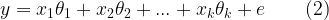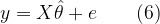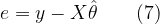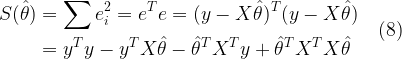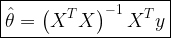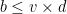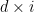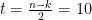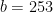Key focus: With examples, let’s estimate and plot the probability density function of a random variable using Matlab histogram function.
Generation of random variables with required probability distribution characteristic is of paramount importance in simulating a communication system. Let’s see how we can generate a simple random variable, estimate and plot the probability density function (PDF) from the generated data and then match it with the intended theoretical PDF. Normal random variable is considered here for illustration. Other types of random variables like uniform, Bernoulli, binomial, Chi-squared, Nakagami-m are illustrated in the next section.
Note: If you are inclined towards programming in Python, visit this article
Step 1: Create the random variable
A survey of commonly used fundamental methods to generate a given random variable is given in [1]. For this demonstration, we will consider the normal random variable with the following parameters :



This article is part of the book |
● Method 1: Using the in-built random function (requires statistics toolbox)
mu=0;sigma=1;%mean=0,deviation=1
L=100000; %length of the random vector
R = random('Normal',mu,sigma,L,1);%method 1
● Method 2: Using randn function that generates normally distributed random numbers having

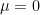

mu=0;sigma=1;%mean=0,deviation=1 L=100000; %length of the random vector R = randn(L,1)*sigma + mu; %method 2
● Method 3: Box-Muller transformation [2] method using rand function that generates uniformly distributed random numbers
mu=0;sigma=1;%mean=0,deviation=1 L=100000; %length of the random vector U1 = rand(L,1); %uniformly distributed random numbers U(0,1) U2 = rand(L,1); %uniformly distributed random numbers U(0,1) Z = sqrt(-2log(U1)).cos(2piU2);%Standard Normal distribution R = Z*sigma+mu;%Normal distribution with mean and sigma
Step 2: Plot the estimated histogram
Typically, if we have a vector of random numbers that is drawn from a distribution, we can estimate the PDF using the histogram tool. Matlab supports two in-built functions to compute and plot histograms:
● hist – introduced before R2006a
● histogram – introduced in R2014b
Which one to use ? Matlab’s help page points that the hist function is not recommended for several reasons and the issue of inconsistency is one among them. The histogram function is the recommended function to use.
Estimate and plot the normalized histogram using the recommended ‘histogram’ function. And for verification, overlay the theoretical PDF for the intended distribution. When using the histogram function to plot the estimated PDF from the generated random data, use ‘pdf’ option for ‘Normalization’ option. Do not use the ‘probability’ option for ‘Normalization’ option, as it will not match the theoretical PDF curve.
histogram(R,'Normalization','pdf'); %plot estimated pdf from the generated data
X = -4:0.1:4; %range of x to compute the theoretical pdf
fx_theory = pdf('Normal',X,mu,sigma); %theoretical normal probability density
hold on; plot(X,fx_theory,'r'); %plot computed theoretical PDF
title('Probability Density Function'); xlabel('values - x'); ylabel('pdf - f(x)'); axis tight;
legend('simulated','theory');


However, if you do not have Matlab version that was released before R2014b, use the ‘hist’ function and get the histogram frequency counts (




%For those who don't have access to 'histogram' function
%get un-normalized values from hist function with same number of bins as histogram function
numBins=50; %choose appropriately
[f,x]=hist(R,numBins); %use hist function and get unnormalized values
figure; plot(x,f/trapz(x,f),'b-*');%plot normalized histogram from the generated data
X = -4:0.1:4; %range of x to compute the theoretical pdf
fx_theory = pdf('Normal',X,mu,sigma); %theoretical normal probability density
hold on; plot(X,fx_theory,'r'); %plot computed theoretical PDF
title('Probability Density Function'); xlabel('values - x'); ylabel('pdf - f(x)'); axis tight;
legend('simulated','theory');


Step 3: Theoretical PDF:
The given code snippets above, already include the command to plot the theoretical PDF by using the ‘pdf’ function in Matlab. It you do not have access to this function, you could use the following equation for computing the theoretical PDF

![f_X(x) = \frac{1}{ \sqrt{ 2 \pi \sigma^2 }} exp \left[ -\frac{ \left( x-\mu \right) ^2}{2 \sigma^2} \right]](https://s0.wp.com/latex.php?latex=f_X%28x%29+%3D+%5Cfrac%7B1%7D%7B+%5Csqrt%7B+2+%5Cpi+%5Csigma%5E2+%7D%7D+exp+%5Cleft%5B+-%5Cfrac%7B+%5Cleft%28+x-%5Cmu+%5Cright%29+%5E2%7D%7B2+%5Csigma%5E2%7D+%5Cright%5D+&bg=ffffff&fg=000&s=2&c=20201002)
The code snippet for that purpose is given next.
X = -4:0.1:4; %range of x to compute the theoretical pdf fx_theory = 1/sqrt(2*pi*sigma^2)*exp(-0.5*(X-mu).^2./sigma^2); plot(X,fx_theory,'k'); %plot computed theoretical PDF
Note: The functions – ‘random’ and ‘pdf’ , requires statistics toolbox.
Rate this article: Note: There is a rating embedded within this post, please visit this post to rate it.
References:
[1] John Mount, ‘Six Fundamental Methods to Generate a Random Variable’, January 20, 2012.↗
[2] Thomas, D. B., Luk. W., Leong, P. H. W., and Villasenor, J. D. 2007. Gaussian random number generators. ACM Comput. Surv. 39, 4, Article 11 (October 2007), 38 pages DOI = 10.1145/1287620.1287622 http://doi.acm.org/10.1145/1287620.1287622.↗
Topics in this chapter
| Random Variables - Simulating Probabilistic Systems ● Introduction ● Plotting the estimated PDF ● Univariate random variables □ Uniform random variable □ Bernoulli random variable □ Binomial random variable □ Exponential random variable □ Poisson process □ Gaussian random variable □ Chi-squared random variable □ Non-central Chi-Squared random variable □ Chi distributed random variable □ Rayleigh random variable □ Ricean random variable □ Nakagami-m distributed random variable ● Central limit theorem - a demonstration ● Generating correlated random variables □ Generating two sequences of correlated random variables □ Generating multiple sequences of correlated random variables using Cholesky decomposition ● Generating correlated Gaussian sequences □ Spectral factorization method □ Auto-Regressive (AR) model |
Books by the author
 Wireless Communication Systems in Matlab Second Edition(PDF) Note: There is a rating embedded within this post, please visit this post to rate it. |  Digital Modulations using Python (PDF ebook) Note: There is a rating embedded within this post, please visit this post to rate it. |  Digital Modulations using Matlab (PDF ebook) Note: There is a rating embedded within this post, please visit this post to rate it. |
| Hand-picked Best books on Communication Engineering Best books on Signal Processing |
||