A generic complex baseband simulation technique, to simulate all M-ary QAM modulation techniques is given here. The given simulation code is very generic, and it plots both simulated and theoretical symbol error rates for all M-QAM modulation techniques.
Rectangular QAM from PAM constellation
There exist other constellation shapes (like circular, triangular constellations) that are more efficient (in terms of energy required to achieve same the error probability) than the standard rectangular constellation. Rectangular (symmetric or square) constellations are the preferred choice of implementation due to its simplicity in implementing modulation and demodulation.
In one of the earlier articles, I have discussed the method of constructing constellation for rectangular QAM modulation using Karnaugh-map walks, where the inherent property of Karnaugh-maps is exploited to construct Gray coded QAM symbols.
Any rectangular QAM constellation is equivalent to superimposing two Amplitude Shift Keying (ASK) signals (also called Pulse Amplitude Modulation – PAM) on quadrature carriers. For example, 16-QAM constellation points can be generated from two 4-PAM signals, similarly the 64-QAM constellation points can be generated from two 8-PAM signals.


The generic equation to generate PAM signals of dimension D is


For generating 16-QAM, the dimension D of PAM is set to

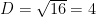

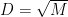
Matlab code
function [s,ref]=mqam_modulator(M,d)
%Function to MQAM modulate the vector of data symbols - d
%[s,ref]=mqam_modulator(M,d) modulates the symbols defined by the vector d
% using MQAM modulation, where M specifies order of M-QAM modulation and
% vector d contains symbols whose values range 1:M. The output s is modulated
% output and ref represents reference constellation that can be used in demod
if(((M˜=1) && ˜mod(floor(log2(M)),2))==0), %M not a even power of 2
error('Only Square MQAM supported. M must be even power of 2');
end
ref=constructQAM(M); %construct reference constellation
s=ref(d); %map information symbols to modulated symbols
endPython code
Full Matlab code available in the book Digital Modulations using Python
class QAMModem(Modem):
# Derived class: QAMModem
def __init__(self,M):
if (M==1) or (np.mod(np.log2(M),2)!=0): # M not a even power of 2
raise ValueError('Only square MQAM supported. M must be even power of 2')
n = np.arange(0,M) # Sequential address from 0 to M-1 (1xM dimension)
a = np.asarray([xˆ(x>>1) for x in n]) #convert linear addresses to Gray code
D = np.sqrt(M).astype(int) #Dimension of K-Map - N x N matrix
a = np.reshape(a,(D,D)) # NxN gray coded matrix
oddRows=np.arange(start = 1, stop = D ,step=2) # identify alternate rows
nGray=np.reshape(a,(M)) # reshape to 1xM - Gray code walk on KMap
#Construction of ideal M-QAM constellation from sqrt(M)-PAM
(x,y)=np.divmod(nGray,D) #element-wise quotient and remainder
Ax=2*x+1-D # PAM Amplitudes 2d+1-D - real axis
Ay=2*y+1-D # PAM Amplitudes 2d+1-D - imag axis
constellation = Ax+1j*Ay
Modem.__init__(self, M, constellation, name='QAM') #set the modem attributesThis article is part of the following books |
M-QAM demodulation (coherent detection)
Generally the two main categories of detection techniques, commonly applied for detecting the digitally modulated data are coherent detection and non-coherent detection.
In the vector simulation model for the coherent detection, the transmitter and receiver agree on the same
reference constellation for modulating and demodulating the information. The modulators generate the reference constellation for the selected modulation type. The same reference constellation should be used if coherent detection is selected as the method of demodulating the received data vector.
On the other hand, in the non-coherent detection, the receiver is oblivious to the reference constellation used at the transmitter. The receiver uses methods like envelope detection to demodulate the data.
The IQ detection technique is an example of coherent detection. In the IQ detection technique, the first step is to compute the pair-wise Euclidean distance between the given two vectors – reference array and the received symbols corrupted with noise. Each symbol in the received symbol vector (represented on a p-dimensional plane) should be compared with every symbol in the reference array. Next, the symbols, from the reference array, that provide the minimum Euclidean distance are returned.
Let x=(x1,x2,…,xp) and y=(y1,y2,…,yp) be two points in p-dimensional space. The Euclidean distance between them is given by


The pair-wise Euclidean distance between two sets of vectors, say x and y, on a p-dimensional space, can be computed using the vectorized code. The vectorized code returns the ideal signaling points from matrix y that provides the minimum Euclidean distance. Since the vectorized implementation is devoid of nested for-loops, the program executes significantly faster for larger input matrices. The given code is very generic in the sense that it can be easily reused to implement optimum coherent receivers for any N-dimensional digital modulation technique (Please refer the books Digital Modulations using Matlab and Digital Modulations using Python for complete simulation code) .
Matlab code
Full Matlab code available in the book Digital Modulations using Matlab
function [dCap]= mqam_detector(M,r)
%Function to detect MQAM modulated symbols
%[dCap]= mqam_detector(M,r) detects the received MQAM signal points
%points - 'r'. M is the modulation level of MQAM
if(((M˜=1) && ˜mod(floor(log2(M)),2))==0), %M not a even power of 2
error('Only Square MQAM supported. M must be even power of 2');
end
ref=constructQAM(M); %reference constellation for MQAM
[˜,dCap]= iqOptDetector(r,ref); %IQ detection
endPython code
Full Matlab code available in the book Digital Modulations using Python
Performance simulation results
The simulation results for error rate performance of M-QAM modulations over AWGN channel and Rician flat-fading channel is given in the following figures.




Rate this article: Note: There is a rating embedded within this post, please visit this post to rate it.
Reference
[1] John G. Proakis, “Digital Communciations”, McGraw-Hill; 5th edition.↗
Related Topics
| Digital Modulators and Demodulators - Complex Baseband Equivalent Models ● Introduction ● Complex baseband representation of modulated signal ● Complex baseband representation of channel response ● Modulators for amplitude and phase modulations □ Pulse Amplitude Modulation (M-PAM) □ Phase Shift Keying Modulation (M-PSK) □ Quadrature Amplitude Modulation (M-QAM) ● Demodulators for amplitude and phase modulations □ M-PAM detection □ M-PSK detection □ M-QAM detection □ Optimum detector on IQ plane using minimum Euclidean distance ● M-ary FSK modulation and detection □ Modulator for M orthogonal signals □ M-FSK detection |
Books by the author
 Wireless Communication Systems in Matlab Second Edition(PDF) Note: There is a rating embedded within this post, please visit this post to rate it. |  Digital Modulations using Python (PDF ebook) Note: There is a rating embedded within this post, please visit this post to rate it. |  Digital Modulations using Matlab (PDF ebook) Note: There is a rating embedded within this post, please visit this post to rate it. |
| Hand-picked Best books on Communication Engineering Best books on Signal Processing |
||























































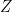



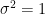










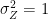















![\mu = E\left[\chi_k^2\right] = k](https://s0.wp.com/latex.php?latex=%5Cmu+%3D+E%5Cleft%5B%5Cchi_k%5E2%5Cright%5D+%3D+k+&bg=ffffff&fg=000&s=2&c=20201002)

![\sigma^2 = var\left[\chi_k^2\right] = 2k](https://s0.wp.com/latex.php?latex=%5Csigma%5E2+%3D+var%5Cleft%5B%5Cchi_k%5E2%5Cright%5D+%3D+2k+&bg=ffffff&fg=000&s=2&c=20201002)





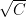





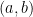

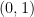




















![\sigma^{2}_{\hat{f}_0}= E \left\{ ( \hat{f}_0 - E [ \hat{f}_0 ] )^2 \right\}](https://s0.wp.com/latex.php?latex=%5Csigma%5E%7B2%7D_%7B%5Chat%7Bf%7D_0%7D%3D+E+%5Cleft%5C%7B+%28+%5Chat%7Bf%7D_0+-+E+%5B+%5Chat%7Bf%7D_0+%5D+%29%5E2+%5Cright%5C%7D+&bg=ffffff&fg=000&s=1&c=20201002)



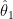


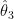










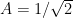




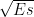

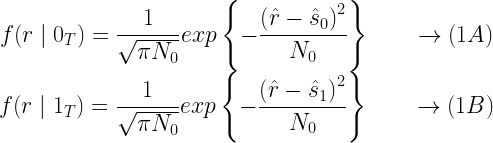

























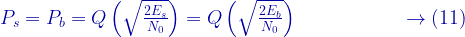










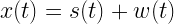

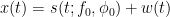

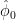

![x[n] = s[n;f_0, \phi_0] + w[n]](https://s0.wp.com/latex.php?latex=x%5Bn%5D+%3D+s%5Bn%3Bf_0%2C+%5Cphi_0%5D+%2B+w%5Bn%5D+&bg=ffffff&fg=000&s=2&c=20201002)

![\hat{f}_{0}=g_{1}(x[0], x[1],x[2],\cdots,x[N-1])=g_{1} \left( \textbf{x} \right)](https://s0.wp.com/latex.php?latex=%5Chat%7Bf%7D_%7B0%7D%3Dg_%7B1%7D%28x%5B0%5D%2C+x%5B1%5D%2Cx%5B2%5D%2C%5Ccdots%2Cx%5BN-1%5D%29%3Dg_%7B1%7D+%5Cleft%28+%5Ctextbf%7Bx%7D+%5Cright%29+&bg=ffffff&fg=000&s=2&c=20201002)

![\hat{\phi}_{0} = g_{2} (x[0], x[1], x[2], \cdots, x[N-1]) = g_{2} \left( \textbf{x} \right)](https://s0.wp.com/latex.php?latex=%5Chat%7B%5Cphi%7D_%7B0%7D+%3D+g_%7B2%7D+%28x%5B0%5D%2C+x%5B1%5D%2C+x%5B2%5D%2C+%5Ccdots%2C+x%5BN-1%5D%29+%3D+g_%7B2%7D+%5Cleft%28+%5Ctextbf%7Bx%7D+%5Cright%29+&bg=ffffff&fg=000&s=2&c=20201002)


![\begin{aligned} E\left\{\hat{f}_0 \right\} &= f_0 \\ \sigma^{2}_{\hat{f}_0} &= E \left\{ \left( \hat{f}_0 - E [ \hat{f}_0] \right)^2 \right\} \quad \text{should be minimum} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+E%5Cleft%5C%7B%5Chat%7Bf%7D_0+%5Cright%5C%7D+%26%3D+f_0+%5C%5C+%5Csigma%5E%7B2%7D_%7B%5Chat%7Bf%7D_0%7D+%26%3D+E+%5Cleft%5C%7B+%5Cleft%28+%5Chat%7Bf%7D_0+-+E+%5B+%5Chat%7Bf%7D_0%5D+%5Cright%29%5E2+%5Cright%5C%7D+%5Cquad+%5Ctext%7Bshould+be+minimum%7D+%5Cend%7Baligned%7D+&bg=ffffff&fg=000&s=2&c=20201002)