Key focus: Can a unique solution exists when solving ARMA (Auto Regressive Moving Average) model ? Apply minimization of squared error to find out.
As discussed in the previous post, the ARMA model is a generalized model that is a mix of both AR and MA model. Given a signal x[n], AR model is easiest to find when compared to finding a suitable ARMA process model. Let’s see why this is so.
AR model error and minimization
In the AR model, the present output sample x[n] and the past N-1 output samples determine the source input w[n]. The difference equation that characterizes this model is given by
The model can be viewed from another perspective, where the input noise w[n] is viewed as an error – the difference between present output sample x[n] and the predicted sample of x[n] from the previous N-1 output samples. Let’s term this “AR model error“. Rearranging the difference equation,
The summation term inside the brackets are viewed as output sample predicted from past N-1 output samples and their difference being the error w[n].
Least squared estimate of the co-efficients – ak are found by evaluating the first derivative of the squared error with respect to ak and equating it to zero – finding the minima.From the equation above, w2[n] is the squared error that we wish to minimize. Here, w2[n] is a quadratic equation of unknown model parameters ak. Quadratic functions have unique minima, therefore it is easier to find the Least Squared Estimates of ak by minimizing w2[n].
ARMA model error and minimization
The difference equation that characterizes this model is given by
Re-arranging, the ARMA model error w[n] is given by
Now, the predictor (terms inside the brackets) considers weighted combinations of past values of both input and output samples.
The squared error, w2[n] is NOT a quadratic function and we have two sets of unknowns – ak and bk. Therefore, no unique solution may be available to minimize this squared error-since multiple minima pose a difficult numerical optimization problem.
Rate this article: Note: There is a rating embedded within this post, please visit this post to rate it.
Key focus: AR, MA & ARMA models express the nature of transfer function of LTI system. Understand the basic idea behind those models & know their frequency responses.
Introduction
Signal models are used to analyze stationary univariate time series. The goal of signal modeling is to estimate the process from which the desired signal is generated. Though the concept described here is related to the topic of “system identification”, they are quite different.
A signal model is an unique combination of a filter and a source input, that may fall into any of the following categories
Filter: state-space model, AR, MA, ARMA (see below)
Source:pulse, pulse train, white noise,…
Motivation
Let’s say we observe a real world signal x[n] that has a spectrum x[ɷ] (the spectrum can be arbitrary – bandpass, baseband etc..,). We would like to describe the long sequence of x[n] using very few parameters (application : Linear Predictive Coding (LPC) ). The modelling approach, described here, tries to answer the following two questions.
Is it possible to model the first order (mean/variance) and second order (correlations, spectrum) statistics of the signal just by shaping a white noise spectrum using a transfer function ? (see Figure 1)
Does this produce the same statistics (spectrum, correlations, mean and variance) for a white noise input ?
If the answer is “yes” to the above two questions, we can simply set the modeled parameters of the system and excite the system with white (flat) noise to produce the desired real world signal. This reduces the amount to data we wish to transmit in a communication system application.
Figure 1: Shaping a white noise spectrum (flat spectrum) to achieve desired spectrum
LTI system model
In the model given below, the random signal x[n] is observed. Given the observed signal x[n], the goal here is to find a model that best describes the spectral properties of x[n] under the following assumptions
● x[n] is WSS (Wide Sense Stationary) and ergodic. ● The input signal to the LTI system is white noise following Gaussian distribution – zero mean and variance σ2. ● The LTI system is BIBO (Bounded Input Bounded Output) stable.
Figure 2: Linear Time Invariant (LTI) system – signal model
In the model shown above, the input to the LTI system is a white noise following Gaussian distribution – zero mean and variance σ2. The power spectral density (PSD) of the noise w[n] is
The noise process drives the LTI system with frequency response H(ejɷ) producing the signal of interest x[n]. The PSD of the output process is therefore,
Three cases are possible given the nature of the transfer function of the LTI system that is under investigation here.
Moving Average (MA) models : H(ejɷ) is an all-zeros system
Auto Regressive Moving Average (ARMA) models : H(ejɷ) is a pole-zero system
Auto Regressive (AR) models (all-poles model)
In the AR model, the present output sample x[n] and the past N output samples determine the source input w[n]. The difference equation that characterizes this model is given by
Here, the LTI system is an Infinite Impulse Response (IIR) filter. This is evident from the fact that the above equation considered past samples of x[n] when determining w[n], there by creating a feedback loop from the output of the filter.
The frequency response of the IIR filter is well known
Figure 3: Spectrum of all-pole transfer function (representing AR model)
The transfer function H(ejɷ) is an all-pole transfer function (when the denominator is set to zero, the transfer function goes to infinity -> creating peaks in the spectrum). Poles are best suited to model resonant peaks in a given spectrum. At the peaks, the poles are closer to unit circle. This model is well suited for modeling peaky spectra.
In the MA model, the present output sample x[n] is determined by the present source input w[n] and past N samples of source input w[n]. The difference equation that characterizes this model is given by
Here, the LTI system is an Finite Impulse Response (FIR) filter. This is evident from the fact that the above equation that no feedback is involved from output to input.
The frequency response of the FIR filter is well known
The transfer function H(ejɷ) is an all-zero transfer function (when the numerator is set to zero, the transfer function goes to zero -> creating nulls in the spectrum). Zeros are best suited to model sharp nulls in a given spectrum.
Figure 4: Spectrum of all-zeros transfer function (representing MA model)
Auto Regressive Moving Average (ARMA) model (pole-zero model)
ARMA model is a generalized model that is a combination of AR and MA model. The output of the filter is linear combination of both weighted inputs (present and past samples) and weight outputs (present and past samples). The difference equation that characterizes this model is given by
The frequency response of this generalized filter is well known
The transfer function H(ejɷ) is a pole-zero transfer function. It is best suited for modelling complex spectra having well defined resonant peaks and nulls.
Key focus: Applying Cramér-Rao Lower Bound (CRLB) for vector parameter estimation. Know about covariance matrix, Fisher information matrix & CRLB matrix.
CRLB for Vector Parameter Estimation
CRLB for scalar parameter estimation was discussed in previous posts. The same concept is extended to vector parameter estimation.
Consider a set of deterministic parameters that we wish to estimate.
The estimate is denoted in vector form as, .
Assume that the estimate is unbiased .
Covariance Matrix
For the scalar parameter estimation, the variance of the estimate was considered. For vector parameter estimation, the covariance of the vector of estimates are considered.
The covariance matrix for the vector of estimates is given by
For example, if and C are the unknown parameters to be estimated, then the covariance matrix for the parameter vector is given by
Fisher Information Matrix
For the scalar parameter estimation, Fisher Information was considered. Same concept is extended for the vector case and is called the Fisher Information Matrix . The ijth element of the Fisher Information Matrix (evaluated at the true values of the parameter vector) is given by
CRLB Matrix
Under the same regularity condition (as that of the scalar parameter estimation case),
the CRLB Matrix is given by the inverse of the Fisher Information Matrix
Note: For the scale parameter estimation, the CRLB was shown to be the reciprocal of the Fisher Information.
This implies that the covariance of the parameters (diagonal elements) are bound by the CRLB as
More generally, the condition given above is represented as
Note: The word positive-semi-definite is the matrix equivalent of saying that a value is greater than or equal to zero. Similarly, the term positive-definite is roughly equivalent of saying that something is definitely greater than zero or definitely positive.
Emphasize was place on diagonal elements in the Fisher Information Matrix. The effect of off-diagonal elements should also be considered.
Disclaimer: All the materials posted in this section are collected from various sources. GaussianWaves cannot guarantee the accuracy of the content in these video lectures. For any queries/if you would like to add a video lecture of your choice, please use the feedback form.
Mathematical details of convolution, its relationship to polynomial multiplication and the application of Toeplitz matrices in computing linear convolution are discussed in the previous article. A short survey of different techniques to compute discrete linear convolution (with Matlab code) is given here.
Definition
Given an LTI (Linear Time Invariant) system with impulse response \(h[n]\) and an input sequence \(x[n]\), the output of the system \(y[n]\) is obtained by convolving the input sequence and impulse response.
The above equation can simply be implemented using nested for-loops, which consume the most computational time of all the methods given here. Typically, the computational complexity is \(O(n^2)\) time.
Python
def conv_brute_force(x,h):
"""
Brute force method to compute convolution
Parameters:
x, h : numpy vectors
Returns:
y : convolution of x and h
"""
N=len(x)
M=len(h)
y = np.zeros(N+M-1) #array filled with zeros
for i in np.arange(0,N):
for j in np.arange(0,M):
y[i+j] = y[i+j] + x[i] * h[j]
return y
Matlab
for i = 0:n+m,
yi = 0;
for i = 0 :n,
for k = 0 to m,
y[i+k] = y[i+k] + x[i] · h[k];
Method 2 – Using Toeplitz Matrix:
When the sequences \(h[n]\) and \(x[n]\) are represented as matrices, the linear convolution operation can be equivalently represented as
\[y=h \ast x=x \ast h=Toeplitz(h) X\]
Assume that the sequence \(h[n]\) is of length 4 given by \(h[n]=[h_0,h_1,h_2,h_3]\) and the sequence \(x[n]\) is of length 3 given by \(x[n]=[x_0,x_1,x_2]\). The convolution \(h[n] \ast x[n]\) is given by
The matrix representing the incremental delays of \(h[n]\) used in the above equation is a special form of matrix called Toeplitz matrix. Toeplitz matrix have constant entries along their diagonals. Toeplitz matrices are used to model systems that posses shift invariant properties. The property of shift invariance is evident from the matrix structure itself. Since we are modelling a Linear Time Invariant system[1], Toeplitz matrices are our natural choice. On a side note, a special form of Toeplitz matrix called “circulant matrix” is used in applications involving circular convolution and Discrete Fourier Transform (DFT)[2].
In Matlab, it is constructed by calling Toeplitz function[3] with two arguments. The first argument is the first column of the above matrix -\( [h_0,h_1,h_2,h_3,0,0]\) and the second argument is the first row of the above matrix – \([h_0,0,0]\).
y=toeplitz([h0 h1 h2 h3 0 0],[h0 0 0])*x.';
In the generalized case, where \(x\) and \(h\) are of any arbitrary lengths (say \(N\) and \(M\)), the code can be modified as follows [here it is assumed that \( length (x) \geq length(h)\) ]
Computation of convolution using FFT (Fast Fourier Transform) has the advantage of reduced computational complexity when the length of inputs are large. To compute convolution, take FFT of the two sequences \(x\) and \(h\) with FFT length set to convolution output length \(length (x)+length(h)-1\), multiply the results and convert back to time-domain using IFFT (Inverse Fast Fourier Transform). Note that FFT is a direct implementation of circular convolution in time domain. Here we are attempting to compute linear convolution using circular convolution (or FFT) with zero-padding either one of the input sequence. This causes inefficiency when compared to circular convolution. Nevertheless, this method still provides \(O\left(\frac{N}{log_2N}\right)\) savings over brute-force method.
from scipy.fftpack import fft,ifft
y=ifft(fft(x,L)*(fft(h,L))) #Convolution using FFT and IFFT
Matlab
y=ifft(fft(x,L).*(fft(h,L)))
Other Methods:
If the input sequence is of infinite length or very very large as in many real time applications, block processing methods like Overlap-Add and Overlap-Save methods can be used to compute convolution in a faster and efficient way.
Standard Algorithms for Fast Convolution:
Standard algorithms for computing convolution that greatly reduce the computational complexity are
Refer [4] -Fast Algorithms for Signal Processing by Richard E. Blahut for more details on the above algorithms (see reference section below).
Matlab Code
Implementing method 2 (convolution using Toeplitz matrix transformation) and method 3 (convolution using FFT) and comparing against Matlab’s standard conv function:
%Create random vectors for test
x=rand(1,7)+1i*rand(1,7);
h=rand(1,3)+1i*rand(1,3);
L=length(x)+length(h)-1;
%Convolution Using Toeplitz matrix
y1=toeplitz([h zeros(1,length(x)-1)],[h(1) zeros(1,length(x)-1)])*x.'
%Convolution FFT
y2=ifft(fft(x,L).*(fft(h,L))).'
%Matlab's standard function
y3=conv(h,x).'
Simulation output:
Comparing method 2 and method 3 against Matlab’s standard convolution function returns identical results
Convolution operation is ubiquitous in signal processing applications. The mathematics of convolution is strongly rooted in operation on polynomials. The intent of this text is to enhance the understanding on mathematical details of convolution.
Polynomial functions:
Polynomial functions are expressions consisting of sum of terms, where each term includes one or more variables raised to a non-negative power and each term may be scaled by a coefficient. Addition, Subtraction and multiplication of polynomials are possible.
Polynomial functions can involve one or more variables. For example, following polynomial expression is a function of variable x. It involves sum of 3 terms where each term is scaled by a coefficient. Polynomial expression involving two variables ‘x’ and ‘y’ is given next.
Representing single variable polynomial functions:
Polynomial functions involving single variable is of specific interest here. In general a single variable (say ‘x’) polynomial is expressed in the following sum of terms form, where are coefficients of the polynomial.
The degree or order of the polynomial function is the highest power of with a non-zero coefficient. The above equation can be written as
It is also represented by a vector of coefficients as .
Polynomials can also be represented using their roots which is a product of linear terms form, as explained later.
Multiplication of polynomials and linear convolution:
As indicated earlier, mathematical operations like additions, subtractions and multiplications can be performed on polynomial functions. Addition or subtraction of polynomials is straight forward. Multiplication of polynomials is of specific interest in the context of subject discussed here.
Computing the product of two polynomials represented by the coefficient vectors and . The usual representation of such polynomials is given by
The product vector is represented as
Or equivalently as
Since the subscripts obey the equality , changing the subscript to gives
Which, when written in terms of indices, provides the most widely used form seen in signal processing text books.
This operation is referred as convolution (linear convolution, to be precise), denoted as . It is very closely related to other operations on vectors – cross-correlation, auto-correlation and moving average computation. Thus when we are computing convolution, we are actually multiplying two polynomials.
Note, that if the polynomials have and terms, their multiplication produces terms.
The straightforward algorithm (shown below) that implements the above product expression will consume time. A better algorithm is a necessity. It turns out that viewing the polynomials as product of linear factors of complex roots will save much of the computations. This forms the basis for Fast Fourier Transform, where nth root of unity is utilized recursively to do the computation in frequency domain (in signal processing perspective). More about this later.
for i = 0:n+m,
ci = 0;
for i = 0 :n,
for k = 0 to m,
c[i+k] = c[i+k] + a[i] · b[k];
Toeplitz Matrix and Convolution:
Convolution operation of two sequences can be viewed as multiplying two matrices as explained next. Given a LTI (Linear Time Invariant) system with impulse response and an input sequence , the output of the system is obtained by convolving the input sequence and impulse response.
where, the sequence is of length and is of length .
Assume that the sequence is of length 4 given by and the sequence is of length 3 given by . The convolution is given by
Computing each sample in the convolution,
Note the above result. See how the series and multiply with each other from the opposite directions. This gives the reason on why we have to reverse one of the sequences and shift one step a time to do the convolution operation (This is often depicted graphically on standard signal processing texts.. You might have wondered why we have to do this… Now, rejoice that you have understood the reason behind it)
Thus, graphically, in convolution, one of the sequences (say ) is reversed. It is delayed to the extreme left where there are no overlaps between the two sequences. Now, the sample offset of is increased 1 step at a time. At each step, the overlapping portions of and are multiplied and summed. This process is repeated till the sequence is slid to the extreme right where no more overlaps between and are possible.
Writing the final result in the previous equation in matrix form,
When the sequences and are represented as matrices, the convolution operation can be equivalently represented as
The matrix representing the incremental delays of used in the above equation is a special form of matrix called Toeplitz matrix. Toeplitz matrix have constant entries along their diagonals. Toeplitz matrices are used to model systems that posses shift invariant properties. The property of shift invariance is evident from the matrix structure itself. Since we are modelling a Linear Time Invariant system[1], Toeplitz matrices are our natural choice. On a side note, a special form of Toeplitz matrix called “circulant matrix” is used in applications involving circular convolution and Discrete Fourier Transform (DFT)[2].
Representing the operation used to construct the Toeplitz matrix out of the sequence as ,
Now, the convolution of and is simply a matrix multiplication of Toeplitz matrix and the matrix representation of denoted as
One can quickly vectorize the convolution operation in matlab by using Toeplize matrices as shown below.
Let x(t) be a sine wave of amplitude A and frequency fc represented by the following equation.
When represented in frequency domain, it will look like the one on the right side plot in the following figure. This is evident from the fact that the sinewave can be mathematically represented by applying Euler’s formula.
Taking the Fourier transform of x(t) to represent it in frequency domain,
When considering the amplitude part,the above decomposition gives two spikes of amplitude A/2 on either side of the frequency domain at fc and -fc.
Figure 1: Time domain representation and frequency spectrum of a pure sinewave
Squaring the amplitudes gives the magnitude of power of the individual spikes/frequency components. The power spectrum is plotted below.
Figure 2: Power spectrum of a pure sinewave
Thus if the pure sinewave is of amplitude A=1V and frequency=100Hz, the power spectrum will have two spikes of value at 100 Hz and -100 Hz frequencies. The total power will be
Let’s verify this through simulation.
Simulation and Verification
A sine wave of 100 Hz frequency and amplitude 1V is taken for the experiment.
A=1; %Amplitude of sine wave
Fc=100; %Frequency of sine wave
Fs=1000; %Sampling rate - oversampled by the rate of 10
Ts=1/Fs; %Sampling period
nCycles=200; %Number of cycles of the sinewave
subplot(2,1,1);
t=0:Ts:nCycles/Fc-Ts; %Time base
x=A*sin(2*pi*Fc*t); %Sinusoidal function
stem(t,x); %Plot command
A sinusoidal wave of 10 cycles is plotted here
Figure 3: Sine wave generated in Matlab
Matlab’s Norm function:
Matlab’s basic installation comes with “norm” function. The p-norm in Matlab is computed as
By default, the single argument norm function computed 2-norm given as
To compute the total power of the signal x[n] (as in equation (1) above), all we have to do is – compute norm(x), square it and divide by the length of the signal.
L=length(x);
P=(norm(x)^2)/L;
sprintf('Power of the Signal from Time domain %f',P);
The above given piece of code will result in the following output
Power of the Signal from Time domain 0.500000
Verifying the total Power by DFT : Frequency Domain
Here, the total power is verified by applying DFT on the sinusoidal sequence. The sinusoidal sequence x[n] is represented in frequency domain X[f] using Matlab’s FFT function. The power associated with each frequency point is computed as
Finally, the total power is calculated as the sum of all the points in the frequency domain representation.
X = fft(x);
Px=sum(X.*conj(X))/(L^2); %Compute power with proper scaling.
subplot(2,1,2)
% Plot single-sided amplitude spectrum.
stem(Px);
sprintf('Total Power of the Signal from DFT %f',P);
Result:
Total Power of the Signal from DFT 0.500000
Figure 4: Power spectrum of a pure sinewave simulated in Matlab
A word on Matlab’s FFT: Matlab’s FFT is optimized for faster performance if the transform length is a power of 2. The following snippet of code simply calls “fft” without the transform length. In this case, the window length and the transform length are the same. This is to simplify the calculation of power. You can re-write the call to the FFT routine with transform length set to next power of two which is greater than or equal to the window length (sequence length). Then the step to compute total power will be differing slightly in the denominator. But that will not improve resolution (Remember : zero padding to compute FFT will not improve resolution).
Also note that in the above simulation we are using a pure sinusoid. The entire sequence of sinusoid defined all the cycles completely. There are no discontinuities in the sequence. If you call FFT with the transform length set to next power of 2 (as given in Matlab manuals), it will pad additional zeros to the sequence and creates discontinuities in the FFT computation. This will lead to spectral leakage. FFT and spectral leakage is discussed here.
Rate this article: Note: There is a rating embedded within this post, please visit this post to rate it.
Key focus: Clearly understand the terms: power and energy of a signal, their mathematical definition, physical significance and computation in signal processing context.
Energy of a signal:
Defining the term “size”:
In signal processing, a signal is viewed as a function of time. The term “size of a signal” is used to represent “strength of the signal”. It is crucial to know the “size” of a signal used in a certain application. For example, we may be interested to know the amount of electricity needed to power a LCD monitor as opposed to a CRT monitor. Both of these applications are different and have different tolerances. Thus the amount of electricity driving these devices will also be different.
A given signal’s size can be measured in many ways. Given a mathematical function (or a signal equivalently), it seems that the area under the curve, described by the mathematical function, is a good measure of describing the size of a signal. A signal can have both positive and negative values. This may render areas that are negative. Due to this effect, it is possible that the computed values cancel each other totally or partially, rendering incorrect result. Thus the metric function of “area under the curve” is not suitable for defining the “size” of a signal. Now, we are left with two options : either 1) computation of the area under the absolute value of the function or 2) computation of the area under the square of the function. The second choice is favored due to its mathematical tractability and its similarity to Euclidean Norm which is used in signal detection techniques (Note: Euclidean norm – otherwise called L2 norm or 2-norm[1] – is often considered in signal detection techniques – on the assumption that it provides a reasonable measure of distance between two points on signal space. It is computed as Euclidean distance in detection theory).
Going by the second choice of viewing the “size” as the computation of the area under the square of the function, the energy of a continuous-time complex signal \(x(t)\) is defined as
\[E_x = \int_{-\infty}^{\infty} |x(t)|^2 dt\]
If the signal \(x(t)\) is real, the modulus operator in the above equation does not matter.
This is called “Energy” in signal processing terms. This is also a measure of signal strength. This definition can be applied to any signal (or a vector) irrespective of whether it possesses actual energy (a basic quantitative property as described by physics) or not. If the signal is associated with some physical energy, then the above definition gives the energy content in the signal. If the signal is an electrical signal, then the above definition gives the total energy of the signal (in Joules) dissipated over a 1 Ohm resistor.
Actual Energy – physical quantity:
To know the actual energy of the signal \(E\), one has to know the value of load \(Z\) the signal is driving and also the nature the electrical signal (voltage or current). For a voltage signal, the above equation has to be scaled by a factor of \(1/Z\).
\[E = ZE_x = Z \int_{-\infty}^{\infty} |x(t)|^2 dt\]
Here, \(Z\) is the impedance driven by the signal \(x(t)\) , \(E_x\) is the signal energy (signal processing term) and \(E\) is the Energy of the signal (physical quantity) driving the load \( Z\)
Energy in discrete domain:
In the discrete domain, the energy of the signal is given by
The energy is finite only if the above sum converges to a finite value. This implies that the signal is “squarely-summable“. Such a signal is called finite energy signal.
What if the given signal does not decay with respect to time (as in a continuous sine wave repeating its cycle infinitely) ? The energy will be infinite and such a signal is “not squarely-summable” in other words. We need another measurable quantity to circumvent this problem.This leads us to the notion of “Power”
Power:
Power is defined as the amount of energy consumed per unit time. This quantity is useful if the energy of the signal goes to infinity or the signal is “not-squarely-summable”. For “non-squarely-summable” signals, the power calculated by taking the snapshot of the signal over a specific interval of time as follows
1) Take a snapshot of the signal over some finite time duration 2) Compute the energy of the signal \(E_x\) 3) Divide the energy by number of samples taken for computation \(N\) 4) Extend the limit of number of samples to infinity \(N\rightarrow \infty \). This gives the total power of the signal.
In discrete domain, the total power of the signal is given by
Following equations are different forms of the same computation found in many text books. The only difference is the number of samples taken for computation. The denominator changes according to the number of samples taken for computation.
A signal can be classified based on its power or energy content. Signals having finite energy are energy signals. Power signals have finite and non-zero power.
Energy Signal :
A finite energy signal will have zero TOTAL power. Let’s investigate this statement in detail. When the energy is finite, the total power will be zero. Check out the denominator in the equation for calculating the total power. When the limit \(N\rightarrow \infty\), the energy dilutes to zero over the infinite duration and hence the total power becomes zero.
Power Signal:
Signals whose total power is finite and non-zero. The energy of the power signal will be infinite. Example: Periodic sequences like sinusoid. A sinusoidal signal has finite, non-zero power but infinite energy.
A signal cannot be both an energy signal and a power signal.
Neither an Energy signal nor a Power signal:
Signals can also be a cat on the wall – neither an energy signal nor a power signal. Consider a signal of increasing amplitude defined by,
\[x(n) = n\]
For such a signal, both the energy and power will be infinite. Thus, it cannot be classified either as an energy signal or as a power signal.
A random process (or signal for your visualization) with a constant power spectral density (PSD) function is a white noise process.
Power Spectral Density
Power Spectral Density function (PSD) shows how much power is contained in each of the spectral component. For example, for a sine wave of fixed frequency, the PSD plot will contain only one spectral component present at the given frequency. PSD is an even function and so the frequency components will be mirrored across the Y-axis when plotted. Thus for a sine wave of fixed frequency, the double sided plot of PSD will have two components – one at +ve frequency and another at –ve frequency of the sine wave. (Know how to plot PSD/FFT in Python & in Matlab)
Gaussian and Uniform White Noise:
A white noise signal (process) is constituted by a set of independent and identically distributed (i.i.d) random variables. In discrete sense, the white noise signal constitutes a series of samples that are independent and generated from the same probability distribution. For example, you can generate a white noise signal using a random number generator in which all the samples follow a given Gaussian distribution. This is called White Gaussian Noise (WGN) or Gaussian White Noise. Similarly, a white noise signal generated from a Uniform distribution is called Uniform White Noise.
Gaussian Noise and Uniform Noise are frequently used in system modelling. In modelling/simulation, white noise can be generated using an appropriate random generator. White Gaussian Noise can be generated using randn function in Matlab which generates random numbers that follow a Gaussian distribution. Similarly, rand function can be used to generate Uniform White Noise in Matlab that follows a uniform distribution. When the random number generators are used, it generates a series of random numbers from the given distribution. Let’s take the example of generating a White Gaussian Noise of length 10 using randn function in Matlab – with zero mean and standard deviation=1.
This simply generates 10 random numbers from the standard normal distribution. As we know that a white process is seen as a random process composing several random variables following the same Probability Distribution Function (PDF). The 10 random numbers above are generated from the same PDF (standard normal distribution). This condition is called “identically distributed” condition. The individual samples given above are “independent” of each other. Furthermore, each sample can be viewed as a realization of one random variable. In effect, we have generated a random process that is composed of realizations of 10 random variables. Thus, the process above is constituted from “independent identically distributed” (i.i.d) random variables.
Strictly and weakly defined white noise:
Since the white noise process is constructed from i.i.d random variable/samples, all the samples follow the same underlying probability distribution function (PDF). Thus, the Joint Probability Distribution function of the process will not change with any shift in time. This is called a stationary process. Hence, this noise is a stationary process. As with a stationary process which can be classified as Strict Sense Stationary (SSS) and Wide Sense Stationary (WSS) processes, we can have white noise that is SSS and white noise that is WSS. Correspondingly they can be called strictly defined white noise signal and weakly defined white noise signal.
What’s with Covariance Function/Matrix ?
A white noise signal, denoted by \(x(t)\), is defined in weak sense is a more practical condition. Here, the samples are statistically uncorrelated and identically distributed with some variance equal to \(\sigma^2\). This condition is specified by using a covariance function as
\[COV \left(x_i, x_j \right) = \begin{cases} \sigma^2, & \quad i = j \\ 0, & \quad i \neq j \end{cases}\]
Why do we need a covariance function? Because, we are dealing with a random process that is composed of \(n\) random variables (10 variables in the modelling example above). Such a process is viewed as multivariate random vector or multivariate random variable.
For multivariate random variables, Covariance function specified how each of the \(n\) variables in the given random process behaves with respect to each other. Covariance function generalizes the notion of variance to multiple dimensions.
The above equation when represented in the matrix form gives the covariance matrix of the white noise random process. Since the random variables in this process are statistically uncorrelated, the covariance function contains values only along the diagonal.
The matrix above indicates that only the auto-correlation function exists for each random variable. The cross-correlation values are zero (samples/variables are statistically uncorrelated with respect to each other). The diagonal elements are equal to the variance and all other elements in the matrix are zero.The ensemble auto-correlation function of the weakly defined white noise is given by This indicates that the auto-correlation function of weakly defined white noise process is zero everywhere except at lag \(\tau=0\).
\[R_{xx}(\tau) = E \left[ x(t) x^*(t-\tau)\right] = \sigma^2 \delta (\tau)\]
Wiener-Khintchine Theorem states that for Wide Sense Stationary Process (WSS), the power spectral density function \(S_{xx}(f)\) of a random process can be obtained by Fourier Transform of auto-correlation function of the random process. In continuous time domain, this is represented as
\[S_{xx}(f) = F \left[R_{xx}(\tau) \right] = \int_{-\infty}^{\infty} R_{xx} (\tau) e ^{- j 2 \pi f \tau} d \tau\]
For the weakly defined white noise process, we find that the mean is a constant and its covariance does not vary with respect to time. This is a sufficient condition for a WSS process. Thus we can apply Weiner-Khintchine Theorem. Therefore, the power spectral density of the weakly defined white noise process is constant (flat) across the entire frequency spectrum (Figure 1). The value of the constant is equal to the variance or power of the noise signal.
\[S_{xx}(f) = F \left[R_{xx}(\tau) \right] = \int_{-\infty}^{\infty} \sigma^2 \delta (\tau) e ^{- j 2 \pi f \tau} d \tau = \sigma^2 \int_{-\infty}^{\infty} \delta (\tau) e ^{- j 2 \pi f \tau} = \sigma^2\]
Figure 1: Weiner-Khintchine theorem illustrated
Testing the characteristics of White Gaussian Noise in Matlab:
Generate a Gaussian white noise signal of length \(L=100,000\) using the randn function in Matlab and plot it. Let’s assume that the pdf is a Gaussian pdf with mean \(\mu=0\) and standard deviation \(\sigma=2\). Thus the variance of the Gaussian pdf is \(\sigma^2=4\). The theoretical PDF of Gaussian random variable is given by
subplot(2,1,2)
n=100; %number of Histrogram bins
[f,x]=hist(X,n);
bar(x,f/trapz(x,f)); hold on;
%Theoretical PDF of Gaussian Random Variable
g=(1/(sqrt(2*pi)*sigma))*exp(-((x-mu).^2)/(2*sigma^2));
plot(x,g);hold off; grid on;
title('Theoretical PDF and Simulated Histogram of White Gaussian Noise');
legend('Histogram','Theoretical PDF');
xlabel('Bins');
ylabel('PDF f_x(x)');
Figure 3: Plot of simulated & theoretical PDF for Gaussian RV
Compute the auto-correlation function of the white noise. The computed auto-correlation function has to be scaled properly. If the ‘xcorr’ function (inbuilt in Matlab) is used for computing the auto-correlation function, use the ‘biased’ argument in the function to scale it properly.
figure();
Rxx=1/L*conv(flipud(X),X);
lags=(-L+1):1:(L-1);
%Alternative method
%[Rxx,lags] =xcorr(X,'biased');
%The argument 'biased' is used for proper scaling by 1/L
%Normalize auto-correlation with sample length for proper scaling
plot(lags,Rxx);
title('Auto-correlation Function of white noise');
xlabel('Lags')
ylabel('Correlation')
grid on;
Figure 4: Autocorrelation function of generated noise
Simulating the PSD:
Simulating the Power Spectral Density (PSD) of the white noise is a little tricky business. There are two issues here 1) The generated samples are of finite length. This is synonymous to applying truncating an infinite series of random samples. This implies that the lags are defined over a fixed range. ( FFT and spectral leakage – an additional resource on this topic can be found here) 2) The random number generators used in simulations are pseudo-random generators. Due these two reasons, you will not get a flat spectrum of psd when you apply Fourier Transform over the generated auto-correlation values.The wavering effect of the psd can be minimized by generating sufficiently long random signal and averaging the psd over several realizations of the random signal.
Simulating Gaussian White Noise as a Multivariate Gaussian Random Vector:
To verify the power spectral density of the white noise, we will use the approach of envisaging the noise as a composite of \(N\) Gaussian random variables. We want to average the PSD over \(L\) such realizations. Since there are \(N\) Gaussian random variables (\(N\) individual samples) per realization, the covariance matrix \( C_{xx}\) will be of dimension \(N \times N\). The vector of mean for this multivariate case will be of dimension \(1 \times N\).
Cholesky decomposition of covariance matrix gives the equivalent standard deviation for the multivariate case. Cholesky decomposition can be viewed as square root operation. Matlab’s randn function is used here to generate the multi-dimensional Gaussian random process with the given mean matrix and covariance matrix.
%Verifying the constant PSD of White Gaussian Noise Process
%with arbitrary mean and standard deviation sigma
mu=0; %Mean of each realization of Noise Process
sigma=2; %Sigma of each realization of Noise Process
L = 1000; %Number of Random Signal realizations to average
N = 1024; %Sample length for each realization set as power of 2 for FFT
%Generating the Random Process - White Gaussian Noise process
MU=mu*ones(1,N); %Vector of mean for all realizations
Cxx=(sigma^2)*diag(ones(N,1)); %Covariance Matrix for the Random Process
R = chol(Cxx); %Cholesky of Covariance Matrix
%Generating a Multivariate Gaussian Distribution with given mean vector and
%Covariance Matrix Cxx
z = repmat(MU,L,1) + randn(L,N)*R;
Compute PSD of the above generated multi-dimensional process and average it to get a smooth plot.
%By default, FFT is done across each column - Normal command fft(z)
%Finding the FFT of the Multivariate Distribution across each row
%Command - fft(z,[],2)
Z = 1/sqrt(N)*fft(z,[],2); %Scaling by sqrt(N);
Pzavg = mean(Z.*conj(Z));%Computing the mean power from fft
normFreq=[-N/2:N/2-1]/N;
Pzavg=fftshift(Pzavg); %Shift zero-frequency component to center of spectrum
plot(normFreq,10*log10(Pzavg),'r');
axis([-0.5 0.5 0 10]); grid on;
ylabel('Power Spectral Density (dB/Hz)');
xlabel('Normalized Frequency');
title('Power spectral density of white noise');
Figure 5: Power spectral density of generated noise
The PSD plot of the generated noise shows almost fixed power in all the frequencies. In other words, for a white noise signal, the PSD is constant (flat) across all the frequencies (\(- \infty\) to \(+\infty\)). The y-axis in the above plot is expressed in dB/Hz unit. We can see from the plot that the \(constant \; power = 10 log_{10}(\sigma^2) = 10 log_{10}(4) = 6\; dB\).
Application
In channel modeling, we often come across additive white Gaussian noise (AWGN) channel. To know more about the channel model and its simulation, continue reading this article: Simulate AWGN channel in Matlab & Python.
Rate this article: Note: There is a rating embedded within this post, please visit this post to rate it.
Note: There is a rating embedded within this post, please visit this post to rate it.
Researchers, working on Ultra-Parallel Visible Light Communications (UP-VLC) project, have demonstrated 3.5Gpbs free space data transmission via three separate micro-LEDs that emit red, blue and green colours. In effect, combining the three colours (that makes up for white colour), researchers say that achieving data rates over 10Gbps is feasible.
The technology enabler here is called – “Li-Fi”, a term coined by Prof. Harold Haas of University of Edinburgh, uses LED lights as medium of data transmission. Li-Fi, academically referred as “Visible Light Communication”, aims to use existing micro- LED light bulbs for both illumination and communication.
With the advent of this technology, soon you will see all the illuminated spots in offices, houses or any other place turning into internet hotspots streaming high quality data. It has become a hot topic and soon many big corporations will jump on to the Li-Fi bandwagon.
It all started with Prof. Hass’s research group demonstrating the proof-of-concept results that exploited the higher peak-to-average ratio (PAR) property of Orthogonal Frequency Division Multiplexing (OFDM) systems. PAR, otherwise called “Crest Factor”, is a disadvantage in RF communications. The research group have used this property to turn commercially available LED bulbs to ultra-high speed wireless hotspots. Later, this work was featured in TIME magazine’s “50 Best inventions of the year 2011” and Nobel Laureate Prof. Hänsch listed this work in his book titled “100 ground-breaking ideas” that could shape the next century.
Using OFDM, micro-LED light bulbs are enabled to handing millions of light-intensity-changes per second. Essentially, the micro-LED bulbs are switched on and off depending on the input bits –‘0’ or ‘1’. The switching is done at such a high speed that it is undetectable by human eye. Thus both un-flickering-illumination and high-speed-communication are achievable under this condition.
Li-Fi carries the promise of breaking the bandwidth-crunch suffered by existing wireless systems. The demand for more bandwidth is skyrocketing day by day with the proliferation of wireless enabled devices. The crunch faced by Radio-Frequency (RF) systems, is also compounded by complex government regulations, needs of a growing base of customers and risking of the performance issues due to these challenges.
Li-Fi is essentially a wireless system. It uses the visible light region of the electromagnetic spectrum which is 10,000 times larger than the microwave region of the electromagnetic spectrum. This opens up the utilizable frequencies to the order of terahertz level. It will not interfere with existing devices and it can be used in areas where there is extensive RF noise or in places where RF frequencies are restricted (like in airplanes).
Watch the TED talk – “Wireless data from every light bulb”- where Prof Haas demonstrates the capability of Li-Fi technology system prototype (using a desk-lamp) that steams a HD movie in real-time.
This site uses cookies responsibly. Learn more in our privacy policy.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.



![x[n] + a_1 x[n-1] + a_2 x[n-2] + \cdots + a_N x[n-N] = w[n]](https://s0.wp.com/latex.php?latex=x%5Bn%5D+%2B+a_1+x%5Bn-1%5D+%2B+a_2+x%5Bn-2%5D+%2B+%5Ccdots+%2B+a_N+x%5Bn-N%5D+%3D+w%5Bn%5D+&bg=ffffff&fg=000&s=1&c=20201002)

![\displaystyle{ w[n]= x[n]-\left(-\sum^{N}_{k=1}a_k x[n-k] \right)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+w%5Bn%5D%3D+x%5Bn%5D-%5Cleft%28-%5Csum%5E%7BN%7D_%7Bk%3D1%7Da_k+x%5Bn-k%5D+%5Cright%29%7D+&bg=ffffff&fg=000&s=1&c=20201002)


![\begin{aligned} x[n] + a_1 x[n-1] + \cdots + a_N x[n-N] = & b_0 w[n] + b_1 w[n-1] + \\ & \cdots + b_M w[n-M] \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+x%5Bn%5D+%2B+a_1+x%5Bn-1%5D+%2B+%5Ccdots+%2B+a_N+x%5Bn-N%5D+%3D+%26+b_0+w%5Bn%5D+%2B+b_1+w%5Bn-1%5D+%2B+%5C%5C+%26+%5Ccdots+%2B+b_M+w%5Bn-M%5D+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=1&c=20201002)

![\displaystyle{ w[n]= x[n]-\left(-\sum^{N}_{k=1}a_k x[n-k] + \sum^{M}_{k=1}b_k w[n-k] \right)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+w%5Bn%5D%3D+x%5Bn%5D-%5Cleft%28-%5Csum%5E%7BN%7D_%7Bk%3D1%7Da_k+x%5Bn-k%5D+%2B+%5Csum%5E%7BM%7D_%7Bk%3D1%7Db_k+w%5Bn-k%5D+%5Cright%29%7D+&bg=ffffff&fg=000&s=1&c=20201002)
















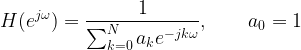



![x[n] = b_0 w[n] + b_1 w[n-1] + b_2 w[n-2] + \cdots + b_M w[n-M]](https://s0.wp.com/latex.php?latex=x%5Bn%5D+%3D+b_0+w%5Bn%5D+%2B+b_1+w%5Bn-1%5D+%2B+b_2+w%5Bn-2%5D+%2B+%5Ccdots+%2B+b_M+w%5Bn-M%5D++&bg=ffffff&fg=000&s=1&c=20201002)





![x[n] + a_1 x[n-1] + \cdots + a_N x[n-N] = b_0 w[n] + b_1 w[n-1] + \cdots + b_M w[n-M]](https://s0.wp.com/latex.php?latex=x%5Bn%5D+%2B+a_1+x%5Bn-1%5D+%2B+%5Ccdots+%2B+a_N+x%5Bn-N%5D+%3D+b_0+w%5Bn%5D+%2B+b_1+w%5Bn-1%5D+%2B+%5Ccdots+%2B+b_M+w%5Bn-M%5D+&bg=ffffff&fg=000&s=1&c=20201002)

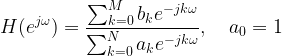



![\mathbb{\theta}=[ \theta_1, \theta_2, ..., \theta_p]^{T}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7B%5Ctheta%7D%3D%5B+%5Ctheta_1%2C+%5Ctheta_2%2C+...%2C+%5Ctheta_p%5D%5E%7BT%7D+&bg=ffffff&fg=000&s=0&c=20201002)

![\mathbb{\hat{\theta}} = [ \hat{\theta_1}, \hat{\theta_2}, ..., \hat{\theta_p} ]^{T}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7B%5Chat%7B%5Ctheta%7D%7D+%3D+%5B+%5Chat%7B%5Ctheta_1%7D%2C+%5Chat%7B%5Ctheta_2%7D%2C+...%2C+%5Chat%7B%5Ctheta_p%7D+%5D%5E%7BT%7D&bg=ffffff&fg=000&s=0&c=20201002)

![E[\hat{\theta}] = \theta](https://s0.wp.com/latex.php?latex=E%5B%5Chat%7B%5Ctheta%7D%5D+%3D+%5Ctheta+&bg=ffffff&fg=000&s=0&c=20201002)

![C_{\hat{\theta}} =var ( \hat{\theta} ) = E \left[ ( \hat{\theta} - \theta )( \hat{\theta} - \theta )^T \right]](https://s0.wp.com/latex.php?latex=C_%7B%5Chat%7B%5Ctheta%7D%7D+%3Dvar+%28+%5Chat%7B%5Ctheta%7D+%29+%C2%A0%3D+E+%5Cleft%5B+%C2%A0%28+%5Chat%7B%5Ctheta%7D+-+%5Ctheta+%29%28+%5Chat%7B%5Ctheta%7D+-+%5Ctheta+%29%5ET+%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)

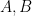

![\theta = [A,B,C] ^T](https://s0.wp.com/latex.php?latex=%5Ctheta+%3D+%5BA%2CB%2CC%5D+%5ET+&bg=ffffff&fg=000&s=0&c=20201002)

![C_{\hat{\theta}} = \left[ \begin{matrix} var(\hat{A}) & cov(\hat{A},\hat{B}) & cov(\hat{A},\hat{C}) \\ cov(\hat{B},\hat{A}) & var(\hat{B}) & cov(\hat{B},\hat{C}) \\ cov(\hat{C},\hat{A}) & cov(\hat{C},\hat{B}) & var(\hat{C}) \end{matrix} \right]](https://s0.wp.com/latex.php?latex=C_%7B%5Chat%7B%5Ctheta%7D%7D+%3D+%5Cleft%5B+%C2%A0%5Cbegin%7Bmatrix%7D+var%28%5Chat%7BA%7D%29+%26+cov%28%5Chat%7BA%7D%2C%5Chat%7BB%7D%29+%26+cov%28%5Chat%7BA%7D%2C%5Chat%7BC%7D%29+%5C%5C+%C2%A0cov%28%5Chat%7BB%7D%2C%5Chat%7BA%7D%29+%26+var%28%5Chat%7BB%7D%29+%26+cov%28%5Chat%7BB%7D%2C%5Chat%7BC%7D%29+%5C%5C+%C2%A0cov%28%5Chat%7BC%7D%2C%5Chat%7BA%7D%29+%26+cov%28%5Chat%7BC%7D%2C%5Chat%7BB%7D%29+%26+var%28%5Chat%7BC%7D%29+%5Cend%7Bmatrix%7D+%5Cright%5D%C2%A0+&bg=ffffff&fg=000&s=1&c=20201002)



![[I(\theta)] _{ij} = \displaystyle{-E \left[ \frac{\delta^2}{\delta \theta_i \delta \theta_j} ln \; p(x;\theta) \right]} \; \; i,j =1,2,3,\cdots,p](https://s0.wp.com/latex.php?latex=%C2%A0%5BI%28%5Ctheta%29%5D+_%7Bij%7D+%3D+%5Cdisplaystyle%7B-E+%5Cleft%5B+%C2%A0%5Cfrac%7B%5Cdelta%5E2%7D%7B%5Cdelta+%5Ctheta_i+%5Cdelta+%5Ctheta_j%7D+ln+%5C%3B+p%28x%3B%5Ctheta%29+%5Cright%5D%7D%C2%A0+%5C%3B+%5C%3B+i%2Cj+%3D1%2C2%2C3%2C%5Ccdots%2Cp+&bg=ffffff&fg=000&s=1&c=20201002)

![\displaystyle{E \left[ \frac{\delta}{ \delta \theta} ln\; p(x;\theta) \right] = 0} \;\;\; \forall \theta](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7BE+%5Cleft%5B+%5Cfrac%7B%5Cdelta%7D%7B+%5Cdelta+%5Ctheta%7D+ln%5C%3B+p%28x%3B%5Ctheta%29+%5Cright%5D+%3D+0%7D+%5C%3B%5C%3B%5C%3B+%5Cforall+%5Ctheta+&bg=ffffff&fg=000&s=1&c=20201002)



![\left[ C_{(\hat{\theta})} \right]_{ii} \geq \left[ I^{-1}(\theta) \right]_{ii}](https://s0.wp.com/latex.php?latex=%C2%A0+%5Cleft%5B+C_%7B%28%5Chat%7B%5Ctheta%7D%29%7D+%5Cright%5D_%7Bii%7D+%5Cgeq+%C2%A0%5Cleft%5B+I%5E%7B-1%7D%28%5Ctheta%29+%5Cright%5D_%7Bii%7D%C2%A0+&bg=ffffff&fg=000&s=1&c=20201002)
















![a=[a_0,a_1,a_2,...,a_{n-1}]](https://s0.wp.com/latex.php?latex=a%3D%5Ba_0%2Ca_1%2Ca_2%2C...%2Ca_%7Bn-1%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)

![a=[a_0,a_1,a_2,...,a_n]](https://s0.wp.com/latex.php?latex=a%3D%5Ba_0%2Ca_1%2Ca_2%2C...%2Ca_n%5D&bg=ffffff&fg=000&s=0&c=20201002)

![b=[b_0,b_1,b_2,...,b_n]](https://s0.wp.com/latex.php?latex=b%3D%5Bb_0%2Cb_1%2Cb_2%2C...%2Cb_n%5D&bg=ffffff&fg=000&s=0&c=20201002)

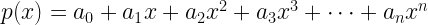





![p(x) . q(x)=(p\ast q)(x)=a.b=[c_0,c_1,c_2,\cdots,c_{n+m}] \; , \;where](https://s0.wp.com/latex.php?latex=p%28x%29+.+q%28x%29%3D%28p%5Cast+q%29%28x%29%3Da.b%3D%5Bc_0%2Cc_1%2Cc_2%2C%5Ccdots%2Cc_%7Bn%2Bm%7D%5D+%5C%3B+%2C+%5C%3Bwhere+&bg=ffffff&fg=000&s=2&c=20201002)









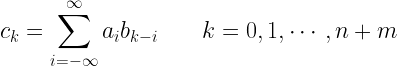

![c[k]=\displaystyle{\sum_{i=-\infty}^{\infty}a[i]b[k-i]} \quad\quad k=0,1,\cdots,n+m](https://s0.wp.com/latex.php?latex=c%5Bk%5D%3D%5Cdisplaystyle%7B%5Csum_%7Bi%3D-%5Cinfty%7D%5E%7B%5Cinfty%7Da%5Bi%5Db%5Bk-i%5D%7D+%5Cquad%5Cquad+k%3D0%2C1%2C%5Ccdots%2Cn%2Bm+&bg=ffffff&fg=000&s=2&c=20201002)











![h[n]](https://s0.wp.com/latex.php?latex=h%5Bn%5D&bg=ffffff&fg=000&s=0&c=20201002)
![x[n]](https://s0.wp.com/latex.php?latex=x%5Bn%5D&bg=ffffff&fg=000&s=0&c=20201002)

![y[n]](https://s0.wp.com/latex.php?latex=y%5Bn%5D&bg=ffffff&fg=000&s=0&c=20201002)

![y[k]=h[n]*x[n] = \displaystyle{\sum_{i=-\infty}^{\infty}x[i]h[k-i]}](https://s0.wp.com/latex.php?latex=y%5Bk%5D%3Dh%5Bn%5D%2Ax%5Bn%5D+%3D+%5Cdisplaystyle%7B%5Csum_%7Bi%3D-%5Cinfty%7D%5E%7B%5Cinfty%7Dx%5Bi%5Dh%5Bk-i%5D%7D+&bg=ffffff&fg=000&s=2&c=20201002)

![h[n]=[h_0,h_1,h_2,h_3]](https://s0.wp.com/latex.php?latex=h%5Bn%5D%3D%5Bh_0%2Ch_1%2Ch_2%2Ch_3%5D&bg=ffffff&fg=000&s=0&c=20201002)

![x[n]=[x_0,x_1,x_2]](https://s0.wp.com/latex.php?latex=x%5Bn%5D%3D%5Bx_0%2Cx_1%2Cx_2%5D&bg=ffffff&fg=000&s=0&c=20201002)

![h[n] \ast x[n]](https://s0.wp.com/latex.php?latex=h%5Bn%5D+%5Cast+x%5Bn%5D&bg=ffffff&fg=000&s=0&c=20201002)

![y[k]=h[n]*x[n] = \displaystyle{\sum_{i=-\infty}^{\infty}x[i]h[k-i]} \quad k=0,1,\cdots,5](https://s0.wp.com/latex.php?latex=y%5Bk%5D%3Dh%5Bn%5D%2Ax%5Bn%5D+%3D+%5Cdisplaystyle%7B%5Csum_%7Bi%3D-%5Cinfty%7D%5E%7B%5Cinfty%7Dx%5Bi%5Dh%5Bk-i%5D%7D+%5Cquad+k%3D0%2C1%2C%5Ccdots%2C5+&bg=ffffff&fg=000&s=2&c=20201002)



![\begin{bmatrix} y[0]\\y[1]\\y[2]\\y[3]\\y[4]\\y[5] \end{bmatrix}=\begin{bmatrix}h[0] &0 & 0 \\ h[1] & h[0] & 0 \\ h[2] & h[1] & h[0] \\ h[3] & h[2] & h[1] \\ 0 & h[3] & h[2] \\ 0 & 0 & h[3] \end{bmatrix} \begin{bmatrix}x[0]\\x[1]\\x[2] \end{bmatrix}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Bbmatrix%7D+y%5B0%5D%5C%5Cy%5B1%5D%5C%5Cy%5B2%5D%5C%5Cy%5B3%5D%5C%5Cy%5B4%5D%5C%5Cy%5B5%5D+%5Cend%7Bbmatrix%7D%3D%5Cbegin%7Bbmatrix%7Dh%5B0%5D+%260+%26+0+%5C%5C+h%5B1%5D+%26+h%5B0%5D+%26+0+%5C%5C+h%5B2%5D+%26+h%5B1%5D+%26+h%5B0%5D+%5C%5C+h%5B3%5D+%26+h%5B2%5D+%26+h%5B1%5D+%5C%5C+0+%26+h%5B3%5D+%26+h%5B2%5D+%5C%5C+0+%26+0+%26+h%5B3%5D+%5Cend%7Bbmatrix%7D+%5Cbegin%7Bbmatrix%7Dx%5B0%5D%5C%5Cx%5B1%5D%5C%5Cx%5B2%5D+%5Cend%7Bbmatrix%7D+&bg=ffffff&fg=000&s=2&c=20201002)

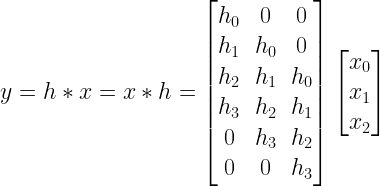












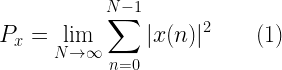



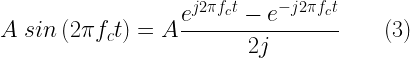

![\begin{aligned} X(f) &= F \left[ A\; sin \left( 2 \pi f_c t \right)\right] \\ &= \int_{- \infty}^{\infty} \left[ \frac{e^{j 2 \pi f_c t} - e^{-j 2 \pi f_c t} }{2 j} \right] e^{- j 2 \pi f t} \\ &= \frac{A}{ 2 j } \left[ \delta (f - f_c) - \delta (f + f_c) \right] \end{aligned} \quad\quad (4)](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+X%28f%29+%26%3D+F+%5Cleft%5B+A%5C%3B+sin+%5Cleft%28+2+%5Cpi+f_c+t+%5Cright%29%5Cright%5D+%5C%5C+%26%3D+%5Cint_%7B-+%5Cinfty%7D%5E%7B%5Cinfty%7D+%5Cleft%5B++%5Cfrac%7Be%5E%7Bj+2+%5Cpi+f_c+t%7D+-+e%5E%7B-j+2+%5Cpi+f_c+t%7D+%7D%7B2+j%7D++%5Cright%5D+e%5E%7B-+j+2+%5Cpi+f+t%7D+%5C%5C+%26%3D+%5Cfrac%7BA%7D%7B+2+j+%7D+%5Cleft%5B+%5Cdelta+%28f+-+f_c%29+-+%5Cdelta+%28f+%2B+f_c%29+%5Cright%5D+%5Cend%7Baligned%7D+%5Cquad%5Cquad+%284%29++&bg=ffffff&fg=000&s=2&c=20201002)





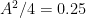









![P_x [f] = X[f] X^\ast [f]](https://s0.wp.com/latex.php?latex=P_x+%5Bf%5D+%3D+X%5Bf%5D+X%5E%5Cast+%5Bf%5D++&bg=ffffff&fg=000&s=2&c=20201002)














