are modeled as a complex vectors, the detection of \(\mathbf{s}\) from the received signal is an estimation problem in the complex vector space.

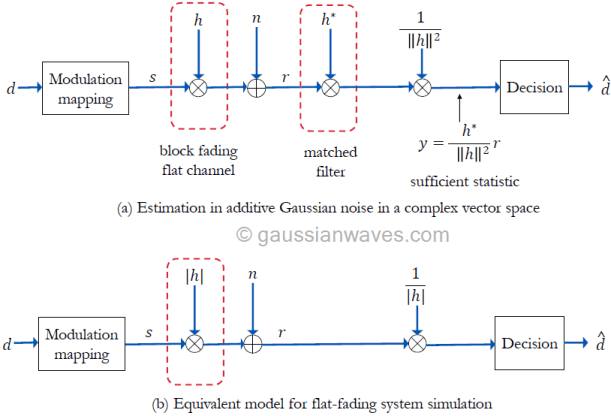
Assuming perfect channel knowledge at the receiver and coherent detection, the receiver shown in Figure 3(a) performs matched filtering. The impulse response of the matched filter is matched to the impulse response of the flat-fading channel as \( h^{\ast}\). The output of the matched filter is scaled down by a factor of \(||h||^2\) which is the total-energy contained in the impulse response of the flat-fading channel. The resulting decision vector \(\mathbf{y}\) serves as the sufficient statistic for the estimation of \(\mathbf{s}\) from the received signal \(\mathbf{r}\) (refer equation A.77 in reference [1])
Since the absolute value \(|h|\) and the Eucliden norm \(||h||\) are related as \(|h|^2= \left\lVert h\right\rVert = hh^{\ast}\), the model can be simplified further as given in Figure 3(b).
To simulate flat fading, the values for the fading variable \(h\) are drawn from complex normal distribution
where, \(X,Y\) are statistically independent real valued normal random variables.
● If \(E[h]=0\), then \(|h|\) is Rayleigh distributed, resulting in a Rayleigh flat fading channel
● If \(E[h] \neq 0\), then \(|h|\) is Rician distributed, resulting in a Rician flat fading channel with the factor \(K=[E[h]]^2/\sigma^2_h\)
References
[1] D. Tse and P. Viswanath, Fundamentals of Wireless Communication, Cambridge University Press, 2005.↗
Books by the author
 Wireless Communication Systems in Matlab Second Edition(PDF) Note: There is a rating embedded within this post, please visit this post to rate it. |  Digital Modulations using Python (PDF ebook) Note: There is a rating embedded within this post, please visit this post to rate it. |  Digital Modulations using Matlab (PDF ebook) Note: There is a rating embedded within this post, please visit this post to rate it. |
| Hand-picked Best books on Communication Engineering Best books on Signal Processing |
||



































































![E\left[X \right] = \int_{-\infty }^{\infty}xf_X(x)dx](https://s0.wp.com/latex.php?latex=E%5Cleft%5BX+%5Cright%5D+%3D+%5Cint_%7B-%5Cinfty+%7D%5E%7B%5Cinfty%7Dxf_X%28x%29dx+&bg=ffffff&fg=000&s=1&c=20201002)

![E\left[X \right] = \mu{_X} = \sum_{-\infty }^{\infty}x_{i}p_{i}](https://s0.wp.com/latex.php?latex=E%5Cleft%5BX+%5Cright%5D+%3D+%5Cmu%7B_X%7D+%3D+%5Csum_%7B-%5Cinfty+%7D%5E%7B%5Cinfty%7Dx_%7Bi%7Dp_%7Bi%7D+&bg=ffffff&fg=000&s=1&c=20201002)

![var \left[X\right] = \int_{-\infty }^{\infty} \left(x - E\left[X \right] \right)^2 f_X(x) dx](https://s0.wp.com/latex.php?latex=var+%5Cleft%5BX%5Cright%5D+%3D+%5Cint_%7B-%5Cinfty+%7D%5E%7B%5Cinfty%7D+%5Cleft%28x+-+E%5Cleft%5BX+%5Cright%5D+%5Cright%29%5E2+f_X%28x%29+dx+&bg=ffffff&fg=000&s=1&c=20201002)

![var \left[X\right] = {\sigma^2}_X = \sum_{-\infty }^{\infty} \left( x_i - \mu_X\right)^2 p_{i}](https://s0.wp.com/latex.php?latex=var+%5Cleft%5BX%5Cright%5D+%3D+%7B%5Csigma%5E2%7D_X+%3D+%5Csum_%7B-%5Cinfty+%7D%5E%7B%5Cinfty%7D+%5Cleft%28+x_i+-+%5Cmu_X%5Cright%29%5E2+p_%7Bi%7D+&bg=ffffff&fg=000&s=1&c=20201002)





![E\left[cX\right] = c E\left[X\right]](https://s0.wp.com/latex.php?latex=E%5Cleft%5BcX%5Cright%5D+%3D+c+E%5Cleft%5BX%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)

![E\left[X+c\right] = E\left[X\right]+c](https://s0.wp.com/latex.php?latex=E%5Cleft%5BX%2Bc%5Cright%5D+%3D+E%5Cleft%5BX%5Cright%5D%2Bc+&bg=ffffff&fg=000&s=1&c=20201002)

![E\left[c\right] = c](https://s0.wp.com/latex.php?latex=E%5Cleft%5Bc%5Cright%5D+%3D+c+&bg=ffffff&fg=000&s=1&c=20201002)

![var\left[cX\right] = c^2 var\left[X\right]](https://s0.wp.com/latex.php?latex=var%5Cleft%5BcX%5Cright%5D+%3D+c%5E2+var%5Cleft%5BX%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)

![var\left[X+c\right] = var\left[X\right]](https://s0.wp.com/latex.php?latex=var%5Cleft%5BX%2Bc%5Cright%5D+%3D+var%5Cleft%5BX%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)

![var\left[c\right] = 0](https://s0.wp.com/latex.php?latex=var%5Cleft%5Bc%5Cright%5D+%3D+0+&bg=ffffff&fg=000&s=1&c=20201002)











