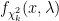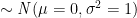Key focus: Bayes’ theorem is a method for revising the prior probability for specific event, taking into account the evidence available about the event.
Introduction
In statistics, the process of drawing conclusions from data subject to random variations – is called “statistical inference”. Usually, in any random experiment, the observations are recorded and conclusions have to be drawn based on the recorded data set. Conclusions over the underlying random process are necessary to establish one or many of the following:
* Estimation of a parameter of interest (For example: the carrier frequency estimation in the receiver)
* Confidence and credibility of the estimate
* Rejecting a preconceived hypothesis
* Classification of data set into groups
Several schools of statistical inference have evolved over time. Bayesian inference is one of them.
Bayes’ theorem
Bayes’ theorem is central to scientific discovery and a core tool in machine learning/AI. It has numerous applications including but not limited to areas such as: mathematics, medicine, finance, marketing and engineering.
The Bayes’ theorem is used in Bayesian inference, usually dealing with a sequence of events, as new information becomes available about a subsequent event, that new information is used to update the probability of the initial event. In this context, we encounter two flavors of probabilities: prior probability and posterior probability.
Prior probability : This is the initial probability about an event before any information is available about the event. In other words, this is the initial belief about a particular hypothesis before any evidence is available about the hypothesis.
Posterior probability: This is the probability value that has been revised by using new information that is later obtained from a subsequent event. In other words, this is the updated belief about the hypothesis as new evident becomes available.
The formula for Bayes’ theorem is


A very simple thought experiment
You are asked to conduct a random experiment with a given coin. You are told that the coin is unbiased (probability of obtaining head or tail is equal and is exactly 50%). You believe (before conducting the experiment) that the coin is unbiased and that the chance of getting head or tail is equal to be 0.5.
Assume that you have not looked at both sides of the coin and simply you start to conduct the experiment. You start to toss the coin repeatedly and record the events (This is the observed new information/evidences). On the first toss you observe the coin lands on the ground with head faced up. On the second toss, again the head shows up. On subsequent tosses, the coin always shows up head. You have tossed 100 times and all these tosses you observe only head. Now what will you think about the coin? You will really start to think that both sides of the coin are engraved with “head” (no tail etched on the coin). Now, based on the new evidences, your belief about the “unbiasedness” of the coin is altered.
This is what Bayes’ theorem or Bayesian inference is all about. It is a general principle about learning from experience. It connects beliefs (called prior probabilities) and evidences (observed data). Based on the evidence, the degree of belief is refined. The degree of belief after conducting the experiment is called posterior probability.


Real world example
Suppose, a person X falls sick and goes to the doctor for diagnosis. The doctor runs a series of tests and the test result came positive for a rare disease that affects 0.1% of the population. The accuracy of the test is 99%. That is, the test can correctly identify 99% of people that have the disease and will incorrectly report disease in only 1% of the people that do not have the disease. Now, how certain is that the person X actually have the disease ?
In this scenario, we can apply the extended form of Bayes’ theorem


Extended form of Bayes’ theorem is applied in special scenarios where P(H) is a binary variable, which implies it can take only two possible states. In the given problem above, the hypothesis can take only two states – H – “having the disease” and H̅ – “not having the disease”.
For the given problem, we can come up with the following numbers for the various quantities in the extended form of Bayes’ theorem.
P(H) = prior probability of having the disease before the availability of test results. This is often guess work, but luckily we have the probability that affects the population (0.1% = 0.001) to replace this.
P(E/H) = probability to test positive for the disease if person X has the disease (99% = 0.99)
P(H̅) = probability of NOT having the disease (1-0.001 = 0.999)
P(E/H̅) = probability of NOT having the disease and falsely identified positive by the test (1% = 0.01).
P(H/E) = probability of person X actually have the disease given the test result is positive.
Plugging-in these numbers in the extended form of Bayes’ theorem, we get the probability that X actually have the disease is just 9%.


Person X doubts the result and goes for a second opinion to another doctor and gets tested from an independent laboratory. The second test result came back positive this time too. Now what is the probability that person X actually have the disease ?
P(H) = Replace this with the posterior probability from first test (we are refining the belief about the result of the first test) = 9.016% = 0.09016
P(E/H) = probability to test positive for the disease if person X has the disease (99% = 0.99)
P(H̅) = probability of NOT having the disease from first test (1-0.09016 = 0.90984)
P(E/H̅) = probability of NOT having the disease and falsely identified positive by the second test (1% = 0.01).
P(H/E) = probability of person X actually have the disease given the second test result is also positive.


Therefore, the updated probability based on two positive tests is 90.75%. This implies that there is a 90.75% chance that person X has the disease.
I hope the reader got a better understanding of what Bayes’ theorem is, various parameters in the equation for Bayes’ theorem and how to apply it.
Rate this article: Note: There is a rating embedded within this post, please visit this post to rate it.
References
[1] Jeremy Orloff and Jonathan Bloom, “Conditional Probability, Independence and Bayes’ Theorem”, MIT OCW, Class 3, 18.05 Introduction to Probability and Statistics ↗.
[2] Veritasium, “The Bayesian Trap”, YouTube
Books by the author
 Wireless Communication Systems in Matlab Second Edition(PDF) Note: There is a rating embedded within this post, please visit this post to rate it. |  Digital Modulations using Python (PDF ebook) Note: There is a rating embedded within this post, please visit this post to rate it. |  Digital Modulations using Matlab (PDF ebook) Note: There is a rating embedded within this post, please visit this post to rate it. |
| Hand-picked Best books on Communication Engineering Best books on Signal Processing |
||














































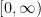



























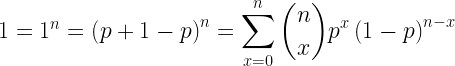

![\mu = E[X] = np](https://s0.wp.com/latex.php?latex=%5Cmu+%3D+E%5BX%5D+%3D+np+&bg=ffffff&fg=000&s=2&c=20201002)

![\sigma^2 = E\left[ \left(X - \mu \right)^2 \right] = np (1-p)](https://s0.wp.com/latex.php?latex=%5Csigma%5E2+%3D+E%5Cleft%5B+%5Cleft%28X+-+%5Cmu+%5Cright%29%5E2+%5Cright%5D+%3D+np+%281-p%29+&bg=ffffff&fg=000&s=2&c=20201002)



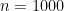




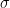

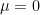








![f_X(x) = \frac{1}{ \sqrt{ 2 \pi \sigma^2 }} exp \left[ -\frac{ \left( x-\mu \right) ^2}{2 \sigma^2} \right]](https://s0.wp.com/latex.php?latex=f_X%28x%29+%3D+%5Cfrac%7B1%7D%7B+%5Csqrt%7B+2+%5Cpi+%5Csigma%5E2+%7D%7D+exp+%5Cleft%5B+-%5Cfrac%7B+%5Cleft%28+x-%5Cmu+%5Cright%29+%5E2%7D%7B2+%5Csigma%5E2%7D+%5Cright%5D+&bg=ffffff&fg=000&s=2&c=20201002)