Cholesky decomposition is an efficient method for inversion of symmetric positive-definite matrices. Let’s demonstrate the method in Python and Matlab.
Cholesky factor
Any $n \times n$ symmetric positive definite matrix $A $ can be factored as
$$A=LL^T $$
where $L$ is $n \times n$ lower triangular matrix. The lower triangular matrix $L$ is often called “Cholesky Factor of $A$”. The matrix $L$ can be interpreted as square root of the positive definite matrix $A$.
Basic Algorithm to find Cholesky Factorization:
Note: In the following text, the variables represented in Greek letters represent scalar values, the variables represented in small Latin letters are column vectors and the variables represented in capital Latin letters are Matrices.
Given a positive definite matrix $latex A$, it is partitioned as follows.
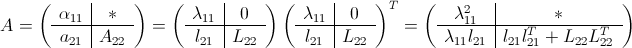
$\alpha_{11}, \lambda_{11} = $ first element of $A$ and $L$ respectively
$a_{21} , l_{21} =$ column vector at first column starting from second row of $A$ and $L$ respectively
$A_{22} , L_{22} =$ remaining lower part of the matrix of $A$ and $L$ respectively of size $latex (n-1) \times (n-1)$
Having partitioned the matrix $A$ as shown above, the Cholesky factorization can be computed by the following iterative procedure.
Steps in computing the Cholesky factorization:
Step 1: Compute the scalar: $\lambda_{11}=\sqrt{\alpha_{11}}$
Step 2: Compute the column vector: $l_{21}= a_{21}/\lambda_{11}$
Step 3: Compute the matrix : $A_{22}=l_{21} l^T_{21}+L_{22}L^T_{22}$
Step 4: Replace $A$ with $A_{22}$, i.e, $A=A_{22}$
Step 5: Repeat from step 1 till the matrix size at Step 4 becomes $1 \times 1$.
Matlab Program (implementing the above algorithm):
Function 1: [F]=cholesky(A,option)
function [F]=cholesky(A,option)
%Function to find the Cholesky factor of a Positive Definite matrix A
%Author Mathuranathan for https://www.gaussianwaves.com/
%Licensed under Creative Commons: CC-NC-BY-SA 3.0
%A = positive definite matrix
%Option can be one of the following 'Lower','Upper'
%L = Cholesky factorizaton of A such that A=LL^T
%If option ='Lower', then it returns the Cholesky factored matrix L in
%lower triangular form
%If option ='Upper', then it returns the Cholesky factored matrix L in
%upper triangular form
%Test for positive definiteness (symmetricity need to satisfy)
%Check if the matrix is symmetric
if ~isequal(A,A'),
error('Input Matrix is not Symmetric');
end
if isPositiveDefinite(A),
[m,n]=size(A);
L=zeros(m,m);%Initialize to all zeros
row=1;col=1;
j=1;
for i=1:m,
a11=sqrt(A(1,1));
L(row,col)=a11;
if(m~=1), %Reached the last partition
L21=A(j+1:m,1)/a11;
L(row+1:end,col)=L21;
A=(A(j+1:m,j+1:m)-L21*L21');
[m,n]=size(A);
row=row+1;
col=col+1;
end
end
switch nargin
case 2
if strcmpi(option,'upper'),F=L';
else
if strcmpi(option,'lower'),F=L;
else error('Invalid option');
end
end
case 1
F=L;
otherwise
error('Not enough input arguments')
end
else
error('Given Matrix A is NOT Positive definite');
end
end
Function 2: x=isPositiveDefinite(A)
function x=isPositiveDefinite(A)
%Function to check whether a given matrix A is positive definite
%Author Mathuranathan for https://www.gaussianwaves.com/
%Licensed under Creative Commons: CC-NC-BY-SA 3.0
%Returns x=1, if the input matrix is positive definite
%Returns x=0, if the input matrix is not positive definite
[m,~]=size(A);
%Test for positive definiteness
x=1; %Flag to check for positiveness
for i=1:m
subA=A(1:i,1:i); %Extract upper left kxk submatrix
if(det(subA)<=0); %Check if the determinent of the kxk submatrix is +ve
x=0;
break;
end
end
%For debug
%if x, display('Given Matrix is Positive definite');
%else display('Given Matrix is NOT positive definite'); end
end
Sample Run:
A is a randomly generated positive definite matrix. To generate a random positive definite matrix check the link in “external link” section below.
>> A=[3.3821 ,0.8784,0.3613,-2.0349; 0.8784, 2.0068, 0.5587, 0.1169; 0.3613, 0.5587, 3.6656, 0.7807; -2.0349, 0.1169, 0.7807, 2.5397];
$$A=\begin{bmatrix} 3.3821 & 0.8784 & 0.3613 & -2.0349 \\ 0.8784 & 2.0068 & 0.5587 & 0.1169 \\ 0.3613 & 0.5587 & 3.6656 & 0.7807 \\ -2.0349 & 0.1169 & 0.7807 & 2.5397 \end{bmatrix}$$
>> cholesky(A,’Lower’)
$$ans=\begin{bmatrix} 1.8391 & 0 & 0 & 0 \\ 0.4776 & 1.3337 & 0 & 0 \\ 0.1964 & 0.3486 & 1.8723 & 0 \\ -1.1065 & 0.4839 & 0.4430 & 0.9408 \end{bmatrix} $$
>> cholesky(A,’upper’)
$$ans=\begin{bmatrix} 1.8391 & 0.4776 & 0.1964 & -1.1065\\ 0 & 1.3337 & 0.3486 & 0.4839\\ 0 & 0 & 1.8723 & 0.4430\\ 0 & 0 & 0 & 0.9408 \end{bmatrix}$$
Python code
Let us verify the above results using Python’s Numpy package. The numpy package numpy.linalg contains the cholesky function for computing the Cholesky decomposition (returns \(L\) in lower triangular matrix form). It can be summoned as follows
import numpy as np
A=[[3.3821 ,0.8784,0.3613,-2.0349],\
[0.8784, 2.0068, 0.5587, 0.1169],\
[0.3613, 0.5587, 3.6656, 0.7807],\
[-2.0349, 0.1169, 0.7807, 2.5397]]
A_cholesky = np.linalg.cholesky(A)